本文主要是介绍Mysql如何快速插入千万条数据实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一.创建数据库
二.创建表
1.创建 dept表
2.创建emp表
三.设置参数
四.创建函数
1.随机产生字符串
2.随机产生部门编号
五.创建存储过程
1. emp表存储过程
2.dept表存储过程
六.执行
1.先执行十条
2.查看数据
3.执行百万插入
一.创建数据库
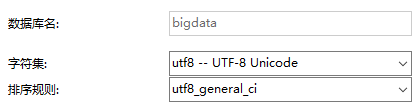
二.创建表
1.创建 dept表
CREATE TABLE `dept` (`id` int(11) NOT NULL,`deptno` mediumint(9) DEFAULT NULL,`dname` varchar(20) DEFAULT NULL,`loc` varchar(13) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.创建emp表
CREATE TABLE `emp` (`id` int(11) NOT NULL,`empon` mediumint(9) DEFAULT NULL COMMENT '编号',`ename` varchar(20) DEFAULT NULL,`job` varchar(9) DEFAULT NULL,`mgr` mediumint(9) DEFAULT NULL COMMENT '上级编号',`hirdate` datetime DEFAULT NULL COMMENT '入职时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '薪水',`comm` decimal(7,2) DEFAULT NULL COMMENT '红利',`deptno` mediumint(9) DEFAULT NULL COMMENT '部门编号',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;三.设置参数
SHOW VARIABLES LIKE 'log_bin_trust_function_creators';
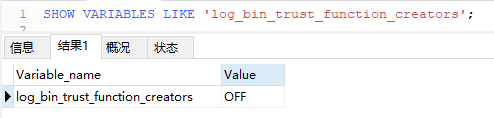
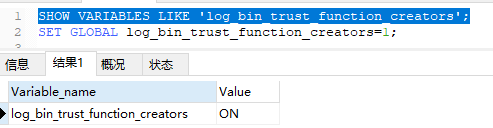
默认关闭. 需要设置为1。因为表中设置 mediumint 字段 创建函数可能会报错
SET GLOBAL log_bin_trust_function_creators=1;
四.创建函数
1.随机产生字符串
DELIMITER $
CREATE FUNCTION RAND_STR(n INT) RETURNS VARCHAR(255)
BEGINDECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwsyzABCDEFGHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT '';DECLARE i INT DEFAULT 0;WHILE i< n DO SET return_str =COUCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));SET i= i+1;END WHILE;RETURN return_str;
END $
2.随机产生部门编号
DELIMITER $
CREATE FUNCTION RAND_num() RETURNS INT(5)
BEGINDECLARE i INT DEFAULT 0; SET i= FLOOR(100+RAND()*10);RETURN i;
END $五.创建存储过程
1. emp表存储过程
DELIMITER $
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGINDECLARE i INT DEFAULT 0;SET autocommit = 0;REPEAT #重复SET i = i + 1;INSERT INTO emp(empon,ename,job,mgr,hiredate,sal,comm,depton) VALUES ((START+i),RAND_STR(6),'SALESMAN',0001,CURDATE(),2000,400,RAND_num());UNTIL i = max_numEND REPEAT;COMMIT;
END $2.dept表存储过程
DELIMITER $
CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
BEGINDECLARE i INT DEFAULT 0;SET autocommit = 0;REPEAT #重复SET i = i + 1;INSERT INTO dept(deptno,dname,loc) VALUES ((START+i),RAND_STR(10),RAND_STR(8));UNTIL i = max_numEND REPEAT;COMMIT;
END $六.执行
1.先执行十条
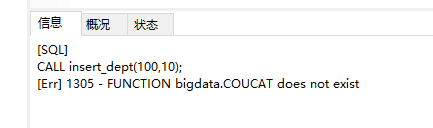
这个错误是一个小坑 发现了吗 我之前留下的 根据提示 去排查吧
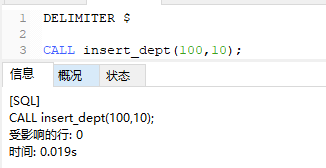
执行成功!
2.查看数据
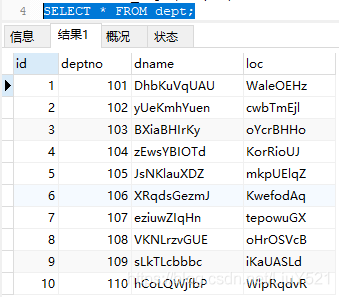
重头戏来喽! 一次性干他百万条数据 赌一把 看看会不会玩崩了
3.执行百万插入
CALL insert_dept(10001,1000000);
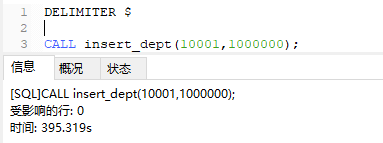
400s跑百万数据 一秒2500条 我这配置太垃圾 以前测试的是一秒一万 最好50W跑一次
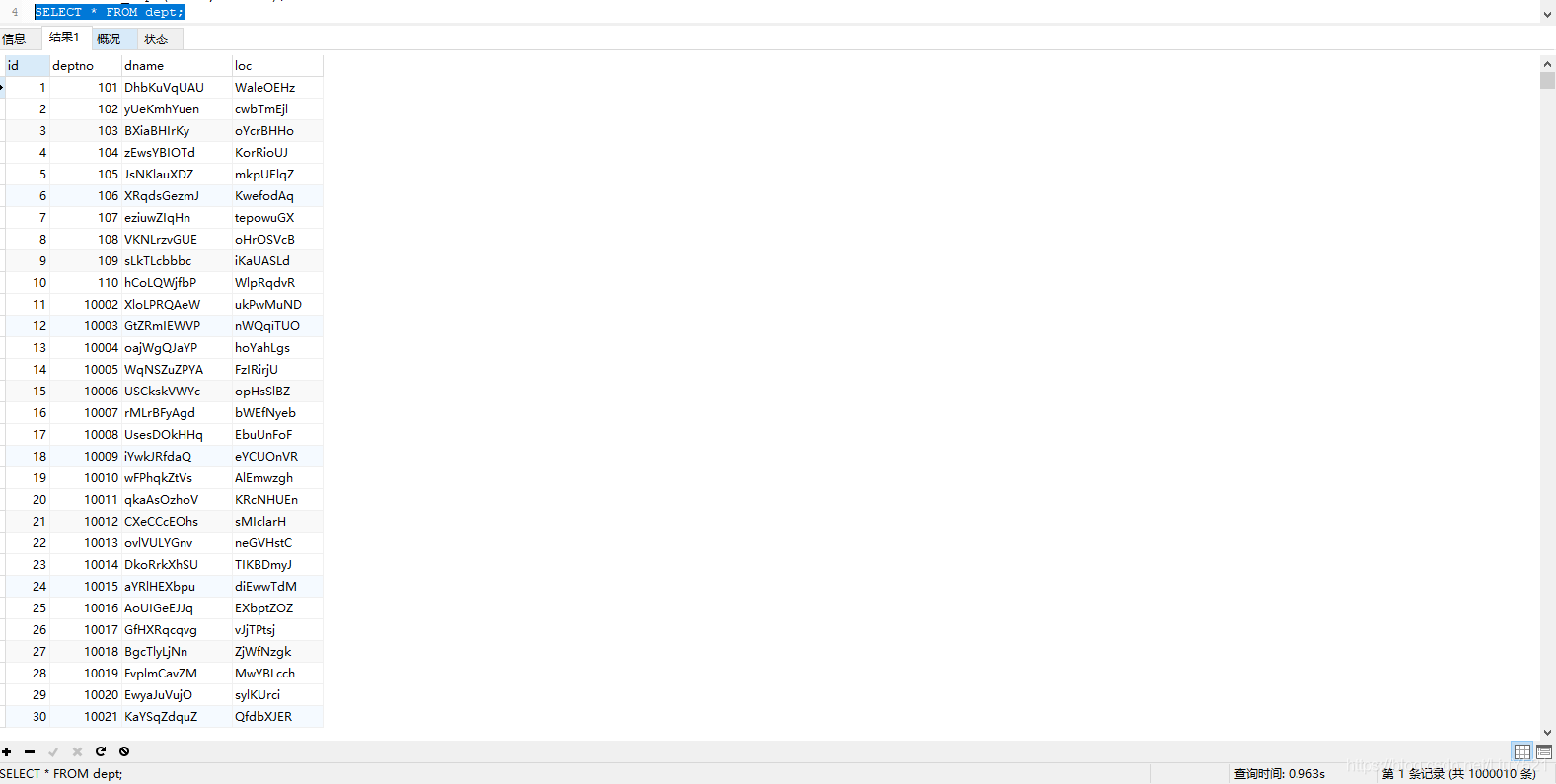

欧克 睡觉
这篇关于Mysql如何快速插入千万条数据实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





