本文主要是介绍数据结构——lesson4带头双向循环链表实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言✨✨
💥个人主页:大耳朵土土垚-CSDN博客
💥 所属专栏:数据结构学习笔记
💥双链表与单链表的区分:单链表介绍与实现
💥对于malloc函数有疑问的:动态内存函数介绍
感谢大家的观看与支持🌹🌹🌹
有问题可以写在评论区或者私信我哦~

目录
前言✨✨
一、💥💥什么是带头双向循环链表?
二、🥳🥳带头双向循环链表的实现
1 .搭建链表基础
2.从内存中开辟一个节点
3. 创建返回链表的头结点
4.双向链表销毁
5.双向链表打印
6.双向链表尾插
7.双向链表尾删
8.双向链表头插
9.双向链表头删
10.双向链表查找
11.双向链表在pos的前面进行插入
12.双向链表删除pos位置的节点
三、💫💫拓展
四、🎉🎉结言
一、💥💥什么是带头双向循环链表?
带头双向循环链表(Doubly Circular Linked List with a Head)是一种链表数据结构,它具有以下特点:
1.头节点:带头双向循环链表包含一个头节点,它位于链表的起始位置,并且不存储实际数据。头节点的前驱指针指向尾节点,头节点的后继指针指向第一个实际数据节点。
2.循环连接:尾节点的后继指针指向头节点,而头节点的前驱指针指向尾节点,将链表形成一个循环连接的闭环。这样可以使链表在遍历时可以无限循环,方便实现循环操作。
3.双向连接:每个节点都有一个前驱指针和一个后继指针,使得节点可以向前和向后遍历。前驱指针指向前一个节点,后继指针指向后一个节点。
总结:带头双向循环链表可以支持在链表的任意位置进行插入和删除操作,并且可以实现正向和反向的循环遍历。通过循环连接的特性,链表可以在连续的循环中遍历所有节点,使得链表的操作更加灵活和高效。
如下图所示:
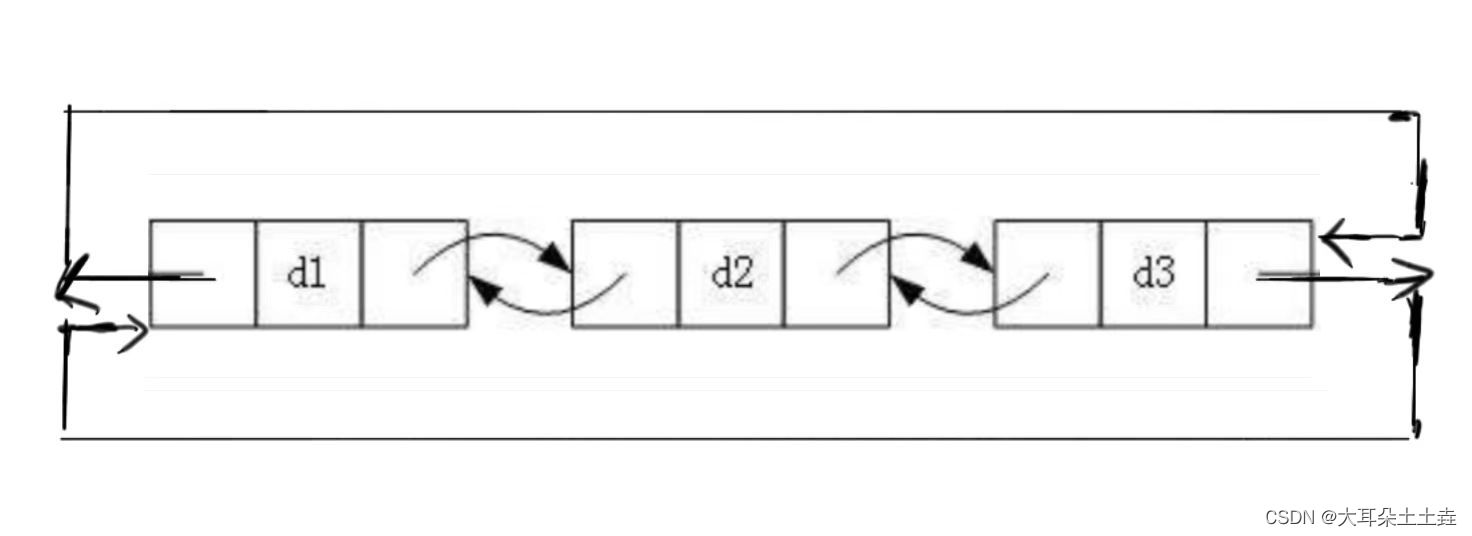
结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
二、🥳🥳带头双向循环链表的实现
1 .搭建链表基础
带头双向循环链表需要三个变量,两个存放指向前后节点的指针,另一个存放数据
// 带头+双向+循环链表增删查改实现
typedef int LTDataType;
typedef struct ListNode
{LTDataType data;//存放数据struct ListNode* next;//指向下一个节点struct ListNode* prev;//指向上一个节点
}ListNode;2.从内存中开辟一个节点
使用malloc函数开辟节点
//从内存中开辟一个节点
ListNode* BuyNode(LTDataType x)
{ListNode* buynode = (ListNode*)malloc(sizeof(struct ListNode));if (buynode == NULL)//开辟失败{perror("malloc fail");}buynode->data = x;buynode->next = NULL;buynode->prev = NULL;}
3. 创建返回链表的头结点
开始时头节点两个指针都指向自己
//创建返回链表的头结点.
ListNode* ListCreate()
{ListNode* head = BuyNode(-1);//这里将头节点数据设为-1,任意数都可以head->next = head;head->prev = head;return head;
}
4.双向链表销毁
malloc开辟空间后要使用free销毁内存空间,防止内存泄漏
// 双向链表销毁
void ListDestory(ListNode* pHead)
{assert(pHead);ListNode* cur = pHead->next;//头节点最后销毁while (cur != pHead)//循环一遍{ListNode* next = cur->next;//保存下一个节点,防止丢失free(cur);//销毁节点cur = next;}free(pHead);//销毁头节点
}5.双向链表打印
//双向链表打印
void ListPrint(ListNode* pHead)
{assert(pHead);if (pHead->next == pHead)//没有节点的情况,也可以不考虑{printf("pHead<=>pHead");return;}//有节点的情况printf("pHead<=>");//先打印pHeadListNode* cur = pHead->next;while (cur != pHead){printf("%d<=>", cur->data);cur = cur->next;}printf("pHead");//因为最后也是指向pHead
}
没有节点情况打印如下:
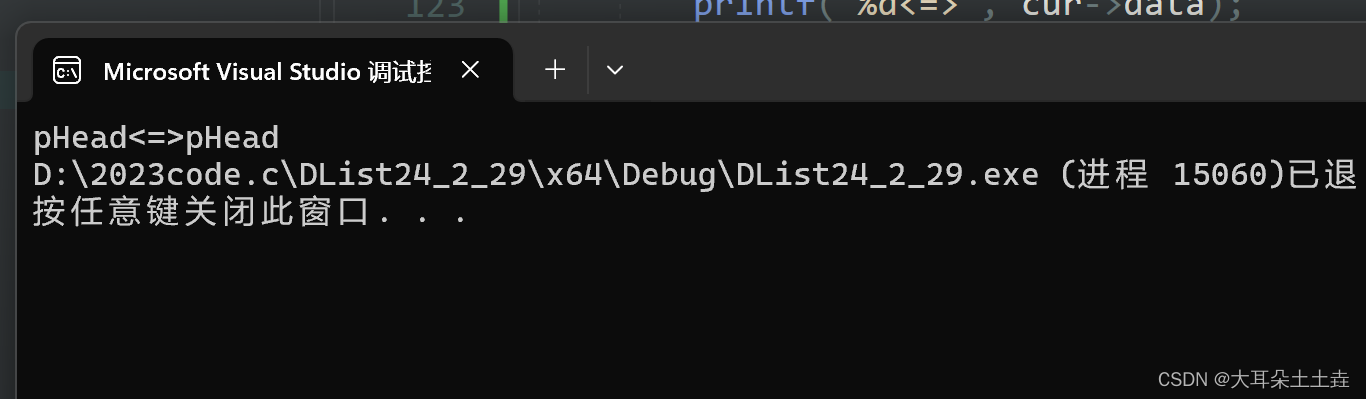
6.双向链表尾插
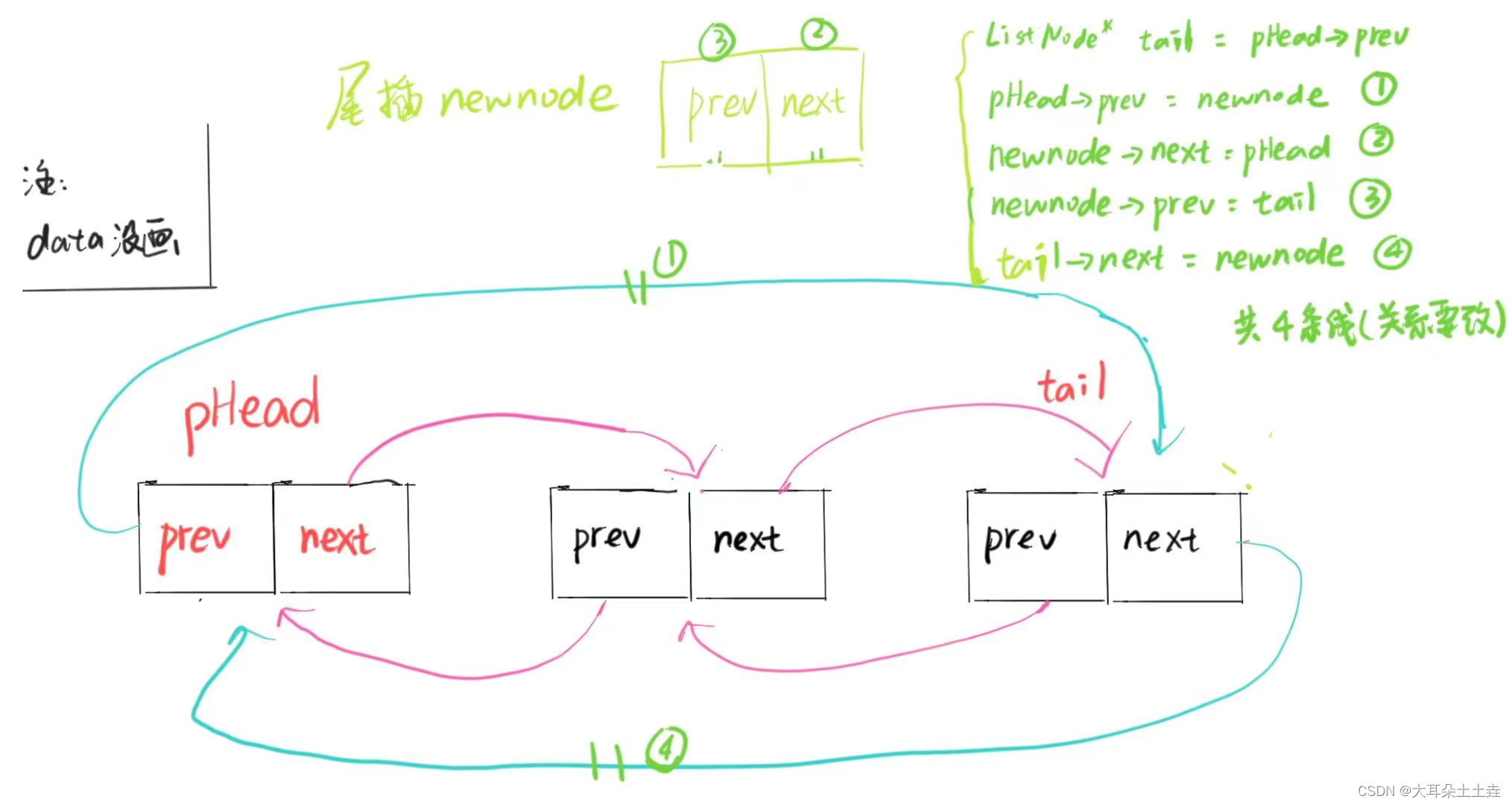
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{assert(pHead);//找尾节点,保存原来的尾//尾节点就是pHead->prevListNode* tail = pHead->prev;//开辟新节点ListNode* newnode = BuyNode(x);//尾插pHead->prev = newnode;newnode->next = pHead;newnode->prev = tail;tail->next = newnode;}
结果如下:

7.双向链表尾删
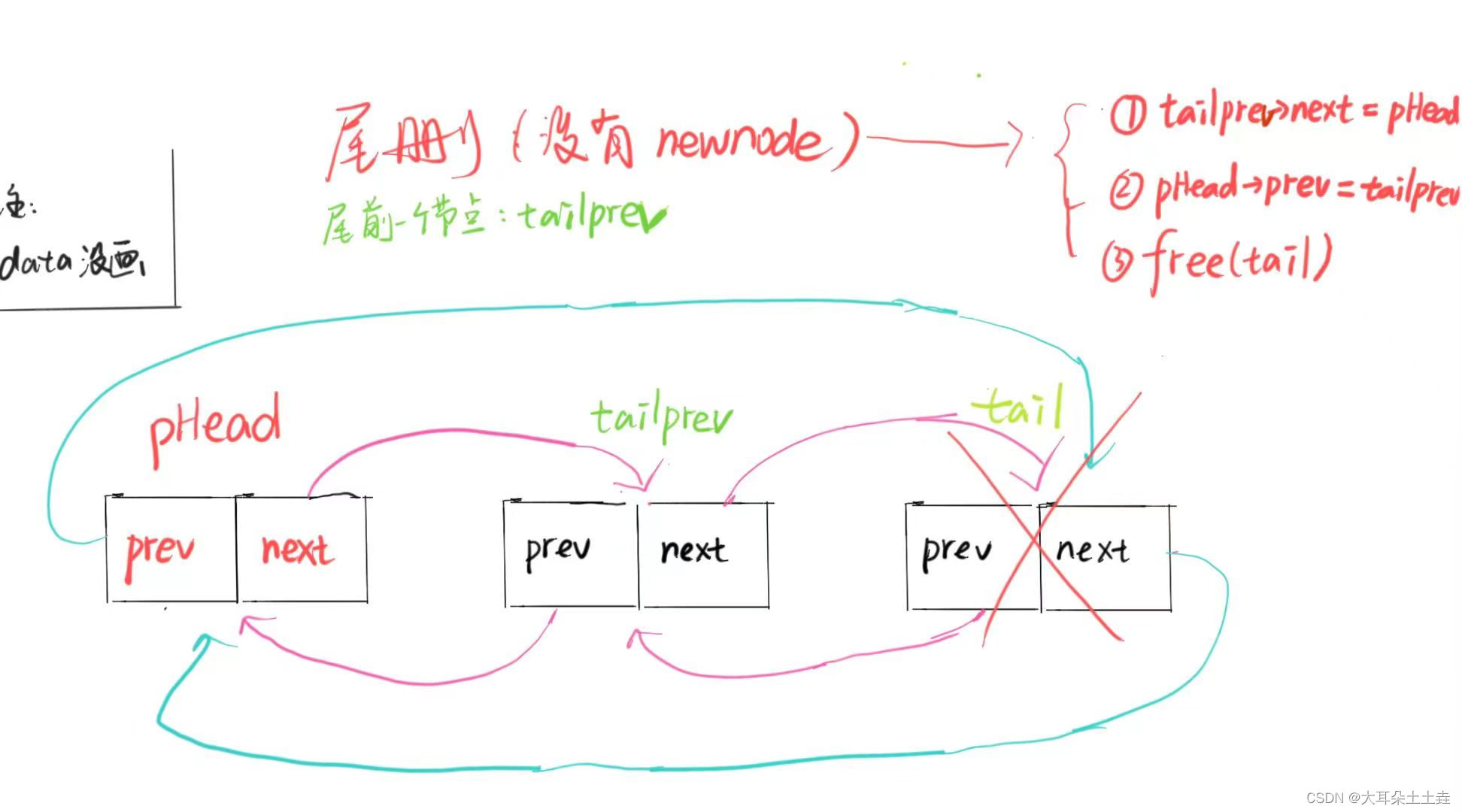
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{assert(pHead);//没有节点不能尾删,头节点pHead不算if (pHead->next == pHead){printf("没有添加节点\n");return;}//找尾节点,以及尾节点的前一个节点ListNode* tail = pHead->prev;ListNode* tailprev = tail->prev;//尾删tailprev->next = pHead;pHead->prev = tailprev;free(tail);//释放内存空间
}结果如下:
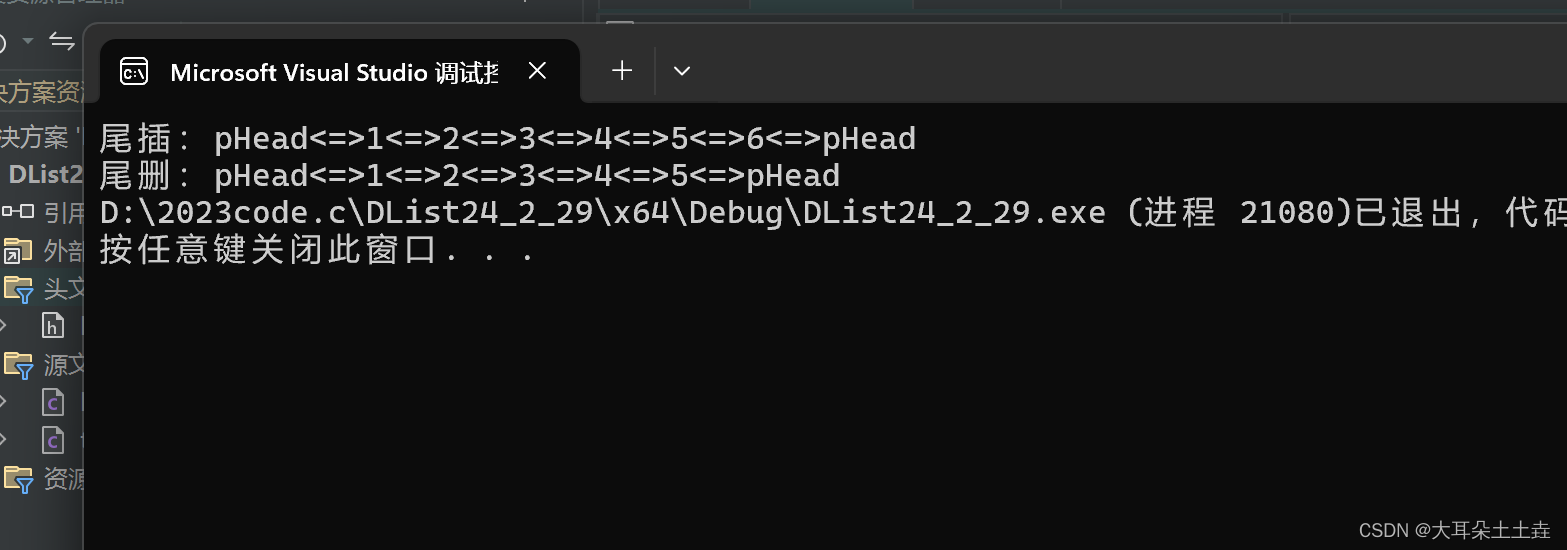
8.双向链表头插
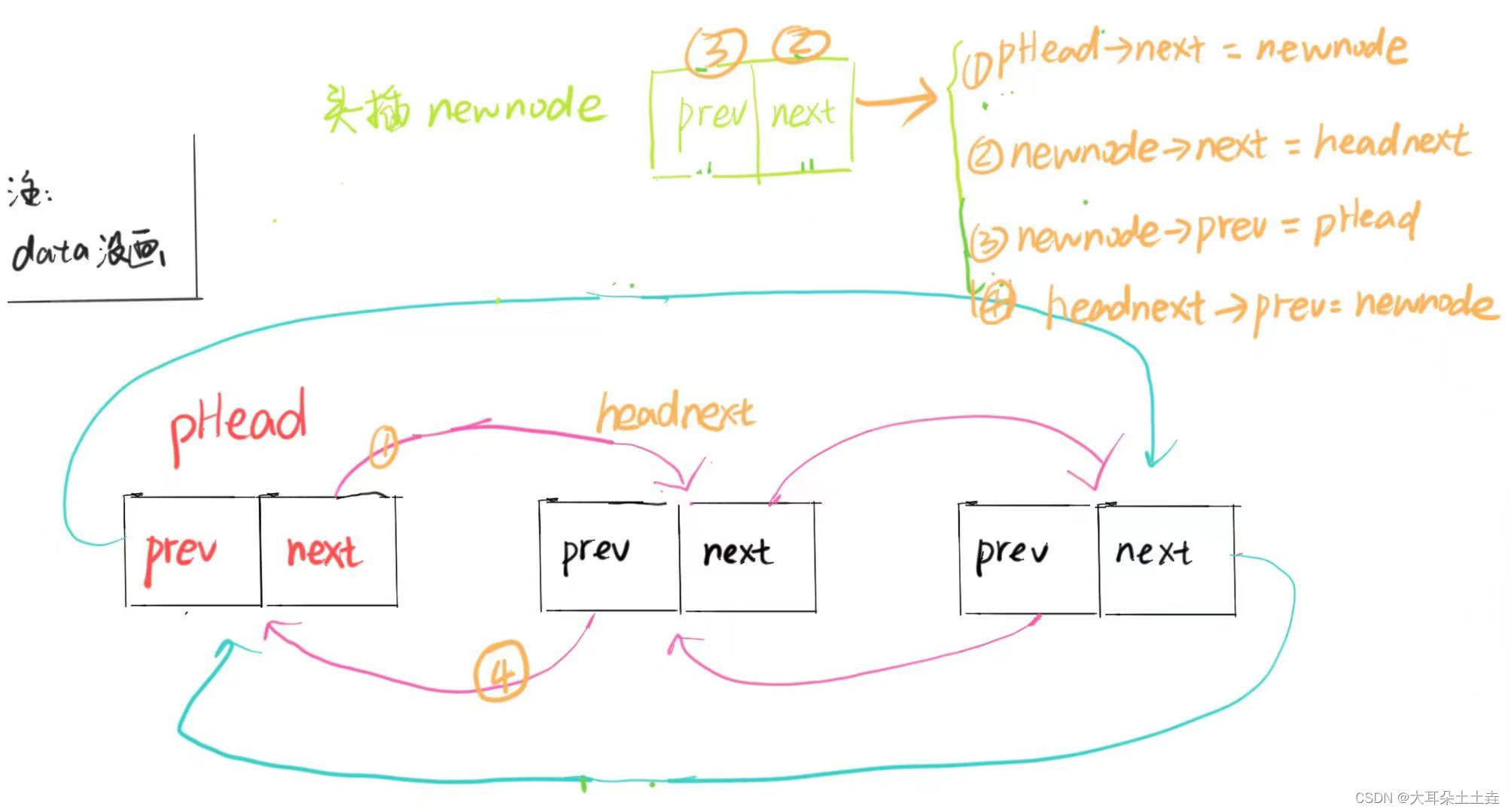
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{assert(pHead);//找头以外的第一个节点ListNode* headnext = pHead->next;//创建新节点ListNode* newnode = BuyNode(x);//头插pHead->next = newnode;newnode->next = headnext;newnode->prev = pHead;headnext->prev = newnode;
}
结果如下:
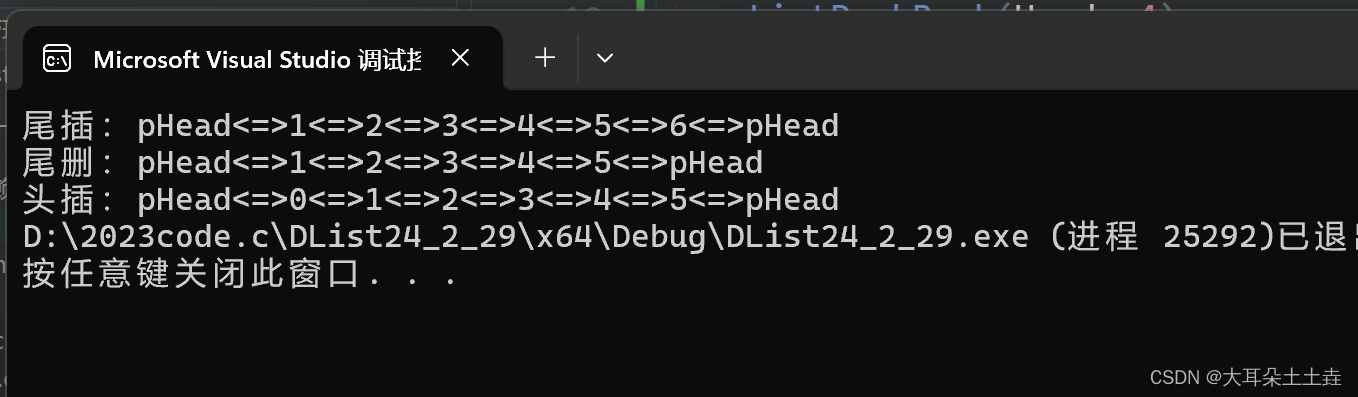
9.双向链表头删
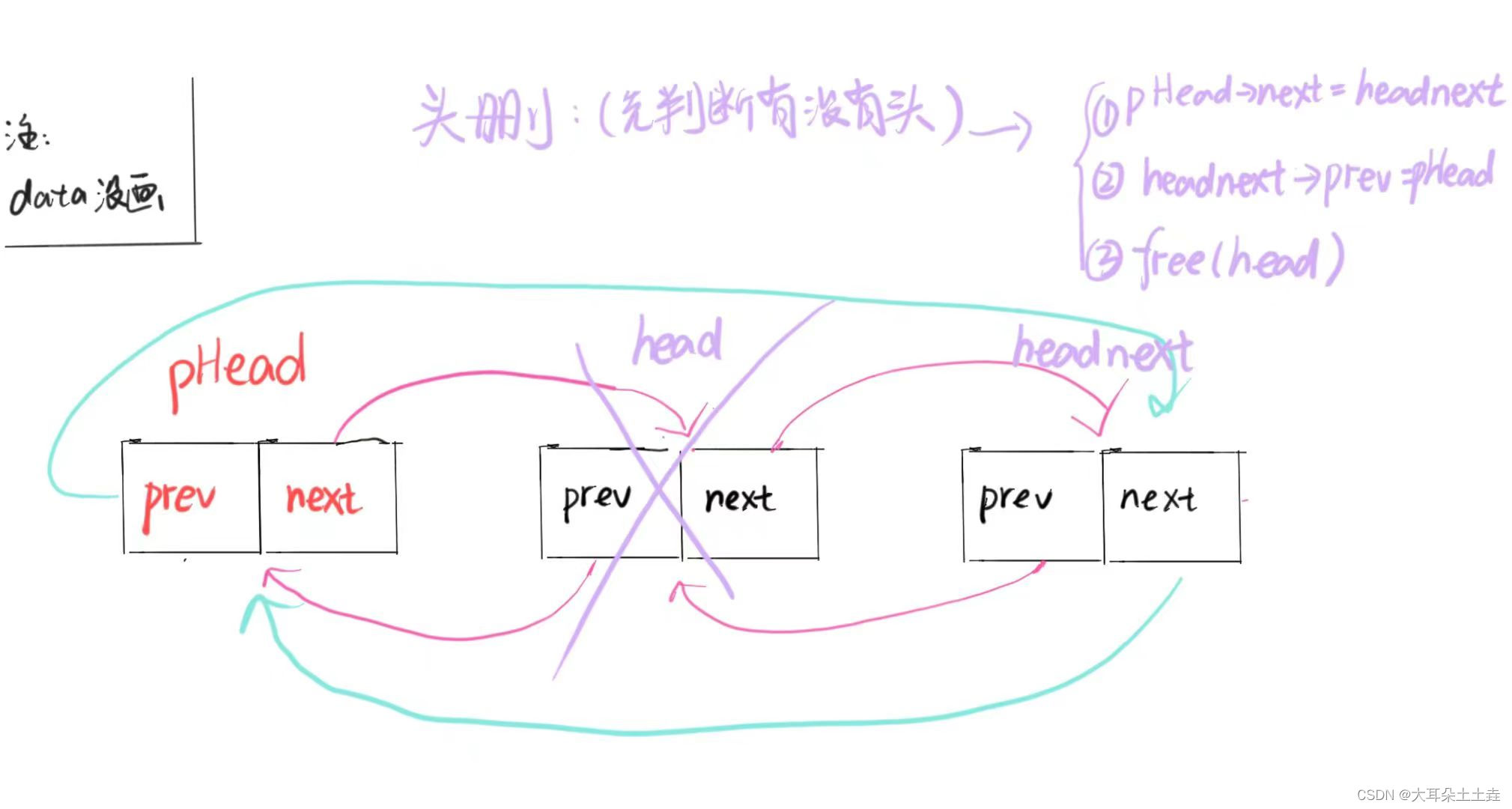
// 双向链表头删
void ListPopFront(ListNode* pHead)
{assert(pHead);//判断有没有节点,头节点pHead除外if (pHead->next == pHead){printf("没有添加节点\n");return;}//有节点//找头节点以及头节点的下一个节点ListNode* head = pHead->next;ListNode* headnext = head->next;//头删pHead->next = headnext;headnext->prev = pHead;free(head);//释放内存空间
}
结果如下:
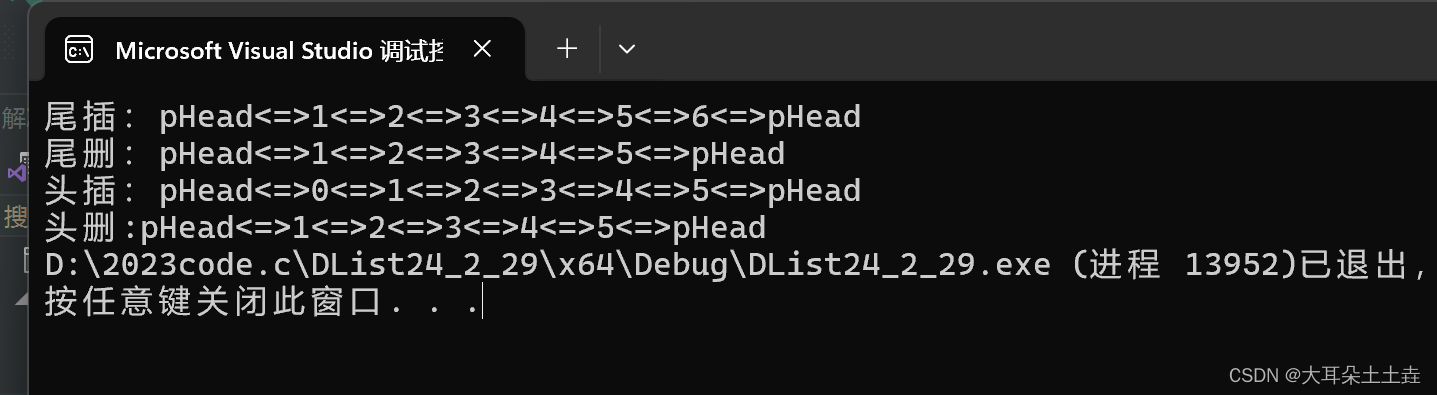
10.双向链表查找
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{assert(pHead);//判断有无节点if (pHead->next == pHead){printf("没有添加节点\n");return;}ListNode* cur = pHead->next;//遍历查找while (cur){if (cur->data == x){return cur;//找到返回地址}cur = cur->next;}
}结果如下:
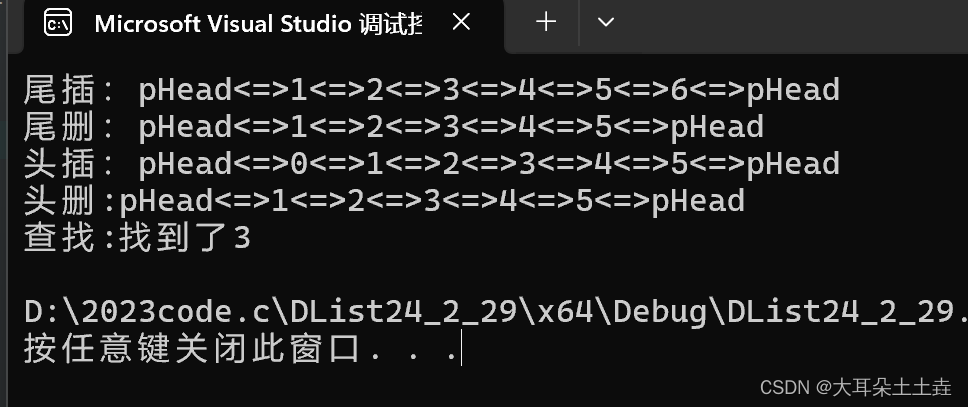
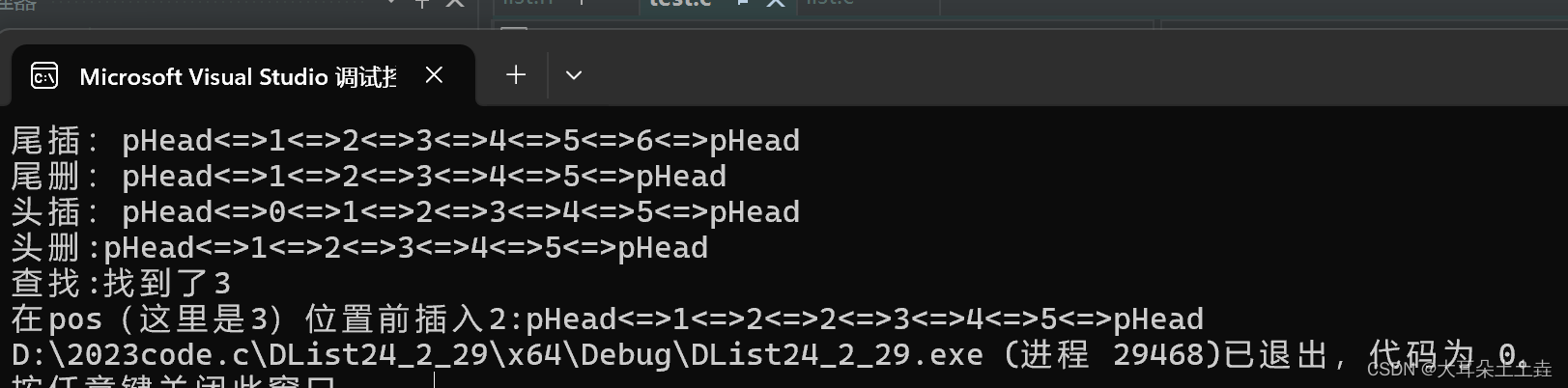
11.双向链表在pos的前面进行插入
在pos位置前面插入原理和头插尾插相似
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x)
{assert(pos);//找到pos前一个节点ListNode* posprev = pos->prev;//创建新节点ListNode* newnode = BuyNode(x);//在pos前插入posprev->next = newnode;newnode->next = pos;newnode->prev = posprev;pos->prev = newnode;}结果如下:
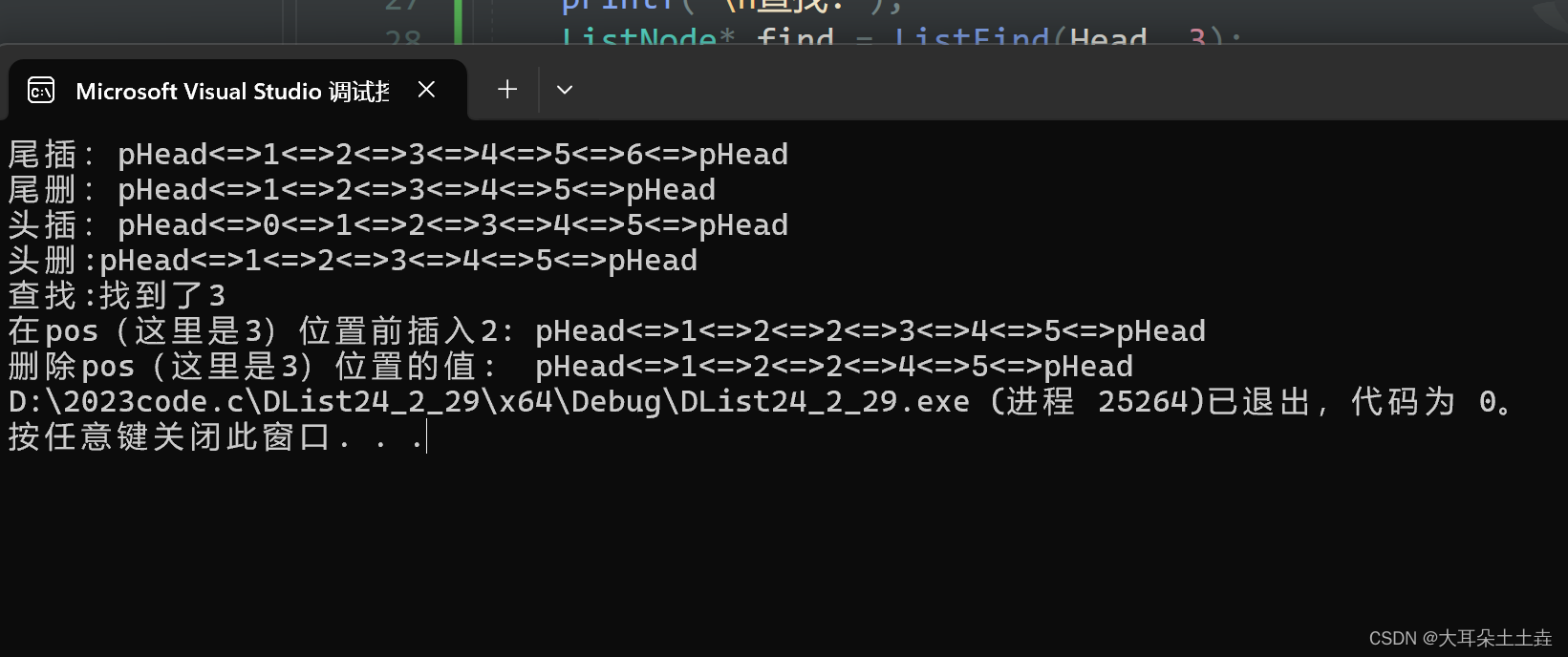
12.双向链表删除pos位置的节点
在pos位置删除原理和头删尾删相似
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{assert(pos);//找到pos前一个节点ListNode* posprev = pos->prev;//找打pos后一个节点ListNode* posnext = pos->next;//删除pos位置节点posprev->next = posnext;posnext->prev = posprev;free(pos);//释放内存空间}结果如下:
三、💫💫拓展
思考:在pos之前插入与头插尾插是否有关?
在pos位置删除与头删尾删是否相似?
我们发现pos位置前插入函数代码似乎可以复用在头插尾插;
pos位置删除函数代码似乎可以复用在头删尾删;
下面我们一起来实现
1.尾插头插
//尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{assert(pHead);//找尾节点,保存原来的尾//尾节点就是pHead->prev//ListNode* tail = pHead->prev;开辟新节点//ListNode* newnode = BuyNode(x);尾插//pHead->prev = newnode;//newnode->next = pHead;//newnode->prev = tail;//tail->next = newnode;ListInsert(pHead, x);}//头插
void ListPushFront(ListNode* pHead, LTDataType x)
{assert(pHead);//找头以外的第一个节点//ListNode* headnext = pHead->next;创建新节点//ListNode* newnode = BuyNode(x);头插//pHead->next = newnode;//newnode->next = headnext;//newnode->prev = pHead;//headnext->prev = newnode;ListInsert(pHead->next, x);}2.尾删,头删
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{assert(pHead);//没有节点不能尾删,头节点pHead不算if (pHead->next == pHead){printf("没有添加节点\n");return;}找尾节点,以及尾节点的前一个节点//ListNode* tail = pHead->prev;//ListNode* tailprev = tail->prev;尾删//tailprev->next = pHead;//pHead->prev = tailprev;//free(tail);//释放内存空间ListErase(pHead->prev);
}// 双向链表头删
void ListPopFront(ListNode* pHead)
{assert(pHead);//判断有没有节点,头节点pHead除外if (pHead->next == pHead){printf("没有添加节点\n");return;}有节点找头节点以及头节点的下一个节点//ListNode* head = pHead->next;//ListNode* headnext = head->next;头删//pHead->next = headnext;//headnext->prev = pHead;//free(head);//释放内存空间ListErase(pHead->next);
}
运行结果依然不受影响:
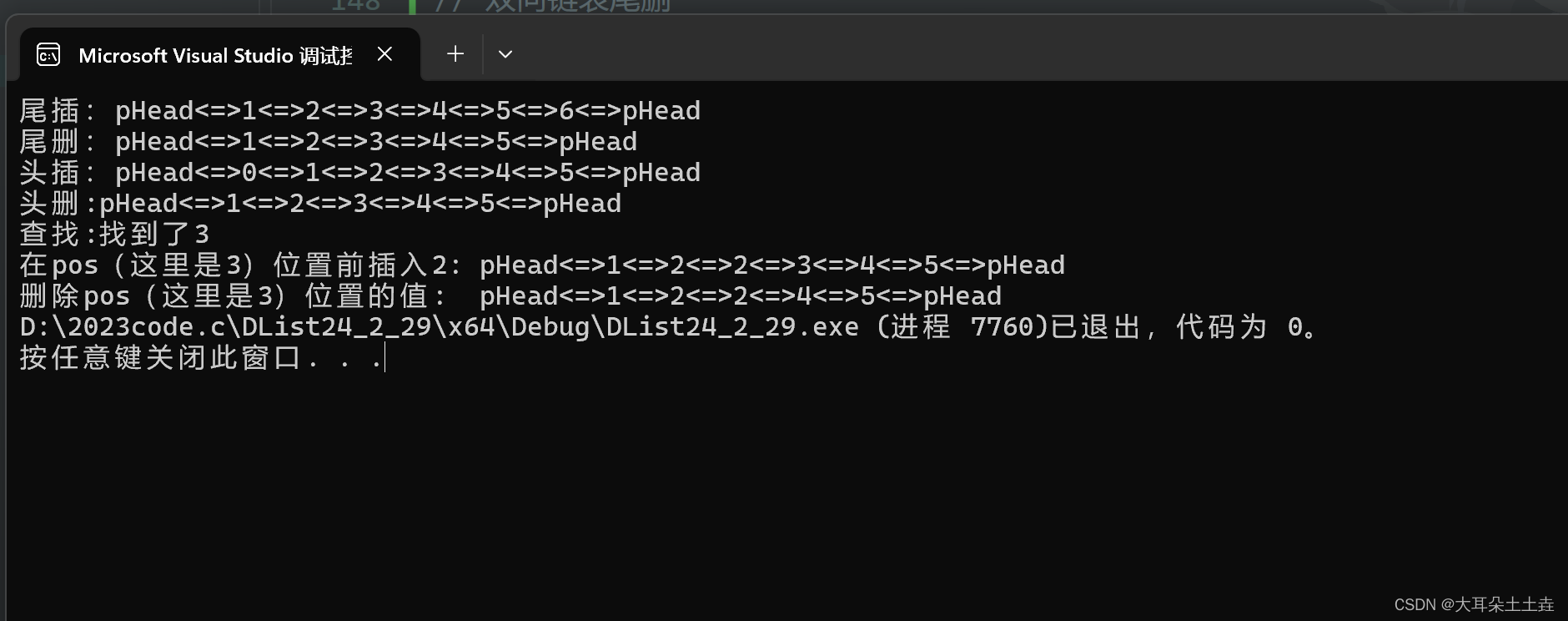
四、🎉🎉结言
我们通过上面的学习发现,相似的代码的重复利用可以大大减少我们写代码的时间与精力,提高我们工作学习的效率;双向链表尽管结构较单链表复杂,但其实现却比单链表简单得多,相信大家对此都深有体会,此外数据结构的题目我们可以通过画图来很好的获得思路与接替步骤,以上就是带头双向循环链表的相关知识啦~完结撒花~🎉🎉🌹🌹🌹
这篇关于数据结构——lesson4带头双向循环链表实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






