本文主要是介绍运用python模拟登录豆瓣爬取并分析某部电影的影评,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前段时间奉俊昊的《寄生虫》在奥斯卡上获得不少奖项,我也比较喜欢看电影,看过这部电影后比较好奇其他人对这部电影的看法,于是先用R爬取了部分豆瓣影评,jieba分词后做了词云了解,但是如果不登录豆瓣直接爬取影评只可以获得十页短评,这个数据量我认为有点少,于是整理了python模拟登录豆瓣,批量爬取数据,制作特别样式词云的方法。
一、 用到的Python库
import os ##提供访问操作系统服务的功能
import re ##正则表达式
import time ##处理时间的标准库
import random ##使用随机数标准库import requests ##实现登录
import numpy as np ##科学计算库,是一个强大的N维数组对象ndarray
import jieba ##jieba分词库
from PIL import Image ##python image library 库,python3多用pillow库
import matplotlib.pyplot as plt ##绘图
plt.switch_backend('tkagg')
from wordcloud import WordCloud, ImageColorGenerator##词云制作
关于每个库的运用要熟悉挺久,我也只是入门级
二、思路
1. 模拟登录豆瓣
2. 爬取一页影评
3. 批量爬取影评
4. 制作普通词云
5. 制作图片形状背景的词云
三、代码实现
1. 模拟登录豆瓣
首先需要分析豆瓣的登录页面
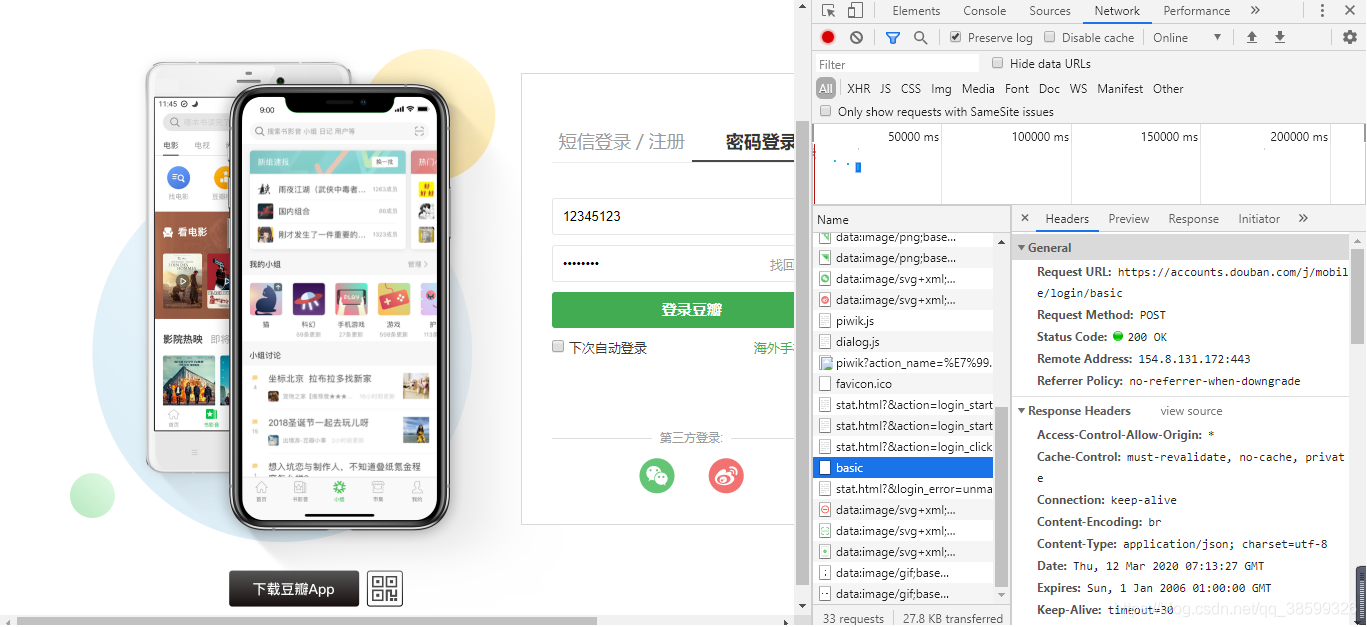
点击鼠标右键进入“检查”,在登录窗口里输入错误的登录信息,进入Network下名为basic中,这里有许多有用的信息,如
Request URL,User-Agent,Accept-Encoding,等等
还需要看看请求登录时携带的参数,将调试窗口往下拉查看Form Data。
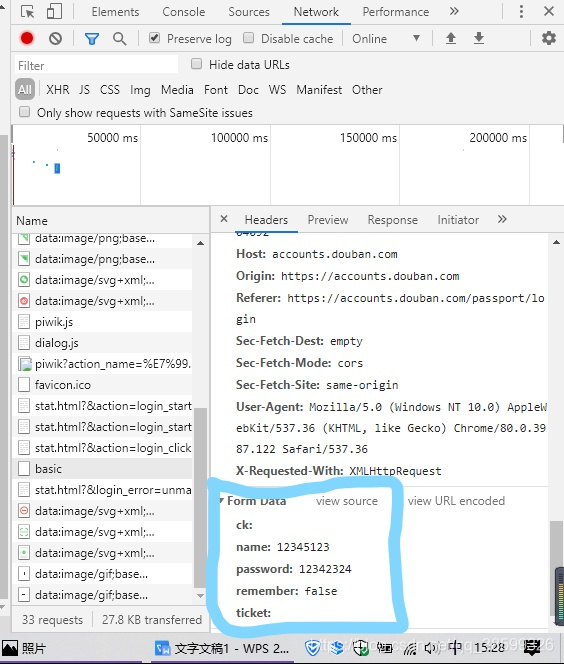
代码模拟登录:
# 生成Session对象,用于保存Cookie
s = requests.Session()
# 影评数据保存文件
COMMENTS_FILE_PATH = 'douban_comments.txt'
# 词云字体
WC_FONT_PATH = 'C:/Windows/Fonts/SIMLI.TTF'def login_douban():"""登录豆瓣:return:"""# 登录URLlogin_url = 'https://accounts.douban.com/j/mobile/login/basic'# 请求头headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36','Host': 'accounts.douban.com','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.9','Referer': 'https://accounts.douban.com/passport/login?source=main','Connection': 'Keep-Alive'}# 传递用户名和密码data = {'name': '12345125',##这里改为你正确的登录名'password': '12342324',##这里改为你正确的登录密码'remember': 'false'}try:r = s.post(login_url, headers=headers, data=data)r.raise_for_status()except:print('登录请求失败')return 0print(r.text)return 12. 爬取一页影评
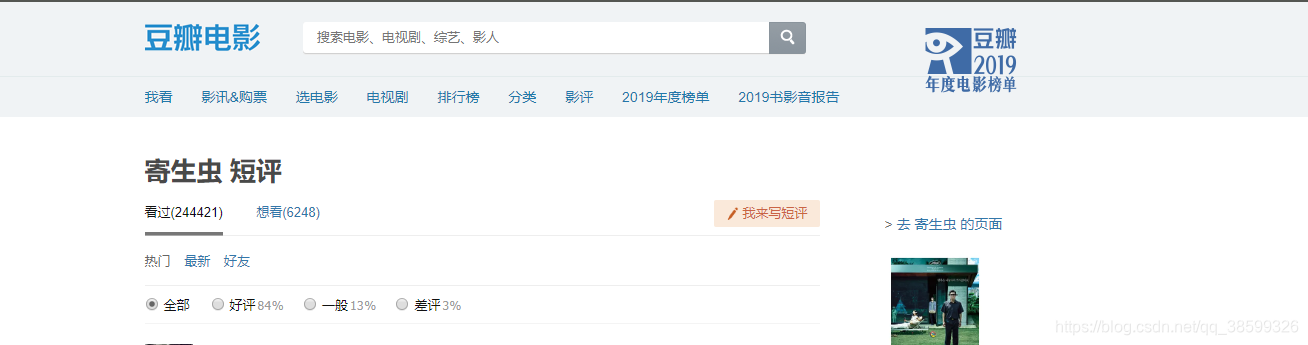
进入电影的短评页面,分析网页,获得网页的URL,然后分析网页源代码,查看影评在网页哪个标签内,有什么特点,然后使用正则表达式来匹配想要的标签内容。
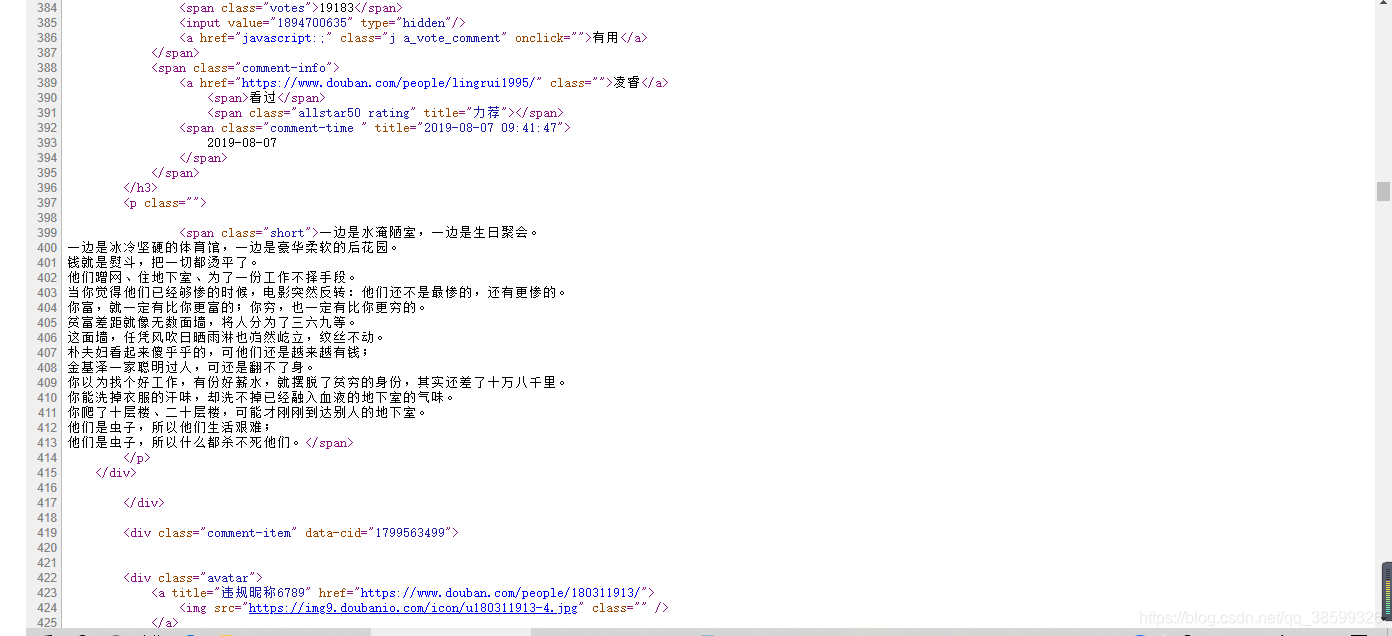
可以发现影评都在 < s p a n c l a s s = " s h o r t " > < / s p a n > <span class="short"></span> <spanclass="short"></span>这个标签里。
代码:
def spider_comment(page=0):"""爬取某页影评"""print('开始爬取第%d页' % int(page))start = int(page * 20)comment_url = 'https://movie.douban.com/subject/27010768/comments?start=%d&limit=20&sort=new_score&status=P' % start# 请求头headers = {'user-agent': 'Mozilla/5.0'}try:r = s.get(comment_url, headers=headers)#s.get()r.raise_for_status()except:print('第%d页爬取请求失败' % page)return 0# 使用正则提取影评内容comments = re.findall('<span class="short">(.*)</span>', r.text)##正则表达式匹配if not comments:return 0# 写入文件with open(COMMENTS_FILE_PATH, 'a+', encoding=r.encoding) as file:file.writelines('\n'.join(comments))return 13. 批量爬取影评
批量爬取主要分析网页的分页参数,在豆瓣短评url中,start参数是控制分页的参数。
def batch_spider_comment():"""批量爬取豆瓣影评"""# 写入数据前先清空之前的数据if os.path.exists(COMMENTS_FILE_PATH):os.remove(COMMENTS_FILE_PATH)##若系统已有这个文件,删除它page = 0while spider_comment(page):page += 1# 模拟用户浏览,设置一个爬虫间隔,防止ip被封time.sleep(random.random() * 3)print('爬取完毕')if login_douban():##登录成功就会批量爬取batch_spider_comment()
登录成功的话就会执行批量爬取,豆瓣网页只可查看25页的短评

得到短评文档如下:

4. 制作普通词云
影评获得后,就可以用jieba来分词,用wordcloud制作词云了。最普通的词云都可以这样制作:
####制作词云
f = open(COMMENTS_FILE_PATH,'r',encoding='UTF-8').read()
wordlist = jieba.cut(f, cut_all=True)
wl = " ".join(wordlist)
# 数据清洗词列表
stop_words = ['就是', '不是', '但是', '还是', '只是', '这样', '这个', '一个','一切','一场','一部','这部', '如果','这种','觉得','什么', '电影', '没有']
# 设置词云的一些配置,如:字体,背景色,词云形状,大小
wc = WordCloud(background_color="white", scale=4,max_words=300,max_font_size=50, random_state=42, stopwords=stop_words, font_path=WC_FONT_PATH)
# 生成词云
wc.generate(wl)
# 在只设置mask的情况下,你将会得到一个拥有图片形状的词云
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()
得到的词云如下:

5. 制作图片形状背景的词云
会制作普通词云其实比较一般,我们还可以制作图片形状背景的词云,并且词的颜色与图片颜色一致。
##生成图片形状背景的词云
def GetWordCloud():path_img = "C://Users/Administrator/Desktop/Blonde-girl.jpg"##图片路径f = open(COMMENTS_FILE_PATH,'r',encoding='UTF-8').read()wordlist = jieba.cut(f, cut_all=True)wl = " ".join(wordlist)background_image = np.array(Image.open(path_img))##Image对象与array之间的转换# 结巴分词,生成字符串,如果不通过分词,无法直接生成正确的中文词云,感兴趣的朋友可以去查一下,有多种分词模式# #Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。# 数据清洗词列表stop_words = ['就是', '不是', '但是', '还是', '只是', '这样', '这个', '一个','一切','一场','一部','这部', '如果','这种','觉得','什么', '电影', '没有']# 设置词云的一些配置,如:字体,背景色,词云形状,大小wc = WordCloud(background_color="white", scale=4,max_words=300,##max_words默认200max_font_size=50, random_state=42, stopwords=stop_words, font_path=WC_FONT_PATH,mask= background_image)# 生成词云wc.generate(wl)# 在只设置mask的情况下,你将会得到一个拥有图片形状的词云# 生成颜色值image_colors = ImageColorGenerator(background_image)# 下面代码表示显示图片plt.imshow(wc.recolor(color_func=image_colors), interpolation="bilinear")plt.axis("off")plt.show()if __name__ == '__main__':GetWordCloud()
背景图片如下:

图片背景的词云:

从词云可以看出来,豆瓣网友喜欢拿《燃烧》与这部电影对比,并且能看到醒目的“富人”,“穷人”,“阶级”,“底层”这种词语说明大多数人都认为《寄生虫》是反映这些主题的电影,也隐约可以看到“喜欢”,“好看”,“完美”这些夸奖的词汇,说明大部分人是认可这部电影的,但也能看见“商业”这样的评价,说明对这部电影还是存在一些争议。
四、总结
如上结束了我们模拟网页登录,提取网页中影评,批量爬取,制作词云与特别形状词云。
整个流程下来会大致了解网页结构,爬虫思路,简单了解requests库的实用,与用R对比起来Python爬虫的确更加优美方便,正则表达式提取影评部分也非常的直接,数据清洗,词云制作,也非常的通俗易懂,Python的确是不得不学习的利器之一。
参考:https://blog.csdn.net/u014044812/article/details/96484905
这篇关于运用python模拟登录豆瓣爬取并分析某部电影的影评的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




