本文主要是介绍Oracle 原理:数据装载 ,SQLldr ,外部表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、导入 SQLldr
SQL*LOADER可以把txt文件,Excel文件导入到数据库中。使用SQLloader导入导出需要一个数据文件和一个控制文件。数据文件中存了你需要导入的数据,控制文件中写你需要怎么导入这些数据。
LOAD DATA
infile 'e:\aa.csv' ## 源文件路径,路径不要包括中文
into table xx_temp <impcmd> ## 要导入的表
(id terminated by whitespace ## id 为列名,whitespace 表示列之间使用空格来区分,如果是其他的 ‘|’ 方式则使用 terminated by '|' 逗号则用逗号.以此类推
)
## 换行 也是自动终止字段读的标识其中 impcmd 中 可以被4个值替换分别是insert (缺省默认值),append,replace,truncate
insert: 插入数据,要求表为空
append:追加数据,在原来表的基础上再插入数据
replace :删除原表数据,再插入
truncate:删除原表数据,再插入,比replace 更高效
例如有这么张表
create table salary_tbl(employer_nm varchar(20) ,department varchar(20) not null,salary number not null,leader_nm varchar(20)
)新建一个.txt文件用于存数据,可以自定义分隔符来区分字段
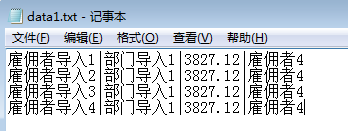
新建一个ctl 以字符 ' |' 分割
或者这样写更简便
load data
infile 'data1.txt'
into table SALARY_TBL append
fields terminated by '|'(employer_nm ,department ,salary ,leader_nm
)在cmd执行 cd 到对应目录执行 ,执行完后可以查看对应位置log的内容
sqlldr userid=system/voapd@orcl control=control1.ctl log=11.log

在cmd 执行 sqlldr 可以查看sqlldr 的帮助
| userid | ORACLE用户名/口令 |
| control | 控制文件名 |
| log | 日志文件名 |
| bad | 错误文件名 |
| data | 数据文件名 |
| discard | 废弃文件名 |
| discardmax | 允许废弃的文件的数目(全部默认) |
| skip | 要跳过的逻辑记录的数目(默认0) |
| load | 要加载的逻辑记录的数目(全部默认) |
| errors | 允许的错误的数目(默认50) |
| rows | 常规路径绑定数组中或直接路径保存数据间的行数(默认:常规路径64,所有直接路径) |
| bindsize | 常规路径绑定数组的大小(以字节计)(默认256000) |
| silent | 运行过程中隐藏消息(标题,反馈,错误,废弃,分区) |
| direct | 使用直接路径(默认FALSE) |
| parfile | 参数文件:包含参数说明的文件的名称 |
| parallel | 执行并行加载(默认FALSE) |
| file | 要从以下对象中分配区的文件 |
| skip_unusable_indexes | 不允许/允许使用无用的索引或索引分区(默认FALSE) |
| skip_index_maintenance | 没有维护索引,将受到影响的索引标记为无用(默认FALSE) |
| commit_discontinued | 提交加载中断时已加载的行(默认FALSE) |
| readsize | 读取缓冲区的大小(默认1048576) |
| external_table | 使用外部表进行加载;NOT_USED,GENERATE_ONLY,EXECUTE(默认NOT_USED) |
| columnarrayrows | 直接路径列数组的行数(默认5000) |
| streamsize | 直接路径流缓冲区的大小(以字节计)(默认256000) |
| multithreading | 在直接路径中使用多线程 |
| resumable | 启用或禁用当前的可恢复会话(默认FALSE) |
| resumable_name | 有助于标识可恢复语句的文本字符串 |
| resumable_timeout | RESUMABLE的等待时间(以秒计)(默认7200) |
| date_cache | 日期转换高速缓存的大小(以条目计)(默认1000) |
| no_index_errors | 出现任何索引错误时中止加载(默认FALSE) |
| PLEASENOTE | 命令行参数可以由位置或关键字指定。前者的例子是'sqlldrscott/tigerfoo';后一种情况的一个示例是'sqlldrcontrol=foouserid=scott/tiger'。位置指定参数的时间必须早于但不可迟于由关键字指定的参数。例如,允许'sqlldrscott/tigercontrol=foologfile=log',但是不允许'sqlldrscott/tigercontrol=foolog',即使参数'log'的位置正确。 |
------------------------------------------
二、导出spool
在SQLplus 或在SQl命令行 输入
spool c:\test\spool.txtselect st.employer_nm||'|'||st.salary||'|'||st.department from salary_tbl st where LEADER_NM='雇佣者4';
spool off就可以导出了

此时ctl 文件该怎么写才能正确导入呢 ?
其中 options skip 是选择跳过的行数 , 顺便使用支持中文导入的字符编码
options(skip=3)
load data
CHARACTERSET ZHS16GBK
infile 'spool.txt'
into table SALARY_TBL truncate
fields terminated by '|'(employer_nm ,salary ,department
)
二、外部表
外部表的数据不装入数据库中,数据库中只存储外部表的定义。实际数据位于操作系统中的平面文件中。外部表只读,可以通过select 进行查询。外部表可以由数据泵引擎生成的外部表。也可以通过文本文件生成的外部表
create table salary_tbl_external(employer_nm ,department ,salary ,leader_nm
)organization external -----指明外部表
(type oracle_datapump --利用数据泵来创建default directory MY_DIR --D:\DIRTEST1location ('sal1.dmp','sal2.dmp')
) parallelas select salary_tbl.employer_nm,salary_tbl.department,salary_tbl.salary,salary_tbl.leader_nm from salary_tbl
在MY_DIR 文件中有 SAL1.dmp 和SAL2.dmp文件。现在有了dmp文件可以通过外部表来创建外部表
create table salary_tbl_external2(employer_nm varchar2(20) ,department varchar2(20),salary number,leader_nm varchar2(20)
) organization external(type oracle_datapumpdefault directory MY_DIR --D:\DIRTEST1location ('sal1.dmp','sal2.dmp')
)利用文本文件来创建外部表 现有txt文件
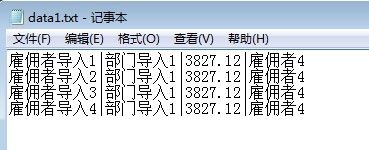
create directory C_test as 'C:\test';
--使用oracle_loader创建外部表,数据文件中每一行为数据行,字段按照 ‘|'划分
create table salary_tbl_external3(employer_nm varchar2(20) ,department varchar2(20),salary number,leader_nm varchar2(20)
) organization external(type oracle_loaderdefault directory C_test access parameters(records delimited by newline fields terminated by '|' )location ('data1.txt')
)select * from salary_tbl_external3就可以查询了。
注意: 如果在access parameters 中 注释一些没有用的代码,系统认为这是不符合规则的语句,会产生错误ORA-29913
这篇关于Oracle 原理:数据装载 ,SQLldr ,外部表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






