本文主要是介绍Flink Catalog 解读与同步 Hudi 表元数据的最佳实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 | 博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维码进入京东手机购书页面。 |
文章目录
- 1. Flink Catalog 的整体设计和各类具体实现
- 2. Flink 读写 Hudi 表并同步至 Hive Metastore 的方法
- 3. 最佳解决方案
- 4. 示例代码
在当前的大数据格局中,Spark / Hive / Flink 是最为主流的 ETL 或 Streaming 引擎,元数据方面,Hive Metastore 可以视为事实上的 Data Catalog 标准,而在数据湖存储格式上,又有 Hudi、Iceberg 这类新晋的框架,在这种复杂的格局下,用户希望能它们之间能相互打通,以便能根据应用场景灵活地选择技术栈,同时又不会出现技术上的“隔离”,一个非常典型的例子是:当我们选择了 Hudi 作为数据湖的统一存储格式后,我们希望不管是 Flink 还是 Spark (也包括 Hive)都能顺利读写 Hudi 表,这也暗含着“元数据最好统一存储在 Hive Metastore 中”这样的诉求,这非常普遍且典型的一种用户诉求,而我们这篇文章其实就是针对这个诉求给出解决方案。
1. Flink Catalog 的整体设计和各类具体实现
首先,我们要清楚地明白一点:Flink 是有自己的、完全独立的 Catalog 定义(接口)的,就像 Hive 设计并使用了自己的 Hive MetaStore 一样。Flink 在自已统一的 Catalog 定义(接口)下,提供了多种不同的实现,其实本质的差别主要是存储介质上的差异:
- 🗹 默认 Catalog(GenericInMemoryCatalog)
- 基于内存,Session 结束时,metadata 也会随之丢失,下次再使用需要重新建库、建表;
- 🗹 将元数据持久化到数据库中 (JdbcCatalog)
- 这就有点像 Hive Metastore 的实现方式了,但是要注意,只是性质上类似,metadata 的 schema 肯定是不一样的
- 🗹 将元数据持久化到 Hive Metastore 中(HiveCatalog)
- 这种方式要注意理解,它是把 Hive Metastore 当成了底层存储,通过调用 Hive Metastore 的 API 来读写 Flink 的 metadata;
- 同时,使用这种方式还能读写 Hive 中已有的 Hive 表,某种角度上看,有点类似在 Flink Catalog 和 Hive Metastore 之间做了“适配”;
- 鉴于 Hive Metestore 在大数据生态中的核心位置,将 Flink 的元数据统一到 Hive 的 Metastore 上也是一种必然地选择,不过,Flink Catalog 数据结构毕竟与 Hive 的 Catalog 结构有所不同,所以将大量 Flink 的 metadata 写入 Hive 会导致所谓的 “Hive 元数据污染” 问题(参考:《Flink 实时计算平台在知乎的演进》)
- 🗹 用户自定义 Catalog
- 既然 Flink 的 Catalog 基于接口设计的,那么用户自然可以开发自己的 Catalog 实现;
- 对于那些拥有内置元数据服务的数据湖框架,例如 Hudi 和 Iceberg,这是绝佳的元数据切入方式,通过这种形式,它们会开发自己的 Flink Catalog 实现,目的就在于为了和 Flink Catalog 机制无缝打通,让 Flink 能很好的读写这些格式内置的元数据,实际上,它们也确实这样做了
下图从本质上(类的继承关系)揭示了 Flink Catalog 的设计框架和各个实现之间的关系:
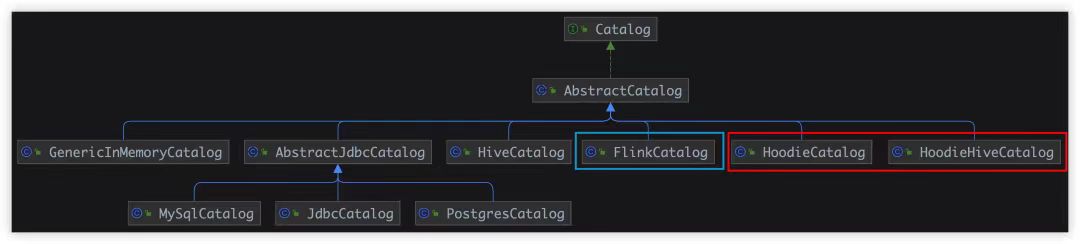
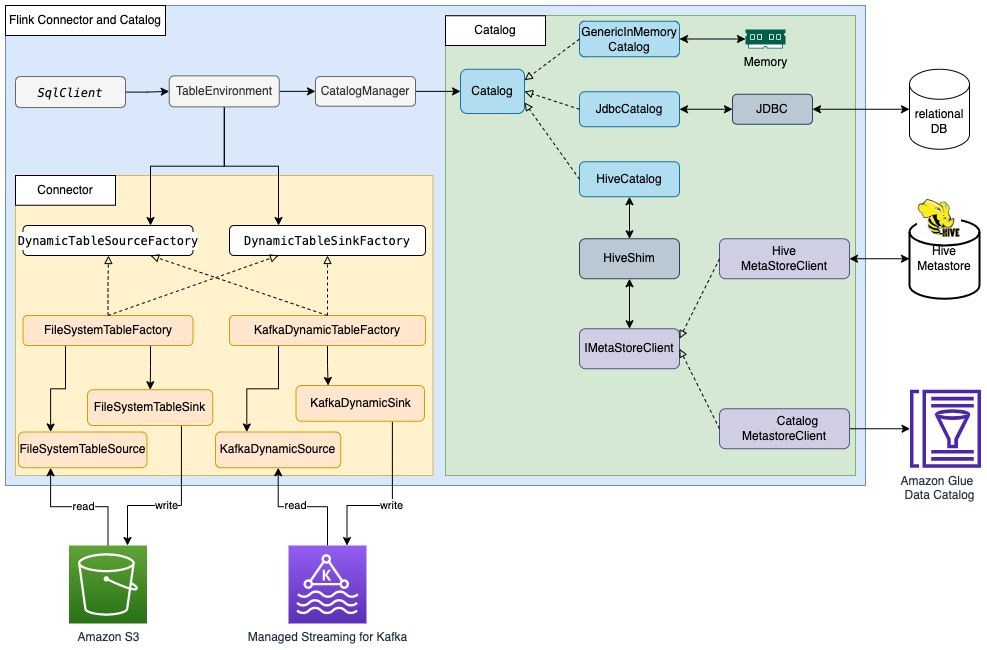
同样的,下图从更大的一个上下文中展示了 Flink 表种 Catalog 具体实现的工作场景:
2. Flink 读写 Hudi 表并同步至 Hive Metastore 的方法
存放 Hudi 的元数据有多种途径,本着不再发明轮子的态度,这两篇文章《Flink SQL操作Hudi并同步Hive使用总结》和 《Flink SQL通过Hudi HMS Catalog读写Hudi并同步Hive表》已经总结的非常全面和细致了,总结一下一共有以下几种途径:
① 在 Flink 的默认 Catalog 中创建 Hudi 表,不同步表格元数据到 Hive Metastore (不配置 hudi 表的 hive_sync.* 属性)
这一方案 Spark 和 Hive 都读取不到这张 Hudi 表,且 Flink 自己在 Session 关闭后也需要重新建表,所以,这一方案并没有实用价值。
② 在 Flink 的 Hive Catalog 中创建 Hudi 表,不同步表格元数据到 Hive Metastore (不配置 hudi 表的 hive_sync.* 属性)
这一方案是在 Flink SQL 中连通 Hive Metastore(即使用 HiveCatalog),直接在 Hive Metastore 中创建 Hudi 表,这样,原则上,Spark / Hive 都能发现这张 Hudi 表,并对其进行读写。但实际上,使用在这种模式下,Spark / Hive 是不能正常读写 Hudi 表的,因为该方法创建的 Hudi 表写入了大量的 Flink 特有的 metadata,同时又缺少了 Hive / Spark 必要的 Hudi 表的属性,所以 Spark / Hive 不能读写这种方式创建的 Hudi 表。简单地说,在这种方式下,Flink 只是将 Hive Metastore 当做一种底层的元数据存储服务,所以写入的元数据都是 Flink Catalog 风格的,并不会考虑任何与 Hive / Spark 元数据兼容的问题,所以 Spark / Hive 读不出这种方式创建的 Hudi 表就不难理解了。
③ 在 Flink 的默认 Catalog 中创建 Hudi 表,并同步表格元数据到 Hive Metastore (配置 hudi 表的 hive_sync.* 属性)
这一方案在 Flink 中创建的 Hudi 表的元数据能自动同步到 Hive Metastore,这样,Spark / Hive 就可以读写这张表了,但是,唯一不足的地方是:对于 Flink 这一端,具体说就是 Flink SQL Client,当 Session 关闭再重新打开后,Flink 的 Catalog 里原来的 Hudi 表就消失了,虽然可以通过注册 Hive Catalog 读到上次创建的 Hudi 表,但是,先后两次操作,SQL 会不一样,所以还是有一些瑕疵。说到底,这种方式是在混用 Flink Catalog 和 Hive Metastore。
④ 在 Flink 的 Hive Catalog 中创建 Hudi 表,并同步表格元数据到 Hive Metastore (配置 hudi 表的 hive_sync.* 属性)
这一方案和方案 2 很接近,通过主动同步 Hudi 元数据到 Hive Metastore 解决了 Hive / Spark 无法读写 Hudi 表的问题。不过,这一方案将势必在 Hive Metastore 中创建出至少两张以上的表(对于 MOR 表是 3 张),一张是 Flink 原生的 Hudi 表,另一张是通过 Hive Sync 同步出来的表,虽然两张表的数据是一份,但是元数据上确实是两张不同的表,且使用 Flink 时,只能读写 Flink 注册的表,使用 Hive / Spark 时,只能使用 Hive Sync 出来的表,虽然可以 work,但显然还是一种很别扭的方案
⑤ 使用 Hudi HMS Catalog ( HoodieHiveCatalog )
上述四种方案都有一定的局限性,为此,Flink / Hudi 社区专门针对 Hudi 的 metadata 开发了一个单独的 Flink Catalog 实现:HoodieHiveCatalog,这一方案从最底层上解决了元数据适配和共享的问题。接下来我们会详细介绍这种实现。
3. 最佳解决方案
在“Flink 读写 Hudi 表并同步至 Hive Metastore” 这件事情上,作为需求,最好的解决方案应该:在 Flink 中创建的 Hudi 表能自动被 Hive / Spark 发现和读写,鉴于 Hive Metastore 在大数据生态中的地位,元数据应该存储于 Hive Metastore 中,但不需要显式配置 Hive Sync,也不应存储两份以上的元数据,Flink / Hive / Spark 有统一的元数据视图,均可共同读写同一张 Hudi 表,而这就是 HoodieHiveCatalog 所要完成的任务。
从设计模式的角度看,本质上,HoodieHiveCatalog 是一个 “适配器”,它将 Flink Catalog 的元数据格式和 Hudi 的元数据格式以及 Hive Metastore 的格式做了完备的适配,这才得以实现三者的无缝集成!使得 Hudi 表元数据在 Flink / Hive / Spark 上做到的真正意义上的统一。下图非常细致地描绘了 HoodieHiveCatalog 的工作方式(Glue Data Catalog 部分不影响解读,可忽略):
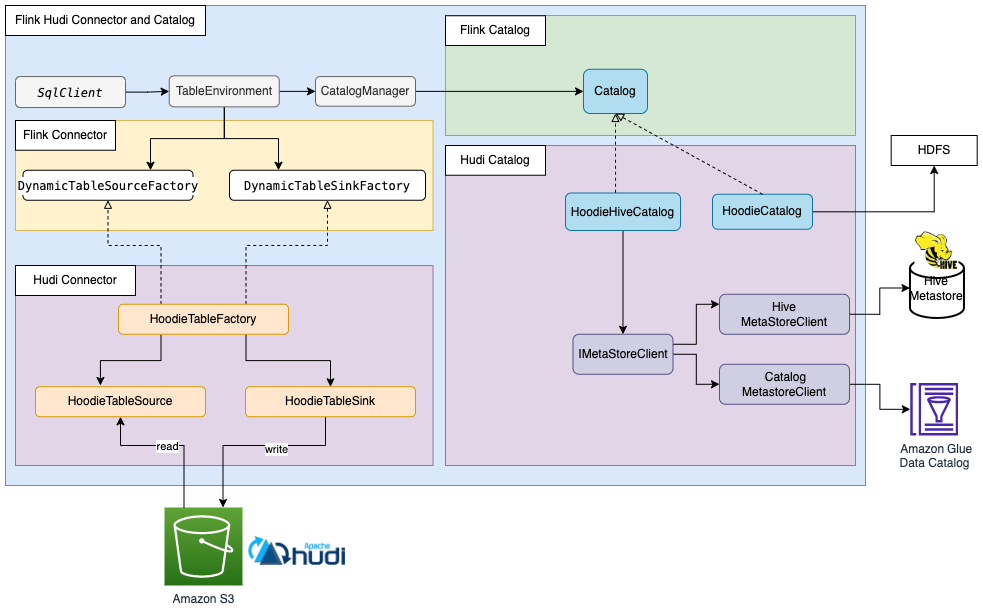
方案 5 自始至终只使用 Hive Metastore 一种存储介质,并面向 Hudi Metadata 的存储在 Flink Catalog 和 Hive Catalog 进行了适配,只存储一份元数据,而其他方案都是同时使用两套 Catalog,并通过 Hive Sync 尽量弥合两套 Catalog 之间的差异,总会遇到这样那样的不一致问题。
4. 示例代码
关于使用 Hudi HMS Catalog ( HoodieHiveCatalog ) 统一 Hudi 表在 Flink / Spark / Hive 上的元数据示例,我们已经在《CDC 整合方案:MySQL > Flink CDC + Schema Registry + Avro > Kafka > Hudi》 一文中给出了细致的演示和程序代码,请移步此文了解详情。
这篇关于Flink Catalog 解读与同步 Hudi 表元数据的最佳实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







