本文主要是介绍华为算法题 go语言或者ptython,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
package mainimport "fmt"func twoSum(nums []int, target int) []int {numMap := make(map[int]int) // 前一个是键,后一个int是值,map是映射// 遍历数组 nums,i 是当前元素的索引,num 是当前元素的值for i, num := range nums {complement := target - num// j:这是从 numMap 中获取的与 complement 对应的值if j, ok := numMap[complement]; ok {// []int{j, i} 是一个整数切片的初始化.返回一个包含两个整数的切片,第一个整数是 j,第二个整数是 ireturn []int{j, i}}numMap[num] = i}return nil
}func main() {nums1 := []int{2, 7, 11, 15}target1 := 9result1 := twoSum(nums1, target1)fmt.Println(result1)nums2 := []int{3, 2, 4}target2 := 6result2 := twoSum(nums2, target2)fmt.Println(result2)
}2
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
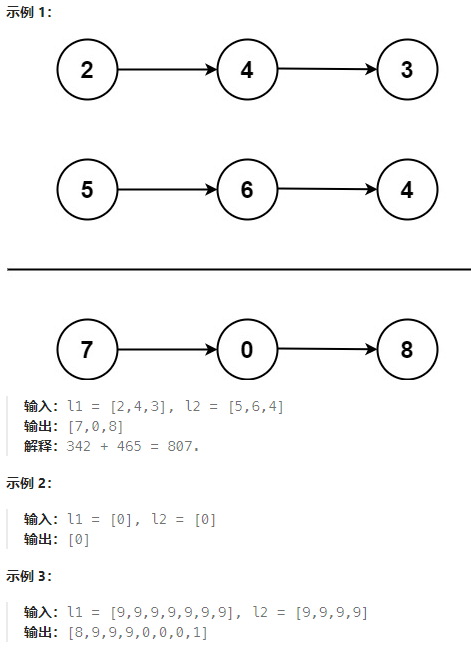
package mainimport "fmt"// 表示链表节点的数据结构
type ListNode struct {Val intNext *ListNode
}// 接受两个非空链表,表示两个非负整数,返回它们的和的链表
func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {// create 一个虚拟头节点dummyHead := &ListNode{}// create 一个指针current := dummyHead// 进位标志carry := 0// 遍历两个链表,直到两个链表都遍历完并且没有进位为止for l1 != nil || l2 != nil || carry > 0 {// 计算当前位的数字总和sum := carryif l1 != nil {sum += l1.Vall1 = l1.Next}if l2 != nil {sum += l2.Vall2 = l2.Next}// 更新进位 ,注意这里如果小于10carry就是0,否则为1carry = sum / 10// 创建新节点存储当前位的数字current.Next = &ListNode{Val: sum % 10}// 将指针移动到下一个节点current = current.Next}// 返回结果链表的头节点的下一个节点(跳过虚拟头节点)return dummyHead.Next
}// 用于打印链表的值,方便查看结果
func printLinkedList(node *ListNode) {for node != nil {fmt.Print(node.Val)if node.Next != nil {fmt.Print("->")}node = node.Next}fmt.Println()
}func main() {// 实例1l1 := &ListNode{Val: 2, Next: &ListNode{Val: 4, Next: &ListNode{Val: 3}}}l2 := &ListNode{Val: 5, Next: &ListNode{Val: 6, Next: &ListNode{Val: 4}}}result := addTwoNumbers(l1, l2)printLinkedList(result)
}3
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: s = “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: s = “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
假设我们有一个字符串:s = "abcabcbb"。
我们开始遍历这个字符串,使用一个“盒子”来存储不重复的字符。
- 我们从字符串的开头开始,第一个字符是 ‘a’,我们放入盒子中,盒子内有:
[a],目前盒子的长度为1。 - 接着是 ‘b’,我们放入盒子中,盒子内有:
[a, b],目前盒子的长度为2。 - 然后是 ‘c’,我们放入盒子中,盒子内有:
[a, b, c],目前盒子的长度为3。 - 然后又是 ‘a’,在这里我们发现盒子内已经有了 ‘a’,所以我们需要重新开始计算盒子。我们将 ‘a’ 上一次出现的位置后面的字符都去掉,得到新的盒子内容为
[b, c, a],目前盒子的长度为3。 - 然后是 ‘b’,我们放入盒子中,盒子内有:
[b, c, a],目前盒子的长度为3。 - 接着是 ‘c’,我们发现 ‘c’ 已经在盒子中了,所以我们需要重新开始计算盒子。我们将 ‘c’ 上一次出现的位置后面的字符都去掉,得到新的盒子内容为
[a, b, c],目前盒子的长度为3。 - 最后是 ‘b’,我们放入盒子中,盒子内有:
[a, b, c],目前盒子的长度为3。
我们遍历完整个字符串后,最长的不含重复字符的子串就是 “abc”,它的长度为 3。
package mainimport "fmt"
// start 和 i 分别表示当前不含重复字符的子串的起始位置和结束位置。lastI 表示字符上一次出现的位置。func lengthOfLongestSubstring(s string) int {// 使用 map 存储字符最后出现的位置lastOccurred := make(map[byte]int)start, maxLength := 0, 0// 遍历字符串for i, ch := range []byte(s) {// 如果字符已经出现过,并且出现位置在当前子串中if lastI, ok := lastOccurred[ch]; ok && lastI >= start {start = lastI + 1 // 更新子串起始位置}// 更新字符最后出现的位置lastOccurred[ch] = i// 更新最大子串长度if i-start+1 > maxLength {maxLength = i - start + 1}}return maxLength
}func main() {s1 := "abcabcbb"fmt.Println(lengthOfLongestSubstring(s1))
}
4
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
# 双斜杠 // 表示整数除法,它会将结果向下取整为最接近的整数
class Solution(object):def findMedianSortedArrays(self, nums1, nums2):""":type nums1: List[int] # 接受的第一个有序数组:type nums2: List[int] # 接受的第二个有序数组:rtype: float # 返回值为中位数的浮点数"""m = len(nums1) # 第一个数组的长度n = len(nums2) # 第二个数组的长度for num in nums2:nums1.append(num) # 将 nums2 中的所有元素添加到 nums1 中nums1.sort() # 将合并后的 nums1 数组进行排序i = len(nums1) # 合并后数组的长度if i % 2 == 0: # 如果数组长度为偶数a = nums1[i // 2] # 取中间两个数中的后一个数b = nums1[i // 2 - 1] # 取中间两个数中的前一个数k = (float(a) + b) / 2 # 计算中位数else: # 如果数组长度为奇数k = nums1[(i) // 2] # 取中间的那个数作为中位数return k # 返回中位数5
给你一个字符串 s,找到 s 中最长的回文子串。
如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
示例 1:
输入:s = “babad”
输出:“bab”
解释:“aba” 同样是符合题意的答案。
示例 2:
输入:s = “cbbd”
输出:“bb”
class Solution:def longestPalindrome(self, s: str) -> str:n = len(s) # 字符串长度if n < 2: # 如果字符串长度小于2,直接返回字符串本身return s# 创建一个包含 n 行的列表,每行包含 n 个元素,每个元素都是 Falsedp = [[False] * n for _ in range(n)] # 创建一个二维数组,用于存储子串是否为回文串的状态start, max_len = 0, 1 # 记录最长回文子串的起始位置和长度,默认为第一个字符和长度为1# 初始化长度为1和2的回文子串for i in range(n):dp[i][i] = Trueif i < n - 1 and s[i] == s[i + 1]:dp[i][i + 1] = Truestart = imax_len = 2# 从长度为3开始遍历,更新状态数组dpfor length in range(3, n + 1):for i in range(n - length + 1):j = i + length - 1 # 子串的结束位置if s[i] == s[j] and dp[i + 1][j - 1]: # 如果子串两端字符相等且去掉两端字符后仍为回文串dp[i][j] = Truestart = i # 更新最长回文子串的起始位置max_len = length # 更新最长回文子串的长度# start 是子串的起始索引。
# start + max_len 是子串的结束索引(不包括该索引对应的字符)。
# 因此,s[start:start + max_len] 表示从字符串 s 中提取子串,起始索引为 start,结束索引为 start + max_len - 1,
# 即提取了从 start 开始到 start + max_len - 1(包括起始索引,不包括结束索引)的子串。return s[start:start + max_len] # 返回最长回文子串6
这篇关于华为算法题 go语言或者ptython的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



