本文主要是介绍[c++] 工厂模式 + cyberrt 组件加载器分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用对象的时候,可以直接 new 一个,为什么还需要工厂模式 ?
工厂模式属于创建型设计模式,将对象的创建和使用进行解耦,对用户隐藏了创建逻辑。
个人感觉上边的表述并没有说清楚为什么需要使用工厂模式。因为使用 new 创建一个对象的时候,比如 new Object(x, x, x, x),对象创建逻辑在构造函数中实现,逻辑也对用户隐藏了,在一定程度上也实现了解耦。
为什么使用工厂模式 ?
生活中的工厂是生产商品的,一个工厂生产的商品往往有多个种类,比如手机代工厂,可能会代工多个品牌的手机。c++ 的工厂模式来源于生活,工厂模式常常应用于多态的场景,有一个基类,派生出多个类,创建这些类的时候,使用工厂模式就比较合适。
比如一个工厂代工了 3 个品牌的手机,apple, mi, oppo。如下图所示,我们往往会定义一个基类 Phone,在基类的基础上派生出 3 个子类:ApplePhone,MiPhone,OppoPhone。如果开发者在创建这些类的时候,需要分别 new ApplePhone(),new MiPhnoe(),new OppoPhone(),这样使用 new 的方式就不如使用工厂模式简单了。
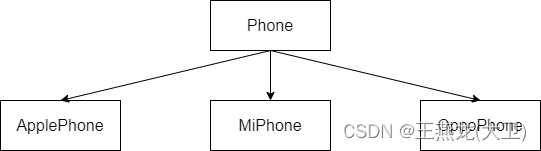
1 简单工厂
手机工厂的例子,代码如下。
(1)一个抽象类,class Phone
(2)3 个派生类,ApplePhone,MiPhone, OppoPhone
(3)一个工厂类 PhoneFactory
可以看到,相对于直接使用 new 来创建对象,工厂类就是把产品的类型和类的对应关系这个逻辑给隐藏起来了,用户使用的时候只需要传一个手机类型就可以了。
#include <iostream>
#include <string>class Phone {
public:virtual ~Phone() {}virtual void CallUp() = 0;
};class ApplePhone : public Phone {
public:void CallUp() {std::cout << "ApplePhone call up" << std::endl;}
};class MiPhone : public Phone {
public:void CallUp() {std::cout << "MiPhone call up" << std::endl;}
};class OppoPhone : public Phone {
public:void CallUp() {std::cout << "OppoPhone call up" << std::endl;}
};enum PHONE_TYPE {APPLE,MI,OPPO
};class PhoneFactory {
public:Phone *CreatePhone(PHONE_TYPE type) {switch (type) {case APPLE:return new ApplePhone();case MI:return new MiPhone();case OPPO:return new OppoPhone();default:return nullptr;}}
};int main() {PhoneFactory phone_factory;Phone *apple = phone_factory.CreatePhone(APPLE);if (apple != nullptr) {apple->CallUp();delete apple;apple = nullptr;}Phone *mi = phone_factory.CreatePhone(MI);if (mi != nullptr) {mi->CallUp();delete mi;mi = nullptr;}Phone *oppo = phone_factory.CreatePhone(OPPO);if (oppo != nullptr) {oppo->CallUp();delete oppo;oppo = nullptr;}return 0;
}
2 工厂方法
简单工厂模式,如果生产的产品类型发生变化的时候需要改变工厂类,增减一个 if 分支,或者增减一个 case 分支 。有一个编码原则是 "对修改关闭,对扩展开发",简单工厂就违反了这条编码原则。因此,从简单工厂模式又延伸出了工厂方法模式。
工厂方法模式,需要增加一个工厂类。一个抽象工厂类 Factory,这个类派生出 3 个子类, AppleFactory,MiFactory,OppoFactory。
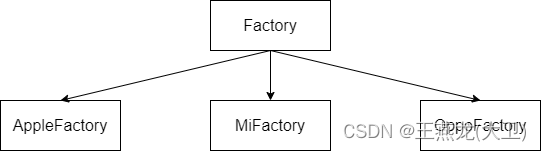
一个全局的表 map,这个 map 的 key 是商品的类型,value 是工厂类。这样的话,如果需要增加一种商品,只需要增加一个工厂类,然后在 map 中增加一项就可以了。
工厂类创建对象的时候,根据类型去 map 中查找对应的工厂,找到工厂之后就行生产。这样当增加商品的时候就彻底不需要修改工厂类了。把修改的范围缩小了,并且做了解耦。

多种设计模式中都使用了 map 来对代码进行解耦,并且做到对修改关闭,对扩展开方。比如策略模式,职责链模式。
代码如下,代码中有一个全区的数据结构 factory_map,key 是手机类型,value 是工厂类。每定义一个工厂类,都可以通过宏 REGISTER_FACTORY 将工厂类注册到 factory_map 中。这样在使用的时候,只需要根据类型去 factory_map 中查找对应的工厂类,找到之后就可以生产。
#include <iostream>
#include <string>
#include <map>enum PHONE_TYPE {APPLE,MI,OPPO
};class Factory;
std::map<PHONE_TYPE, Factory *> factory_map;#define REGISTER_FACTORY(factory_type, class_name) \
struct ClassRegister##class_name { \ClassRegister##class_name() { \factory_map[factory_type] = new class_name(); \}; \
}; \
static struct ClassRegister##class_name factory_register##class_name;// 手机类
class Phone {
public:virtual ~Phone() {}virtual void CallUp() = 0;
};class ApplePhone : public Phone {
public:void CallUp() {std::cout << "ApplePhone call up" << std::endl;}
};class MiPhone : public Phone {
public:void CallUp() {std::cout << "MiPhone call up" << std::endl;}
};class OppoPhone : public Phone {
public:void CallUp() {std::cout << "OppoPhone call up" << std::endl;}
};// 工厂类
class Factory {
public:virtual ~Factory() {};virtual Phone *CreatePhone() = 0;
};class AppleFactory : public Factory {
public:Phone *CreatePhone() {return new ApplePhone();};
};
REGISTER_FACTORY(APPLE, AppleFactory);class MiFactory : public Factory {
public:Phone *CreatePhone() {return new MiPhone();};
};
REGISTER_FACTORY(MI, MiFactory);class OppoFactory : public Factory {
public:Phone *CreatePhone() {return new OppoPhone();};
};
REGISTER_FACTORY(OPPO, OppoFactory);class PhoneFactory {
public:Phone *CreatePhone(PHONE_TYPE type) {if (factory_map.count(type) > 0) {return factory_map[type]->CreatePhone();}return nullptr;}
};int main() {PhoneFactory phone_factory;Phone *apple = phone_factory.CreatePhone(APPLE);if (apple != nullptr) {apple->CallUp();delete apple;apple = nullptr;} else {std::cout << "apple is nulptr" << std::endl;}Phone *mi = phone_factory.CreatePhone(MI);if (mi != nullptr) {mi->CallUp();delete mi;mi = nullptr;}Phone *oppo = phone_factory.CreatePhone(OPPO);if (oppo != nullptr) {oppo->CallUp();delete oppo;oppo = nullptr;}return 0;
}
3 cyberrt 中组件加载器
cyberrt 中提供了两个基类 TimerComponent 和 Component。用户可以根据自己的业务需求,是定时触发还是事件触发来决定基于 TimerComponent 开发还是基于 Component 开发。比如自动驾驶系统中的传感器组件(camera,lidar,radar) 一般是定时组件,定时将传感器数据向外发布;感知,预测,决策,控制模块一般是事件触发,一般基于 Component 开发。如下图所示,TimerComponent 和 Component 由 ComponentBase 派生出来,这 3 个类都是属于架构层的类;上层的 camera,lidar,radar,perception,prediction 等组件属于业务层。
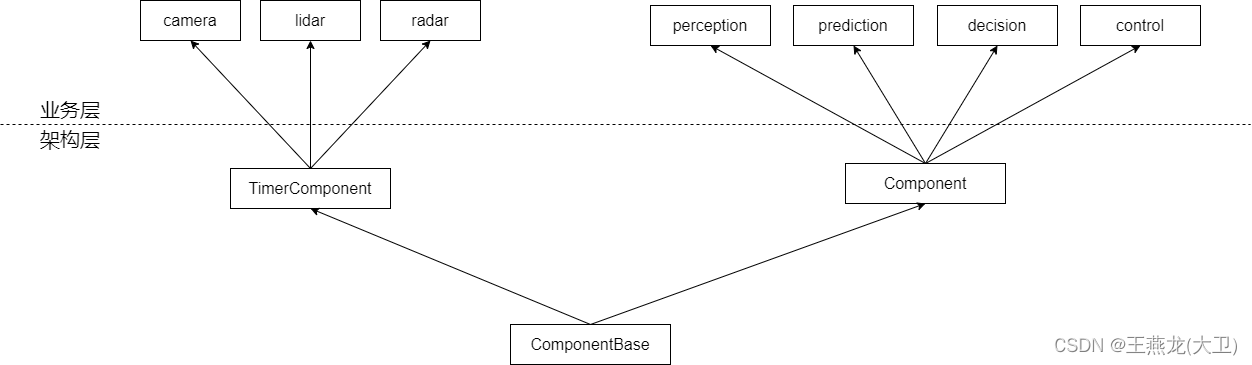
用户开发的软件最后会编译成一个动态库,动态库的加载和运行通过 cyberrt 中的组件加载器来进行。组件加载器的实现使用了工厂模式,并且使用的是工厂方法模式。
3.1 类加载
cyberrt 加载运行组件的时候,首先要加载用户的动态库。动态库的加载通过类 ClassLoader 来完成。
(1)动态库加载函数 dlopen()
底层动态库的加载是通过函数 dlopen() 完成。dlopen() 可以直接传动态库的名字,比如 libcamera.so,也可以传动态库的路径,比如 /ads/lib/libcamera.so。传动态库名字的时候,dlopen() 查找动态库的时候会根据系统的配置来查找,查找的路径有以下 5 个,按优先级先后顺序是 rpath > LD_LIBRARY_PATH > /etc/ls.so.cache > /lib > /usr/lib。
① rpath
在编译的时候可以加编译选项,比如 -Wl,-rpath,/ads/lib,这样 /ads/lib 的路径就会保存到动态库中。
② LD_LIBRARY_PATH
环境变量,可以配置动态库的路径。
③ /etc/ls.so.cache
这个缓存中的路径,可以通过 ldconfig -p 查看缓存中的动态库。
如果想要向这个缓冲区中配置路径,可以增加一个 conf 文件放到目录 /etc/ld.so.conf.d/ 中,然后再执行 ldconfig,就能通过 ldconfig -p 查看到自己的路径。
(2)保存动态库的全局数据结构
动态库加载之后要保存到一个数据结构中,数据结构是一个 vector,vector 中的元素是 std::pair 数据,pair 的 key 是动态库的路径,value 是表示加载动态库的类 SharedLibrary。
// using LibPathSharedLibVector =
// std::vector<std::pair<std::string, SharedLibraryPtr>>;
LibPathSharedLibVector& GetLibPathSharedLibVector() {static LibPathSharedLibVector instance;return instance;
}
3.2 创建对象
(1)工厂类
用户开发的组件都要使用下边这个宏进行注册, name 是用户类的类名。在这个宏中最后会通过 RegisterClass() 创建一个工厂类,工厂类放到一个全局单例的 map 里,key 是 classname, value 是工厂类。
#define CYBER_REGISTER_COMPONENT(name) \CLASS_LOADER_REGISTER_CLASS(name, apollo::cyber::ComponentBase)创建对象的时候是在函数 CreateObj() 中完成,对于没有形参的构造函数,使用 new 创建对象的时候,类名后边也可以不加括号。
template <typename ClassObject, typename Base>
class ClassFactory : public AbstractClassFactory<Base> {public:ClassFactory(const std::string& class_name,const std::string& base_class_name): AbstractClassFactory<Base>(class_name, base_class_name) {}Base* CreateObj() const { return new ClassObject; }
};(2)工厂类创建
工厂类创建的在宏 CLASS_LOADER_REGISTER_CLASS_INTERNAL 中实现的。第 2 节工厂方法模式中,自己写的代码就是参考这个宏实现的。这里边有一个技巧,就是定义一个结构体,然后声明一个静态的结构体对象,这样就会调用结构体的构造函数,在构造函数中完成工厂类的注册。
#define CLASS_LOADER_REGISTER_CLASS_INTERNAL(Derived, Base, UniqueID) \namespace { \struct ProxyType##UniqueID { \ProxyType##UniqueID() { \vcl::class_loader::utility::RegisterClass<Derived, Base>(#Derived, \#Base); \} \}; \static ProxyType##UniqueID g_register_class_##UniqueID; \}这篇关于[c++] 工厂模式 + cyberrt 组件加载器分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








