本文主要是介绍【PaddleHub模型贡献】一行代码实现蛇种识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一行代码实现蛇种识别
- 一、模型开发
- 1.安装必要的资源库
- 2.数据预处理
- 2.1解压数据集
- 2.2划分训练集
- 3.模型训练
- 3.1设置使用0号GPU卡
- 3.2图像预处理+数据增强
- 3.3数据迭代器的定义
- 3.4开始炼丹
- 4.查看模型预测效果
- 二、封装Module
- 1.导出inference模型
- 2.模型转换
- 3.模型安装
- 4.模型预测
- 预测单张图片
- 预测多张图片
- 三、在GitHub上提pr
- 1.Fork PaddleHub
- 2.上传Module
- 3.Pull Request
- 四、总结与升华
- 个人简介
毒蛇伤人事件在全世界范围内已造成相当一部分的死亡和受伤案例,这对于公众健康是一个重要的却又容易被忽视的影响因素。一部分人被蛇咬后无法准确地区分蛇的种类,无法知道蛇有毒与否,并且还因为不具备一定的自救知识而被蛇咬后不知所措。基于此,开发者 叶月火狐 基于飞桨开发了一款《野外蛇谱》的app,帮助人们在野外被蛇咬后准确识别蛇的种类,并精准判断蛇的毒性,提供自救方案,帮助人们在被蛇咬后的紧急处理。
前不久,飞桨官方在AI Studio上挑选了45个优质项目,优质项目链接:https://shimo.im/sheets/CqQvXq3JhGqCxdXv/MODOC
开发者 叶月火狐 开发的《野外蛇谱》的app是上面的优质项目之一,将其转换成PaddleHub模型可供更多开发者快速使用。
参考资料:
- 基于飞桨开发的《野外蛇谱》app
- 手把手带你将Paddlex模型部署为PaddleHub
- 【PaddleHub模型贡献】一行代码实现水表的数字表盘分割
- 【PaddleHub模型贡献】一行代码实现从彩色图提取素描线稿
一、模型开发
1.安装必要的资源库
原项目使用PaddleX开发,因此这里先安装PaddleX:
!pip install paddlex
2.数据预处理
2.1解压数据集
!unzip data/data44587/snake_data.zip -d /home/aistudio/
2.2划分训练集
!paddlex --split_dataset --format ImageNet --dataset_dir '/home/aistudio/snake_data' --val_value 0.2 --test_value 0.1
3.模型训练
3.1设置使用0号GPU卡
import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import paddlex as pdx
3.2图像预处理+数据增强
from paddlex.cls import transforms
train_transforms = transforms.Compose([transforms.RandomCrop(crop_size=224),transforms.RandomHorizontalFlip(),transforms.Normalize()
])
eval_transforms = transforms.Compose([transforms.ResizeByShort(short_size=256),transforms.CenterCrop(crop_size=224),transforms.Normalize()
])
3.3数据迭代器的定义
train_dataset = pdx.datasets.ImageNet(data_dir='snake_data',file_list='snake_data/train_list.txt',label_list='snake_data/labels.txt',transforms=train_transforms,shuffle=True)
eval_dataset = pdx.datasets.ImageNet(data_dir='snake_data',file_list='snake_data/val_list.txt',label_list='snake_data/labels.txt',transforms=eval_transforms)
2020-07-19 11:49:17 [INFO] Starting to read file list from dataset...
2020-07-19 11:49:17 [INFO] 17364 samples in file snake_data/train_list.txt
2020-07-19 11:49:17 [INFO] Starting to read file list from dataset...
2020-07-19 11:49:17 [INFO] 25 samples in file snake_data/val_list.txt
3.4开始炼丹
num_classes = len(train_dataset.labels)
model = pdx.cls.ResNet50_vd_ssld(num_classes=num_classes)
model.train(num_epochs = 60,save_interval_epochs = 10,train_dataset = train_dataset,train_batch_size = 64,eval_dataset = eval_dataset,learning_rate = 0.025,warmup_steps = 1084,warmup_start_lr = 0.0001,lr_decay_epochs=[20, 40],lr_decay_gamma = 0.025, save_dir='/home/aistudio',use_vdl=True)
4.查看模型预测效果
import cv2
import matplotlib.pyplot as plt# 加载模型
print('**************************************加载模型*****************************************')
model = pdx.load_model('best_model')# 显示图片
img = cv2.imread('test.jpg')
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
%matplotlib inline
plt.imshow(img)# 预测
result = model.predict('test.jpg', topk=3)
print('**************************************预测*****************************************')
print(result[0])
**************************************加载模型*****************************************
2020-07-19 14:21:06 [INFO] Model[ResNet50_vd_ssld] loaded.
**************************************预测*****************************************
{'category_id': 4, 'category': '西部菱斑响尾蛇', 'score': 0.9999999}

二、封装Module
1.导出inference模型
| 参数 | 说明 |
|---|---|
| –model_dir | inference模型所在的文件地址,文件包括:.pdparams、.pdopt、.pdmodel、.json和.yml |
| –save_dir | 导出inference模型,文件将包括:__model__、__params__和model.yml |
!paddlex --export_inference --model_dir=best_model --save_dir=./inference_model/ResNet50_vd_ssld
W0717 23:24:19.157521 13809 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 9.2, Runtime API Version: 9.0
W0717 23:24:19.161340 13809 device_context.cc:260] device: 0, cuDNN Version: 7.3.
2020-07-17 23:24:22 [INFO] Model[ResNet50_vd_ssld] loaded.
2020-07-17 23:24:22 [INFO] Model for inference deploy saved in ./inference_model/ResNet50_vd_ssld.
2.模型转换
PaddleX模型可以快速转换成PaddleHub模型,只需要用下面这一句命令即可:
!hub convert --model_dir inference_model/ResNet50_vd_ssld \--module_name SnakeIdentification \--module_version 1.0.0 \--output_dir outputs
转换成功后的模型保存在outputs文件夹下,我们解压一下:
!gzip -dfq /home/aistudio/outputs/SnakeIdentification.tar.gz
!tar -xf /home/aistudio/outputs/SnakeIdentification.tar
3.模型安装
安装我们刚刚转换的模型:
!hub install SnakeIdentification
4.模型预测
预测单张图片

import cv2
import paddlehub as hubmodule = hub.Module(name="SnakeIdentification")images = [cv2.imread('snake_data/class_1/2421.jpg')]# execute predict and print the result
results = module.predict(images=images)
for result in results:print(result)
[2021-03-12 10:55:05,972] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object[{'category_id': 0, 'category': '水蛇', 'score': 0.9999205}]
预测多张图片
选取5张图片,每张图片对应一个类别:

import cv2
import paddlehub as hubmodule = hub.Module(name="SnakeIdentification")images = [cv2.imread('snake_data/class_1/2421.jpg'), cv2.imread('snake_data/class_2/113.jpg'), cv2.imread('snake_data/class_3/757.jpg'),cv2.imread('snake_data/class_4/1101.jpg'), cv2.imread('snake_data/class_5/2566.jpg')]# execute predict and print the result
results = module.predict(images=images)
for result in results:
nt the result
results = module.predict(images=images)
for result in results:print(result)
[2021-03-12 11:00:07,036] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object[{'category_id': 0, 'category': '水蛇', 'score': 0.9999205}]
[{'category_id': 1, 'category': '剑纹带蛇', 'score': 0.9988399}]
[{'category_id': 2, 'category': '德凯斯氏蛇', 'score': 0.9867851}]
[{'category_id': 3, 'category': '黑鼠蛇', 'score': 0.9468411}]
[{'category_id': 4, 'category': '西部菱斑响尾蛇', 'score': 1.0}]
三、在GitHub上提pr
pr就是Pull Request(翻译过来就是:拉取请求)的简称
1.Fork PaddleHub
进入PaddleHub的源码仓库https://github.com/PaddlePaddle/PaddleHub

看到这个箭头指向的按钮了吗?点它!!!
如果可以的话,可以顺手把它旁边的Star给点了(手动狗头)
点击以后,你的账号下面就有一个叫PaddleHub的代码仓库了,就像这样:
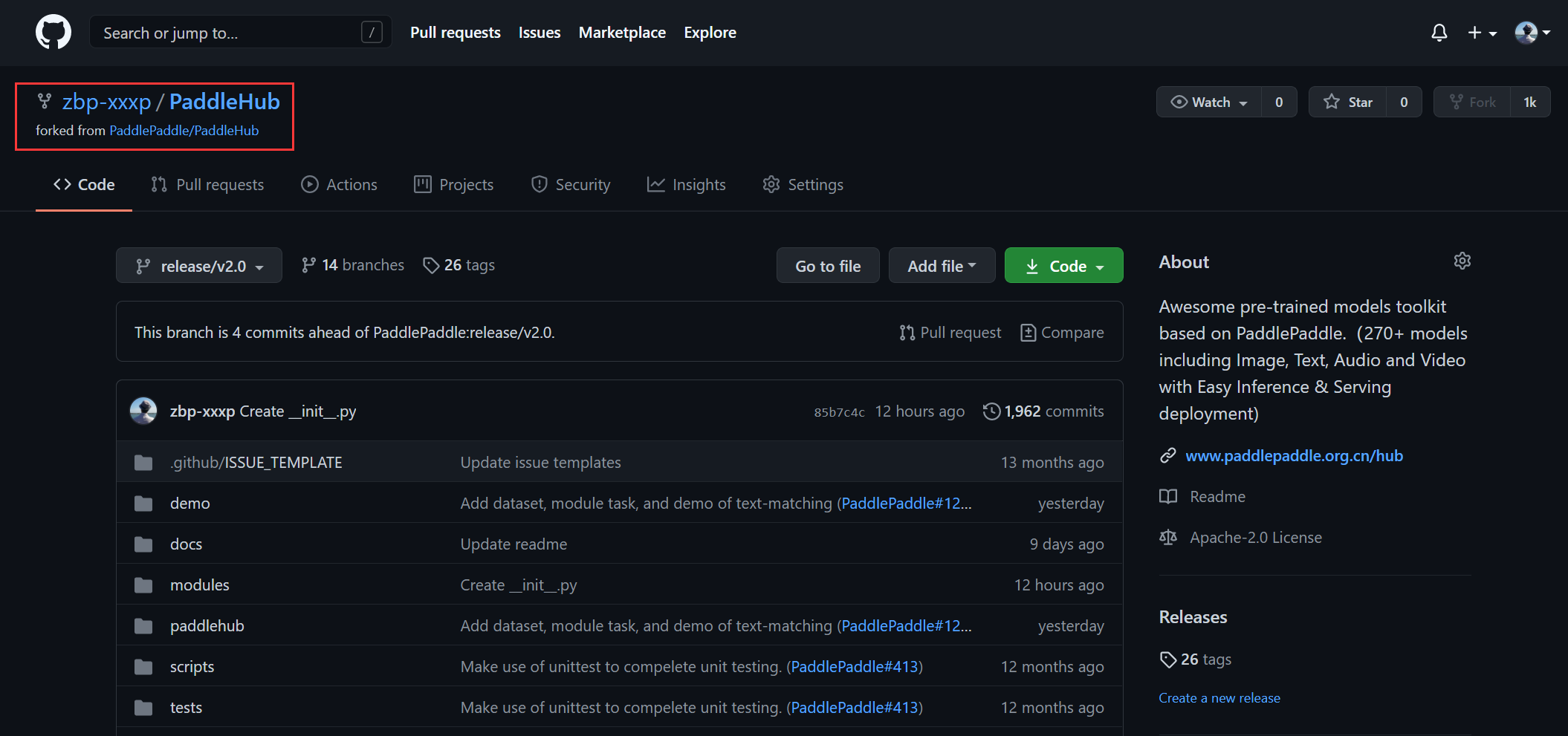
2.上传Module
本项目是图像分类的项目,所以进入到图像分类的目录下:
PaddleHub/modules/image/classification/
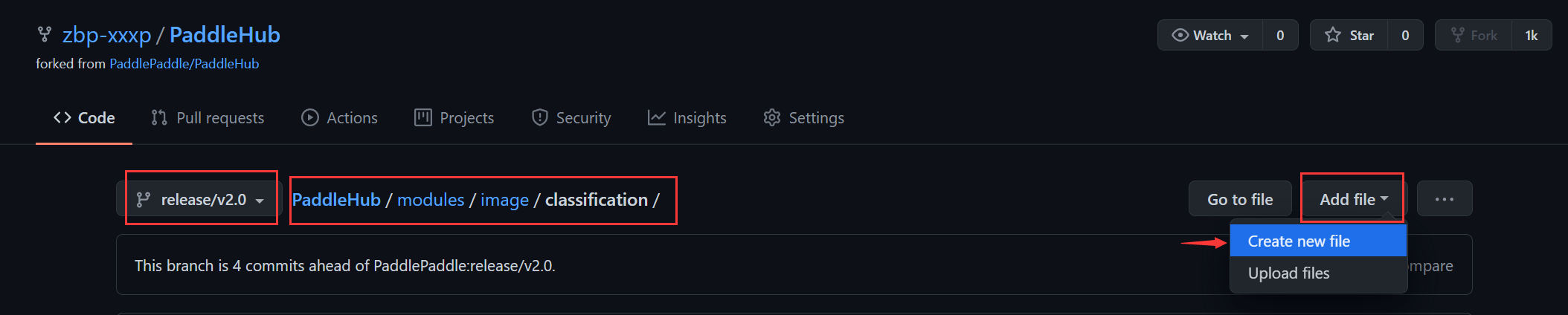
点击Add file:
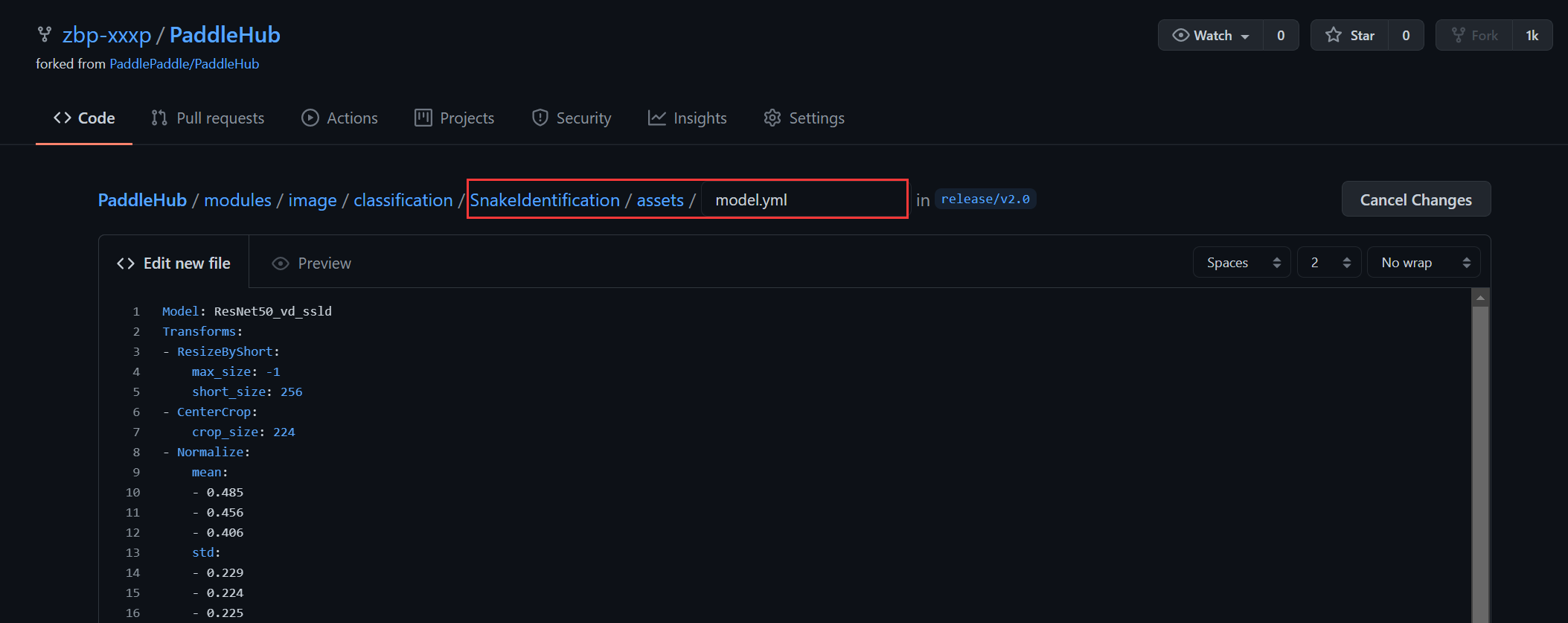
先输入您上传的Module名称,这里我的Module名称命名为SnakeIdentification,将它变成一个文件夹,只需要在后面加一个‘/’,创建好文件夹以后,把Module里的文件上传上去即可:
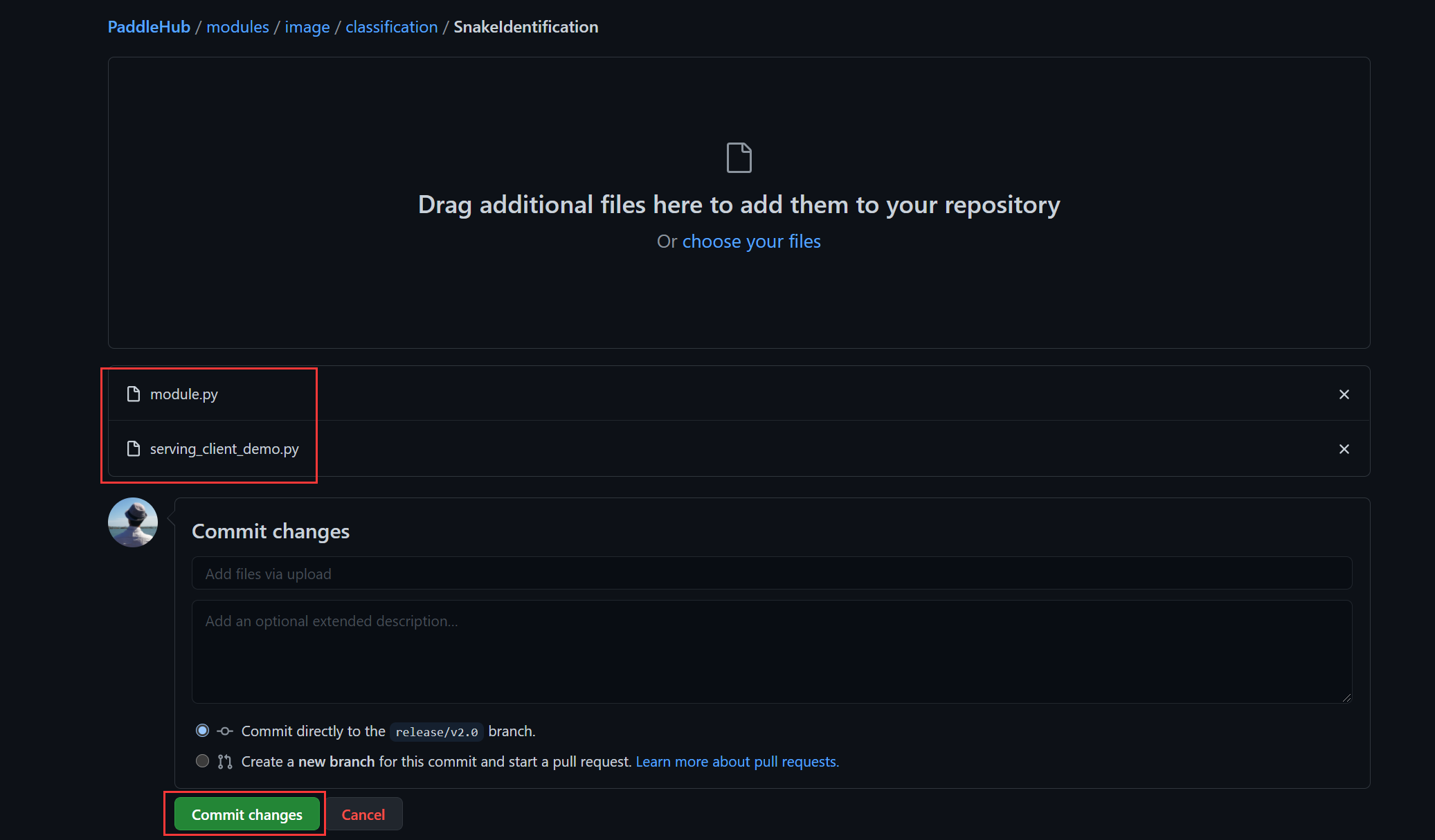
上传成功后,点击Commit,文件就会自动上传到你自己的代码仓库里
3.Pull Request
最后一步,拉取请求:
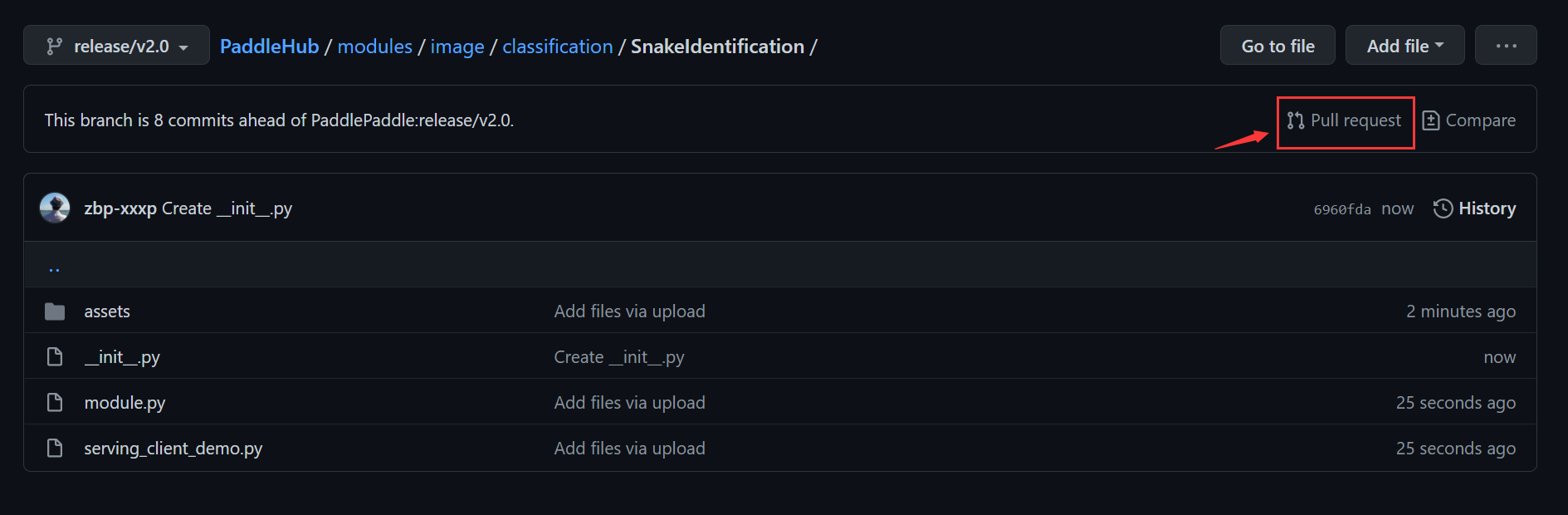
确认无误后点击提交即可:
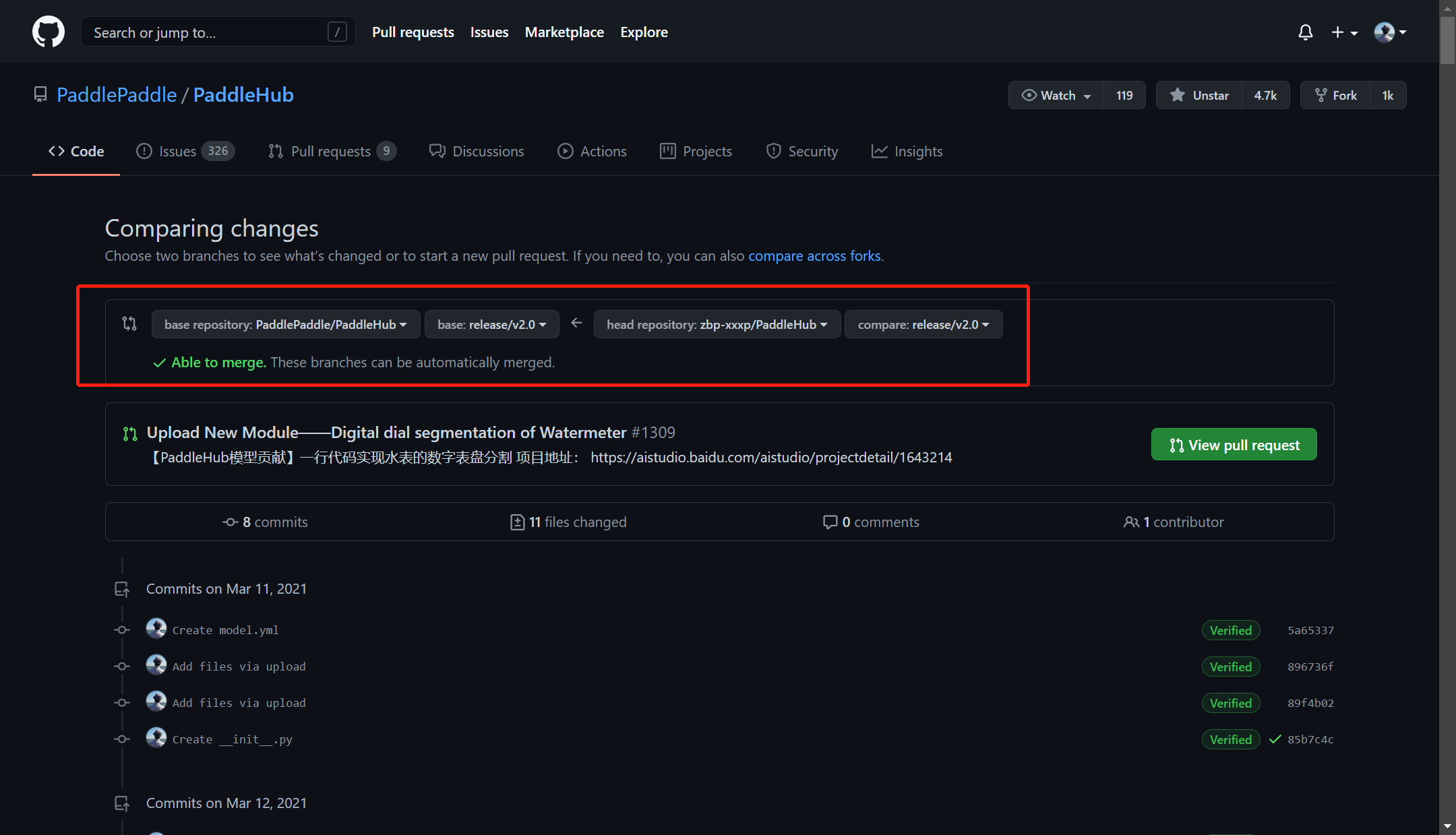
四、总结与升华
这次图像分类的任务比较简单,用的时间大概是2个小时,总的来说,熟练以后还是蛮简单的。
最近飞桨有新活动,给飞桨PaddlePaddle家族提PR,根据积分排行,可以兑换惊喜大礼!活动详情请见:飞桨开发者技术专家(PPDE) Q1活动开启
大家赶紧冲呀!!!
个人简介
北京联合大学 机器人学院 自动化专业 2018级 本科生 郑博培
百度飞桨开发者技术专家 PPDE
百度飞桨官方帮帮团、答疑团成员
深圳柴火创客空间 认证会员
百度大脑 智能对话训练师
阿里云人工智能、DevOps助理工程师
我在AI Studio上获得至尊等级,点亮9个徽章,来互关呀!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378

这篇关于【PaddleHub模型贡献】一行代码实现蛇种识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






