本文主要是介绍大数据之Trino高可用方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系统架构
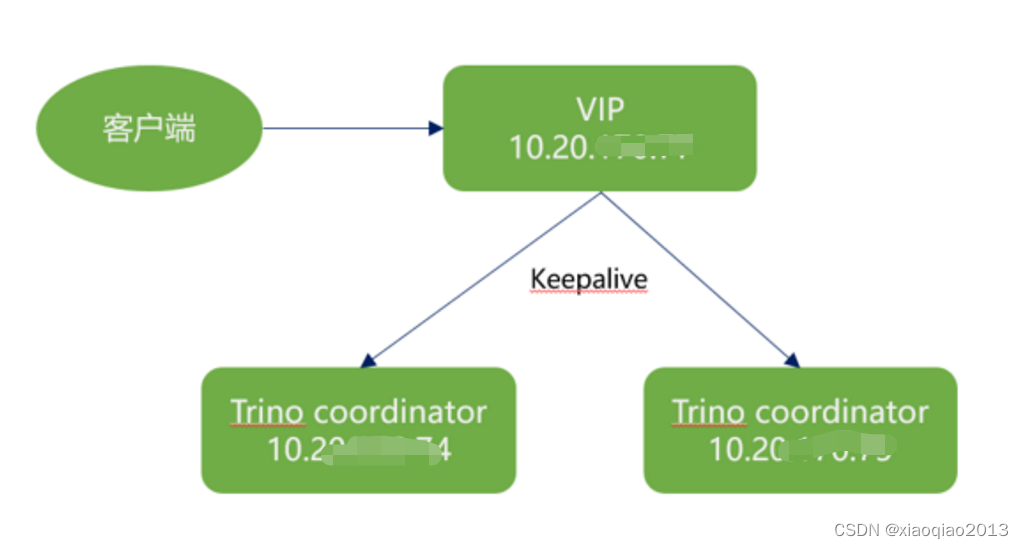
2、keepalive安装
2.1、安装(2台机器)
yum install -y keepalived
useradd keepalived_script
echo keepalived_script | passwd --stdin keepalived_script
2.2、编写coordinator服务存活检测脚本(两台机器都需要)
vim /usr/bin/check_trino_alive.sh
#!/bin/shPATH=/bin:/sbin:/usr/bin:/usr/sbin#port_test=`nc -z -v localhost 18080|grep succeeded -c`;
port_test=`ss -nlp | grep 18080 | wc -l`;if [ $port_test -eq 0 ]thenecho 'trino coordinator is died'systemctl stop keepalived.serviceexit 1
elseexit 0
fichmod +x /usr/bin/check_trino_alive.sh
2.3、机器trino coordinator1的配置
[root@hdpapcuat01v ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalivedvrrp_script check_trino_alive {script "/usr/bin/check_trino_alive.sh"interval 3weight -10
}global_defs {router_id LVS_TRINO #运行keepalived机器的一个标识#script_user root#enable_script_security
}vrrp_instance VI_1 {interface eth0 #设置实例绑定的网卡state BACKUP #指定哪个为master,哪个为backupvirtual_router_id 92 #VPID标记,主备必须一样mcast_src_ip 127.0.0.1priority 170 #优先级,高优先级竞选为master#vrrp_unicast_bind 127.0.0.1#vrrp_unicast_peer 127.0.0.2authentication {auth_type PASS #认证方式auth_pass afafa12384CDEad #认证密码}virtual_ipaddress {## 设置VIP,必须是同一网段虚拟IP127.0.0.3}track_script {check_trino_alive #trino存活检查}}
2.4、机器trino coordinator2的配置
[trino@localhost1 trino]$ cat /etc/keepalived/keepalived.conf
! Configuration File for keepalivedvrrp_script check_trino_alive {script "/usr/bin/check_trino_alive.sh"interval 3weight -10
}global_defs {router_id LVS_TRINO #运行keepalived机器的一个标识#script_user root#enable_script_security
}vrrp_instance VI_1 {interface eth0 #设置实例绑定的网卡state BACKUP #指定哪个为master,哪个为backupvirtual_router_id 92 #VPID标记,主备必须一样mcast_src_ip 127.0.0.2priority 170 #优先级,高优先级竞选为master#vrrp_unicast_bind 127.0.0.1#vrrp_unicast_peer 127.0.0.2authentication {auth_type PASS #认证方式auth_pass afafa12384CDEad #认证密码}virtual_ipaddress {## 设置VIP,必须是同一网段虚拟IP127.0.0.3}track_script {check_trino_alive #trino存活检查}} [root@localhost1 etc]# chmod +x /etc/keepalived/keepalived.conf
2.5、重启 keepalive 生效(两台机器都执行)
systemctl restart keepalived.service
systemctl status keepalived.service
2.6、验证
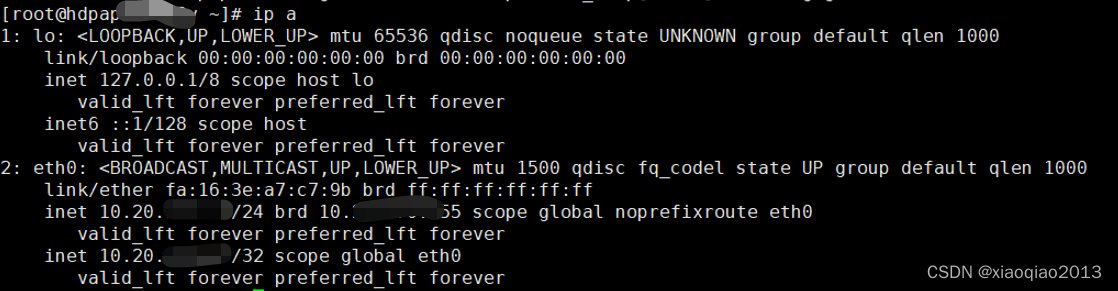
3、配置Trino
3.1、coordinator1
vi config.properties
# 该节点是否作为coordinator
coordinator=true
# coordinator是否同时作为worker节点
node-scheduler.include-coordinator=false
# http连接端口
http-server.http.port=18080
#每个查询可以使用的最大分布式内存量。
query.max-memory=38GB
#查询可在任何一台计算机上使用的最大用户内存量
query.max-memory-per-node=16GB
memory.heap-headroom-per-node=12GB
# 服务发现的地址
discovery.uri=http://localhostvip.daemon.com:18080
3.2、coordinator2
vi config.properties
# 该节点是否作为coordinator
coordinator=true
# coordinator是否同时作为worker节点
node-scheduler.include-coordinator=false
# http连接端口
http-server.http.port=18080
#每个查询可以使用的最大分布式内存量。
query.max-memory=38GB
#查询可在任何一台计算机上使用的最大用户内存量
query.max-memory-per-node=16GB
memory.heap-headroom-per-node=12GB
# 服务发现的地址
discovery.uri=http://localhostvip.daemon.com:18080
3.3、其他worker节点
vi config.properties
# 该节点是否作为coordinator
coordinator=false
# coordinator是否同时作为worker节点
node-scheduler.include-coordinator=true
# http连接端口http-server.http.port=18080
#每个查询可以使用的最大分布式内存量。
query.max-memory=38GB
#查询可在任何一台计算机上使用的最大用户内存量
query.max-memory-per-node=16GB
memory.heap-headroom-per-node=12GB# 服务发现的地址discovery.uri=http://localhostvip.daemon.com:18080
3.4、启动
/opt/apache-hadoop/trino/bin/launcher restart
/opt/apache-hadoop/trino/bin/launcher start
/opt/apache-hadoop/trino/bin/launcher status
3.5、验证
停止各个节点测试
| 节点 | 类型 | 服务状态 | |
|---|---|---|---|
| 127.0.0.1 | 节点1 | 停止 | 正常 |
| 127.0.0.2 | 节点2 | 正常 | 停止 |
| 127.0.0.3 | VIP | 正常 | 正常 |
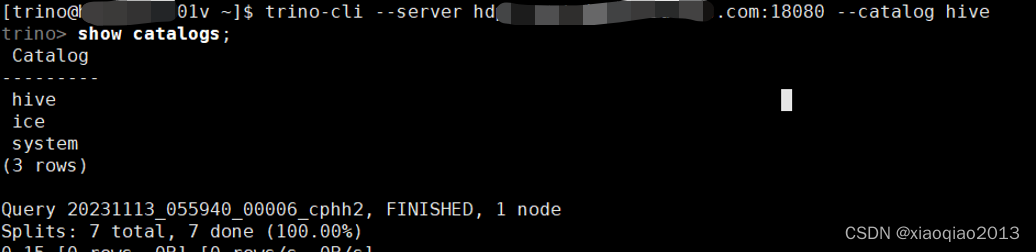
Client访问
[trino@localhost ~]$ trino-cli --server localhostvip.daemon.com:18080 --catalog hive
这篇关于大数据之Trino高可用方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







