本文主要是介绍第三篇 FastAI数据构造API,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇博客介绍了如何调用ImageDataBunch的工厂类方法,生成Fast AI的模型所需的数据包(Data Bunch)。事实上,Fast AI提供了一系列函数接口,使得构建数据包的流程更符合逻辑且更灵活,而前述博客所示的工厂类方法其实也是基于这些API进行构建的。本篇博客将介绍相关的数据类型以及API。
一、Fast AI的数据积木(Data Block)API (文档链接)
DataBunch类的功能就是整合train和valid的数据加载器(即PyTorch里的DataLoader)。而使用Data Block API一步一步构建DataBunch的流程如下图所示:
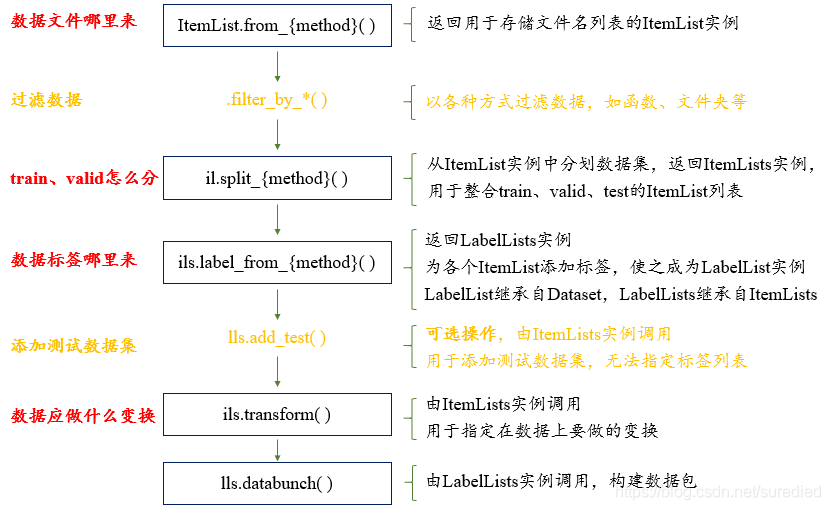
1. 数据列表:ItemList类
ItemList是用于存储数据的列表类(即提供了索引功能)。针对不同的任务以及各类型的标签,Fast AI提供了ItemList的各种子类,其中与视觉应用相关的子类包括:
- CategoryList: 分类问题的类别标签列表
- MultiCategoryList: 多标签问题的多类别标签列表
- FloatList: 回归问题的浮点数标签列表
- ImageList: 图像(标签)列表
- SegmentationLabelList: 分割任务的掩膜标签列表
- ObjectLabelList: 目标检测任务的目标框标签列表
- PointsItemList: 关键点检测任务的点标签列表
ItemList提供了几种生成ItemList实例的工厂类方法:
-
from_folder()工厂类方法@classmethod def from_folder(cls,path:PathOrStr, # 数据目录extensions:Collection[str]=None, # 只获取特定扩展名的文件recurse:bool=True, # 是否进行文件路径的迭代查找include:Optional[Collection[str]]=None, # 指定路径的最后一层的列表processor:PreProcessors=None,presort:Optional[bool]=False, # 是否对文件进行排序**kwargs)->'ItemList' -
from_df()工厂类方法@classmethod def from_df(cls,df:DataFrame,path:PathOrStr='.',cols:IntsOrStrs=0, # 数据所在的列processor:PreProcessors=None, **kwargs)->'ItemList' -
from_csv()工厂类方法@classmethod def from_csv(cls,path:PathOrStr,csv_name:str,cols:IntsOrStrs=0,delimiter:str=None, header:str='infer',processor:PreProcessors=None, **kwargs)->'ItemList'
此外,ItemList还提供了几个用于数据过滤的函数:
- 1.
filter_by_func(func): 按函数返回值是否为真进行筛选。 - 2.
filter_by_folder(include=None, exclude=None): 包含include指定的文件夹,排除exclude指定的文件夹。 - 3.
filter_by_rand(p, seed): 按照一定的比例p筛选数据。
2. 将数据分划为train和valid集
ItemList类提供了若干个用于分划数据集的方法,返回的是一个包含train和valid两个ItemList的ItemLists实例。
split_by_rand_pct(valid_pct:float=0.2, seed:int=None)# 按valid_pct指定的比例进行分划。
split_subsets(train_size:float, valid_size:float, seed=None)# 按train_size、valid_size指定的比例进行抽取
split_by_files(valid_names:ItemList) → ItemLists# 按valid_names指定的文件名进行分划
split_by_fname_file(fname:PathOrStr, path:PathOrStr=None)# 按fname文件存储的文件名进行分划
split_by_folder(train:str='train', valid:str='valid')# 按照文件夹的名称进行分划
split_by_idx(valid_idx:Collection[int])# 按照valid_idx指定的索引进行分划
split_by_idxs(train_idx, valid_idx)# 同时指定train和valid两个索引列表
split_by_list(train, valid)# 同时指定train和valid的文件列表
split_by_valid_func(func:Callable)# 传入文件名,按照返回值的真假进行分划(取真时为validation数据集)
split_from_df(col:IntsOrStrs=2)# 使用inner_df的第col列进行分划(取真时为validation数据集)# 这一函数要求ItemList是由from_df()或者from_csv()构建的
3. 生成数据标签
由ItemLists实例调用label_from_*函数完成;其返回的是LabelLists实例,该实例由两个LabelList组成;而LabelList类继承自PyTorch的Dataset类,整合了数据x和标签y(二者均是ItemList类或其子类),并实现了Dataset类所必需的__len__()和__getitem__()函数。
label_from_df(cols:IntsOrStrs=1, label_cls:Callable=None, **kwargs)# 由inner_df的第cols列提供标签,cols可以为多列# 这一函数要求ItemList是由from_df()或者from_csv()构建的
label_from_folder(label_cls:Callable=None, **kwargs)# 由文件路径的最后一层的名称指定标签
label_from_func(func:Callable, label_cls:Callable=None, **kwargs)# 由函数提供标签,该函数接受文件名作为参数,返回一个类别
label_from_re(pat:str, full_path:bool=False, label_cls:Callable=None, **kwargs)# 由正则表达式提供标签。
4. 生成模型所需的数据包
由LabelLists实例调用databunch()生成,实际上是通过调用DataBunch.create()函数完成的。
二、针对视觉任务的调整 (文档链接)
1. 使用ImageList替换ItemList
ImageList是ItemList的子类,其主要覆写了对列表进行索引时所需用到的get()函数,即在索引时使用open_image()打开图像。另外,ImageList还覆写了from_df()和from_csv()函数,其中会将数据路径与df或csv中的相对路径拼合成绝对路径。
2. 使用ImageDataBunch替换DataBunch
这一设置其实也是在ImageList中进行的。在ItemList类中,用一个类变量_bunch记录数据包的类DataBunch;而在ImageList中,这一变量的值变为了ImageDataBunch。ImageDataBunch是DataBunch的子类。
三、其他需要注意的地方
1. ItemLists的属性
查询ItemLists的实例属性时,调用的是__getattr__()函数。首先查看self.train的相应属性,若查到的属性不是Callable的,则直接返回;否则,则在self.train和self.valid上分别调用相应属性,并将结果替换self.train和self.valid。
事实上,如LabelInstance.classes也是类似的逻辑。
2. 数据预处理
预设的预处理操作是通过ItemList的类属性_processor来设置的。如果在创建ItemList时,指定了实例变量processor,则将覆盖_processor的作用。预处理操作均应为PreProcessor类的实例,该实例主要包含用于处理单条记录的process_one()函数和用于列表处理的process()函数;process()函数将使用预处理后的结果替换掉传入的数据列表。
如对分类问题,在由ItemLists实例调用label_from_*方法(由前所述,该调用实际会在ItemListsInstance.train和ItemListsInstance.valid两个ItemList实例上分别调用label_from_*方法)时,会首先判断标签类型为CategoryList,该类继自CategoryListBase;而CategoryListBase继承自ItemList,并且类成员变量_processor为CategoryProcessor(ItemList类的_processor为None)。这样,由label_from_*方法生成的LabelList对象的x将为ItemList类,对其进行的预处理将为空;而其y将为CategoryList类,对其进行的预处理将为CategoryProcessor,即将标签中的不同值当做标签集合,并提供标签字面值与索引的映射字典。
四、示例
仍使用fastai.URLs.MNIST_SAMPLEi数据,假设数据所在文件夹为path,则:
data = (ImageList.from_folder(path) # 数据文件的路径.split_by_folder() # 按比例分割训练集和验证集.label_from_folder() # 指定类别标签.transform(size=32) # 对图像进行变换.databunch(bs=128).normalize(imagenet_stats) # 数据归一化
)
假设要从每张图片中预测三个浮点值,数据准备如下:
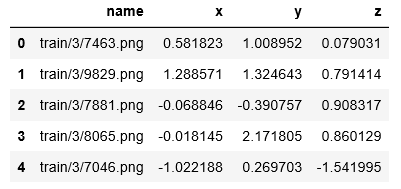
il = (ImageList.from_csv(path=path, csv_name="labels_float.csv").split_by_idx(range(20)).label_from_df(cols=[1,2,3], label_cls=FloatList).transform(size=32).databunch(bs=128).normalize(imagenet_stats)
)
其中在做label_from_df()调用时,需要指明Label Class为FloatList类型,否则会默认设置为MultiCategoryList类。
注意,其中均未设置对数据应做哪些变换,这一部分内容将在下一篇博文中介绍。
这篇关于第三篇 FastAI数据构造API的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



