本文主要是介绍第四篇 FastAI中的数据增强,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇博客介绍了如何使用Fast AI数据模块(Data Block),便捷地构建Fast AI模型所需的数据包(Data Bunch)。在将图像数据灌入模型之前,往往需要对之进行随机变换,即做数据增强(Data Augmentation)。这可以视为一种在数据层面的正则化(也就是人为地引入一些随机扰动,避免学习器过分关注训练集的特有性质,以免产生过拟合)。本篇博客将介绍Fast AI中的数据增强模块,相关文档见文档链接。
一、Transform基类
Fast AI提供了许多图像变换函数(会在本博客的后面提到),使用这些变换函数,可以直接对图像进行变换。同时,为了给这些变换函数提供数据增强时的随机机制,Fast AI提供了一个封装类—Transform类(定义在fastai/vision/image.py文件中),该类的功能主要还包括对变换函数添加一些共有特性:如变换函数的优先级(order)、包装器的名称(变量为_wrap,对应于Image类中的相应函数,用于对变换函数调用之后的结果做进一步的操作)等。当使用该类封装的变换函数时,如果按照正常的变换函数传入相关参数,则效果与直接调用该变换函数一致,此时没有随机性因素。以Fast AI库提供的用于改变图像明暗的brightness类为例:
brightness_func = brightness(change=0.2, p=0.5)
img = open_image(img_file)
y = brightness_func(img, change=0.2)注意:在使用Transform类包装的变换函数时直接作用于图像数据时,要按照原变换函数的签名提供完整的参数列表,如上例中change=0.2。
如果使用img.apply_tfms()方式调用,则此时会存在两种随机机制:当被标注为uniform的参数为固定值时,则按照提供的p值,以概率p进行变换;当被标注为uniform的参数为区间时,则变换以概率p发生,并且该参数在所提供的区间内随机选择。
二、变换函数
相应代码见fastai/vision/transform.py
| 函数签名 | 说明 |
|---|---|
brightness(x, change: uniform) → Image :: TfmLighting | 改变图像明暗,通过对图像的logit pixel进行加减常量实现。当change=0.5时,图像无变化;当change=1时,图像会变换为白色;当change=0时,图像会变换为白色。 |
contrast(x, scale:log_uniform) → Image :: TfmLighting | 调整对比度,通过对图像的logit pixel乘上一个常量实现。 当scale=0时,会将图像转换为灰色,当scale>1会增强图像的对比度(即明暗像素的差异更大);当scale=1时,不调整对比度。 |
crop(x, size, row_pct:uniform=0.5, col_pct:uniform=0.5) → Image :: TfmPixel | 图像裁剪,其中(row_pct, col_pct)限定了裁剪框锚点的位置,以归一化的比例进行表示。 |
crop_pad(x, size, padding_mode='reflection', row_pct:uniform=0.5, col_pct:uniform=0.5) → Image :: TfmCrop | 类似于crop(),不过裁剪框的大小可以超出图像范围,填充方法通过padding_mode指定,可选为reflection、zeros、border。 |
dihedral(x, k:partial(uniform_int, 0, 7)) → Image :: TfmPixel | 镜像翻转与旋转90°。 |
flip_lr(x) → Image :: TfmPixel | 水平翻转。 |
jitter(c, magnitude:uniform) → Image :: TfmCoord | 邻域像素替换, 邻域范围由magnitude限定。 |
perspective_warp(c, magnitude:partial(uniform, size=8)=0, invert=False) → Image :: TfmCoord | 透视变换,其中manigtude为8元素集,指定了将四个角的归一化坐标变换的幅度。默认填充方法是reflection。 |
Image.resize(self, size:Union[int,TensorImageSize])->'Image' | 图像缩放,使用的是torch中相应的方法。对图像而言,size为一个整数,或者TensorImageSize类型·(3, H, W),默认使用SQUISH方法。在使用数据模块的API构建数据包时,可通过设置resize_method来选择处理方式。 |
rotate(degrees:uniform) → Image :: TfmAffine | 图像旋转。 |
rgb_randomize(x, channel:int=None, thresh:float=0.3) → Image :: TfmPixel | 随机化RGB的某一通道,通过thresh限定该通道的最大值。 |
skew(c, direction:uniform_int, magnitude:uniform=0, invert=False) → Image :: TfmCoord | 扭曲,实际是通过perspective_warp()实现的。 |
squish(scale:uniform=1.0, row_pct:uniform=0.5, col_pct:uniform=0.5) → Image :: TfmAffine | 拉伸,scale<1时,为横向拉伸;scale>1时,为纵向拉伸。 |
symmetric_warp(c, magnitude:partial(uniform, size=4)=0, invert=False) → Image :: TfmCoord | 特定的透视变换。 |
tilt(c, direction:uniform_int, magnitude:uniform=0, invert=False) → Image :: TfmCoord | 倾斜。 |
zoom(scale:uniform=1.0, row_pct:uniform=0.5, col_pct:uniform=0.5) → Image :: TfmAffine | 等比例缩放。 |
cutout(x, n_holes:uniform_int=1, length:uniform_int=40) → Image :: TfmPixel | 制造孔洞。 |
三、get_transforms()函数
该函数会返回变换函数的两个列表,一个用于训练集,一个用于验证集。
get_transforms(do_flip:bool=True, # 是否进行水平翻转flip_vert:bool=False, #是否进行垂直翻转 max_rotate:float=10.0, max_zoom:float=1.1, max_lighting:float=0.2, max_warp:float=0.2, p_affine:float=0.75, p_lighting:float=0.75, xtra_tfms:Optional[Collection[Transform]]=None) → Collection[Transform]具体而言,在构建数据包时,按如下方式进行使用:
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=26)或者
tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
data = (ImageList.from_folder(path) # 数据文件的路径 .split_by_folder() # 按比例分割训练集和验证集 .label_from_folder() # 指定类别标签 .transform(tfms, size=32) # 对图像进行变换 .databunch(bs=128) .normalize(imagenet_stats) # 数据归一化)四、一些补充
1. fastai.vision.Image类中的图像数据究竟是以pixel存储的还是以logit存储的?
只能说,当你需要它是pixel时,它就是pixel,即img.px;当你需要它是logit_pixel时,它就是logit_pixel,即img.logit_px。这是通过Image类中的refresh()函数实现的,而每次访问img.data时,总会调用refresh()函数。如果检查到img.logit_px不为None,则可认为logit_px是最新的操作结果,则通过sigmoid函数将其变换为img.px,并置img.logit_px=None;否则返回存储的img.px。另外,需要访问img.logit_px时,若img.logit_px is None,则计算img.px的logit,并存储在img.logit_px中。
2. crop()函数中的锚点位置图示
见下图,这样做的好处是无需判断裁剪框是否超出图像边界。
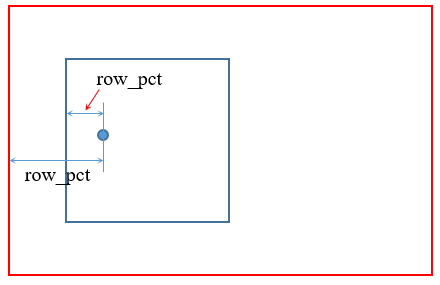
3. dihedral()函数结果图示
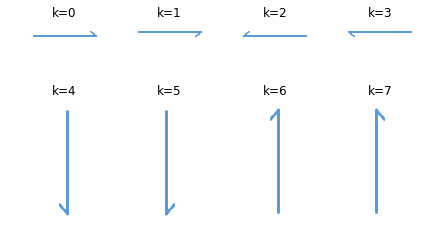
4. 对Image对象的像素坐标的更改
像jitter()这类的标记为TfmCoord的变换函数,会对图像像素坐标进行变换。这一过程是这样完成的:首先生成图像对象每个像素的归一化坐标网格(坐标分布在[-1, 1]),这一值会存储在img.flow属性中;然后对该网格进行变换;在图像像素值获取时,做完logit_px和px的转换后,就依据img.flow对图像进行重采样。这些都是在Image.refresh()函数中实现的。
5. 补全为什么总是reflection
像TfmCoord和TfmAffine类的变换函数,会涉及图像像素的坐标变换,而这些变换都是通过_grid_sample()函数完成的,而_grid_sample()函数的默认补全方法就是reflection。
6. Fast AI的并行处理函数函
数为fastai/core.py里的parrallel,需要传入要执行的函数和参数列表。示例如下(文档链接):
num_cpus() #获取CPU的数目
def my_func(value, index):print("Index: {}, Value: {}".format(index, value)) my_array = [i*2 for i in range(5)]
parallel(my_func, my_array, max_workers=3)这篇关于第四篇 FastAI中的数据增强的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




