本文主要是介绍光谱数据处理:2.数据准确度评价指标的Python计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、计算相关系数R²
(1)定义介绍
相关系数 R²,又叫做决定系数,是一种用来衡量事物之间关系密切程度的指标。我们可以把它想象成一个打分系统,这个分数会告诉我们模型对数据的拟合程度有多好。分数范围是0到1。
(2)完整代码
首先,生成一组简单的线性相关的数据点;然后,通过sklearn库中的LinearRegression类来训练一个线性回归模型。r2_score函数用于计算模型的相关系数 R²,以评价模型对数据的拟合程度。最后,绘制原始数据和拟合线,并且显示 R² 值。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score# 设置随机数种子,确保每次运行程序时生成的随机数据都是一样的
np.random.seed(0)# 假设有波长这一个特征,和相对应的光谱测量值,生成100个样本的数据集
X = np.random.rand(100, 1) * 100 # 波长特征,假设范围从0到100
y = 5 * X.squeeze() + np.random.randn(100) * 10 # 真实值加上一些随机噪声# 初始化线性回归模型
model = LinearRegression()# 训练模型,即找到最佳拟合线
model.fit(X, y)# 使用模型进行预测
y_pred = model.predict(X)# 计算相关系数 R²,评价模型的拟合效果
r2 = r2_score(y, y_pred)# 绘制原始数据和预测结果的图表
plt.scatter(X, y, color='blue', label='Original Data') # 原始数据点
plt.plot(X, y_pred, color='red', label='Fit Line') # 拟合的直线
plt.title(f'Linear Regression Fit (R²: {r2:.2f})') # 标题,包含R²得分
plt.xlabel('Wavelength') # x轴标签
plt.ylabel('Spectral Measurement') # y轴标签
plt.legend() # 显示图例
plt.show() # 显示图表
(3)运行结果

二、计算交叉验证均方根误差RMSECV
(1)定义介绍
交叉验证均方根误差(RMSECV)是一个衡量模型预测精度的指标。为了通俗地解释这个概念,我们可以将其拆解成几个部分来理解:交叉验证(CV)、均方误差(MSE)和均方根误差(RMSE)。
首先,均方误差(MSE)是一种测量预测值和实际值差距大小的方法。你可以想象有一个靶子,你的任务是射箭,箭头落点的位置是你的预测值,靶心是实际值。每一次射箭,你的箭与靶心之间的距离就好比是预测值和实际值之间的误差。均方误差就是把所有箭与靶心的距离(误差)平方后求平均,这样可以确保误差总是正数,而且更重视那些离靶心远的箭(大误差)。
然后,均方根误差(RMSE)就是均方误差的平方根。继续用射箭的例子,如果我们计算了MSE,我们得到的是所有箭头与靶心距离平方值的平均数,但这个数是在平方后的尺度上,不是原本的距离尺度。所以,我们得取平方根来回到原来的距离尺度,这样就可以更直观地理解预测值和实际值之间的平均距离了。
最后,交叉验证(CV)是一种评估模型泛化能力的技术。想象你有一堆箭,而不是每次都用同一些箭射靶,你决定每次选择不同的箭来进行射击,这样可以确保每一支箭都有机会参与射击,并且每次射击都用不同的箭来评估你的射击技巧。在数据模型中,交叉验证就是把数据分成几部分,轮流使用其中一部分作为测试数据,其余作为训练数据,这样可以减少由于数据划分导致的偶然性,得到更可靠的模型评估。
所以,交叉验证均方根误差(RMSECV)就是在交叉验证过程中计算出的每一轮RMSE的平均值。这个平均值可以告诉我们,模型在不同的数据子集上的平均表现如何,而且因为是RMSE,它是在原始数据的尺度上的,更加直观。一个较低的RMSECV意味着模型的预测误差较小,模型的预测性能较好。
(2)完整代码
首先,用cross_val_score函数从sklearn.model_selection来实现交叉验证,并计算每个折叠的均方误差(MSE);然后,取均值并开平方根得到RMSECV;最后,绘图显示原始数据点和线性回归预测的结果并输出计算得到的RMSECV值。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score# 设置随机数种子,确保每次运行程序时生成的随机数据都是一样的
np.random.seed(0)# 模拟生成光谱数据,假设有波长这一个特征,和对应的光谱测量值,生成100个样本的数据集
X = np.random.rand(100, 1) * 100 # 波长特征,假设范围从0到100
y = 5 * X.squeeze() + np.random.randn(100) * 10 # 真实值加上一些随机噪声# 初始化线性回归模型
model = LinearRegression()# 这里的负数是因为cross_val_score默认计算的是负的均方误差
# 取负数再开方得到RMSECV
scores = cross_val_score(model, X, y, scoring='neg_mean_squared_error', cv=5)
rmsecv = np.sqrt(-scores.mean())# 训练模型,即找到最佳拟合线
model.fit(X, y)# 使用模型进行预测
y_pred = model.predict(X)# 绘制原始数据和预测结果的图表
plt.scatter(X, y, color='blue', label='Original Data') # 原始数据点
plt.plot(X, y_pred, color='red', label='Prediction') # 模型预测结果
plt.title(f'Linear Regression with RMSECV: {rmsecv:.2f}') # 图表标题
plt.xlabel('Wavelength') # x轴标签
plt.ylabel('Spectral Measurement') # y轴标签
plt.legend() # 显示图例
plt.show() # 显示图表# 输出RMSECV值
print(f'The RMSECV (Root Mean Squared Error of Cross-Validation) is: {rmsecv:.2f}')
(3)运行结果

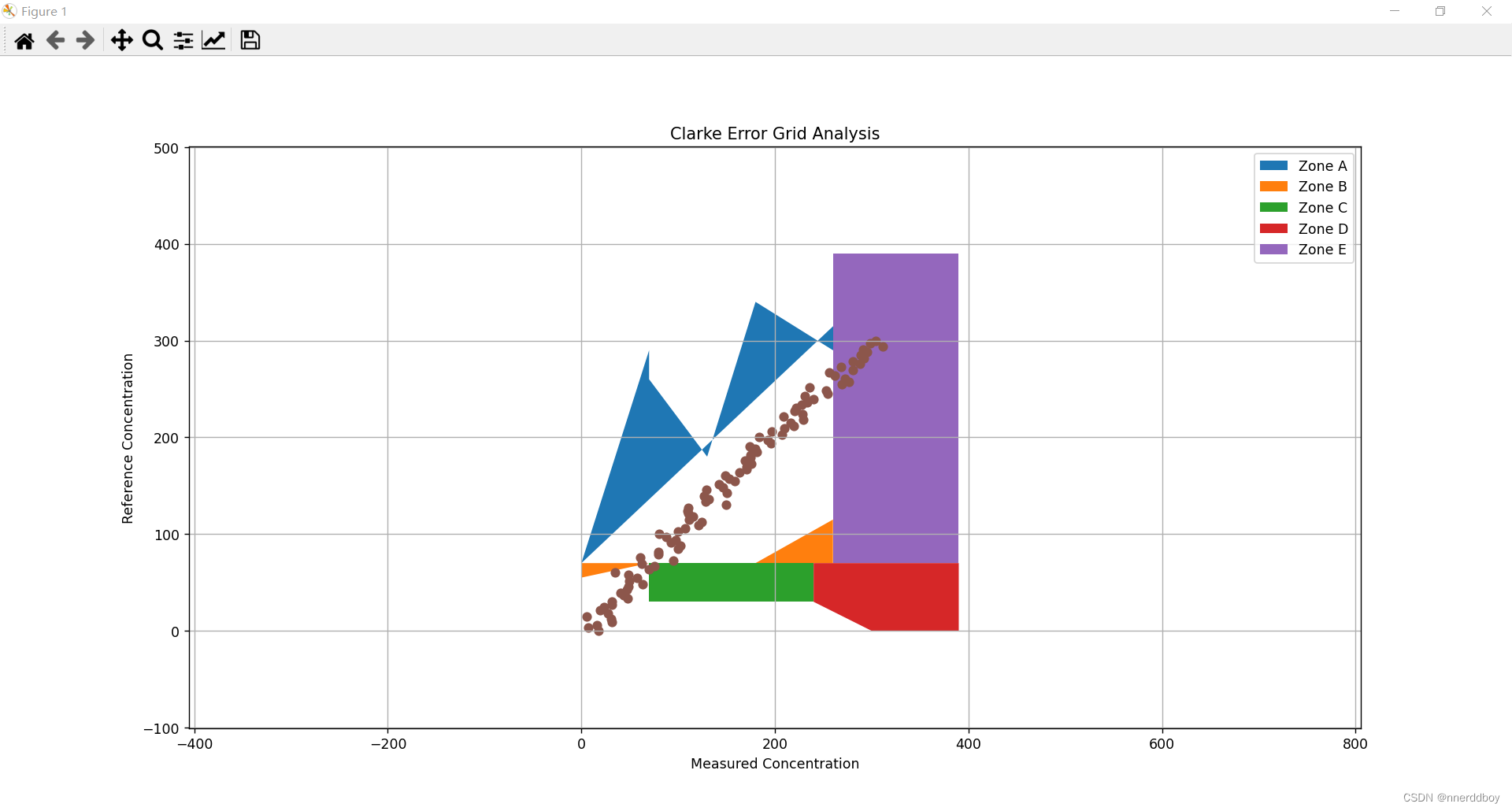
三、计算Clarke 误差网格
(1)定义介绍
Clarke误差网格是一种图形工具,它帮助我们理解两组测量数据之间的关系。想象一下,你有一个理想的测量设备,它总是能够给出完美的结果。现在,你用一个真实的设备去测量同样的东西,并得到了一系列的结果。你想知道这个真实设备测量的准确度如何。
这时候,Clarke误差网格就派上用场了。这个网格将图表分成了几个区域,每个区域都对应着不同级别的准确度:
- A区:这里的数据点表示真实设备的测量结果与理想设备非常接近,也就是说测量非常准确。
- B区:数据点在这里意味着真实设备的测量结果虽然不完美,但误差在可接受范围内。
- C区:在这个区域的数据点表明测量结果有一定的误差,这可能会导致一些问题。
- D区和E区:这两个区域的数据点表示真实设备的测量结果与理想设备相差很远,可能会造成严重的后果。
通过查看数据点在这个网格上的分布,我们可以快速判断出设备的测量准确性。如果大多数数据点都在A区,那么这个设备就是非常可靠的。如果数据点散布在C、D或E区,那么这个设备可能就不适合用于重要的测量任务。
简而言之,Clarke误差网格就像是一个成绩报告卡,它告诉你设备的表现如何,帮助你决定是否可以信任这个设备的测量结果。
(2)完整代码
计算Clarke 误差网格一般有以下四个步骤:
-
生成模拟数据:代码首先使用
numpy库生成了两组数据。reference_values是一组均匀分布在0到300之间的100个数值,模拟理想情况下的光谱测量值。measured_values是在reference_values的基础上加上了正态分布的随机噪声(均值为0,标准差为10)生成的,模拟实际的光谱测量值。 -
定义绘制Clarke误差网格的函数:
plot_clarke_error_grid函数负责创建Clarke误差网格,并在网格上绘制模拟数据点。函数内部首先定义了Clarke误差网格的五个区域(A, B, C, D, E)的边界点。然后,利用matplotlib库中的fill函数根据这些边界点填充网格区域的颜色,并用scatter函数将模拟的数据点绘制在图表上。 -
设置图表属性:在函数中设定了图表的标题、x轴和y轴的标签、图例、坐标轴等比例(使x轴和y轴的刻度保持一致)、x轴和y轴的显示范围以及网格线。
-
显示结果:最后,调用
plot_clarke_error_grid函数将模拟的参考值和测量值传入,运行函数以绘制并显示Clarke误差网格和数据点。结果是一个图表,显示了数据点在不同准确性区域的分布。
完整代码如下:
import matplotlib.pyplot as plt
import numpy as np# 模拟生成光谱数据
np.random.seed(0)
reference_values = np.linspace(0, 300, 100) # 参考光谱测量值
measured_values = reference_values + np.random.normal(0, 10, reference_values.shape) # 实际光谱测量值,附加一些误差# 绘制Clarke误差网格
def plot_clarke_error_grid(reference, measured):# Clarke错误网格的临界点定义grid_points = {'A': [(0, 70), (0, 70), (70, 290), (70, 260), (130, 180), (180, 340), (260, 290), (340, 390)],'B': [(0, 70), (0, 55), (70, 70), (180, 70), (260, 115), (260, 70)],'C': [(70, 70), (180, 70), (240, 70), (240, 30), (70, 30)],'D': [(240, 70), (240, 30), (300, 0), (390, 0), (390, 70)],'E': [(260, 70), (390, 70), (390, 390), (260, 390)]}# 绘制Clarke误差网格区域for zone in grid_points:points = np.array(grid_points[zone])plt.fill(points[:, 0], points[:, 1], label=f'Zone {zone}')# 绘制数据点plt.scatter(measured, reference, marker='o')plt.title('Clarke Error Grid Analysis')plt.xlabel('Measured Concentration')plt.ylabel('Reference Concentration')plt.legend(loc='upper right')plt.axis('equal')plt.xlim(0, 400)plt.ylim(0, 400)plt.grid(True)plt.show()# 运行Clarke误差网格分析
plot_clarke_error_grid(reference_values, measured_values)
(3)运行结果
这篇关于光谱数据处理:2.数据准确度评价指标的Python计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







