本文主要是介绍OpenShift 数据持久化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
容器的一个特点是当容器退出后,其内部所有的数据和状态就会丢失。对于无状态应用来说这不是问题,但对于有状态的应用来说则是重要数据丢失的重大问题。
OpenShift中为了满足数据持久化需求,采用了 kubernates 的 persistence volume 框架,在 kubenates 中的这个 persistence volume 子系统则为集群用户和管理员提供了一套API,这套API对底层的持久化存储进行了封装,并提供了两个API资源对象,分别是 持久化卷 PersistenceVolume(PV) 和 持久化卷请求PersistenceVolumeClain(PVC)。
持久化卷定义了具体的储存的连接信息,如NFS服务器的地址和端口、卷的位置、卷的大小及访问方式。在OpenShift中,集群管理员会定义一系列的持久化卷,形成一个持久化卷的资源池。
持久化卷请求是指当用户部署有持久化需求的容器应用时,用户需要先创建一个持久化卷请求。在这个请求中,用户申明所需文化储存的大小及访问方式。Kubernetes将负现根据用户的持久化请求找到匹配需求的持久化卷进行对接。最终的结果是容器启动后,持久化卷定义的后端存储将会被挂载到容器的指定目录。
持久化卷的生命周期
持久化卷的生命周期一共分为“供给”、“绑定”、“使用”、“回收” 及 “释放” 五个阶段。
1、供给
在kubernetes中,储存资源的供给分为两种类型:静态供给和动态供给。对于静态供给,集群管理员会创建一些持久化卷,形成一个持久化卷的资源池。动态供给是集群所在的基础设施云根据需求动态地创建出持久化卷,如 OpenStack、Amazon WebService。
这些资源池中的持久化卷将会与具体的持久化卷请求进行对接。下面是一个持久化卷的定义示例:
| apiVersion: v1 kind: PersistentVolume #指定资源模板类型 metadata: name: pv01 #指定PV名称 spec: capacity: storage: 2Gi #指定PV的可用大小 accessModes: - ReadWriteMany #指定访问模式 nfs: #指定使用nfs path: /var/nfs-data/pv01 #指定NFS上的挂载目录 server: 192.168.40.141 persistentVolumeReclaimPolicy: Retain #指定数据回收策略 |
访问方式是描述持久化卷的访问特性,目前有三种访问方式可供选择:
- ReadWriteOnce:可读可写,只能被一个Node节点挂载
- ReadWriteMany:可读可写,可以被多个Node节点挂载
- ReadOnlyMany:只读,能被多个Node节点挂载
2、绑定
用户在部署容器应用时会定义持久化卷请求。用户在持久化卷请求中声明需要的存储资源的特性,如大小和访问方式。Kubernetes负责在持久化卷的资源池中寻找配置的持久化卷对象,并将持久化卷请求与目标持久化卷进行对接。这时持久化卷和持久化卷请求的状态都将变成Bound,即绑定状态。
下面是一个持久化卷请求的定义示例:
| apiVersion: v1 kind: PersistentVolumeClaim metadata: name: app-cli #PVC名称 spec: accessModes: - ReadWriteMany #PVC存储访问模式 resources: requests: storage: 2Gi #请求存储大小 |
3、使用
在用户部署容器时会在Deployment Config的容器定义中指定Volume的挂载点,并将这个挂载点和持久化卷请求关联。当容器启动时,持久化卷指定的后端存储被挂载到容器定义的挂载点上。应用在容器内部运行,数据通过挂载点最终写入后端存储中,从而实现持久化。
| oc volume dc/app-cli --add \ --type=persistentVolumeClaim \ --claim-name=app-cli \ --mount-path=/opt/app-root/src/uploads |
4、释放
当应用下线不再使用储存时,可以删除相关的持久化卷请求,这样持久化卷的状态就会变成released,即释放。
5、回收
当持久化卷的状态变为released后,kubernetes将根据持久化卷定义的回收策略回收持久化卷。当前支持的回收策略有三种:
- Retaim:保留数据,人工回收持久化卷。
- Recycle:通过执行 rm -rf 删除卷上的所有数据。目前只有NFS及Host Path 支持这种方式。
- Delete:动态地删除后端存储。该模式需要下层IaaS的支持,目前AWS EBS、GCE PD 及 OpenStack Cinder 支持这种模式。
以上内容摘子《开源容器云OpenShift 构建基于Kubernetes的企业应用云平台》
配置实例 :
0、前提条件
由于本例采用的是NFS,因此在操作之前请先确保NFS已经配置好。
1、创建持久化卷
编辑持久化卷配置文件 pv01.yaml ,如下所示:
| apiVersion: v1 kind: PersistentVolume #指定资源模板类型 metadata: name: pv01 #指定PV名称 spec: capacity: storage: 2Gi #指定PV的可用大小 accessModes: - ReadWriteMany #指定访问模式 nfs: #指定使用nfs path: /var/nfs-data/pv01 #指定NFS上的挂载目录 server: 192.168.40.141 persistentVolumeReclaimPolicy: Retain #指定数据回收策略 |
创建持久化卷,命令如下:
| [root@ocp ~]# oc --config ~/admin.kubeconfig create -f pv01.yaml persistentvolume "pv01" created |
创建完毕后,通过 oc get pv 查看刚创建成功的持久化卷,命令如下:
| [root@ocp ~]# oc get pv |
结果如下:

2、创建持久化卷请求
编辑持久化卷请求配置文件 app-cli-pvc.yaml ,如下所示:
| apiVersion: v1 kind: PersistentVolumeClaim metadata: name: app-cli #PVC名称 spec: accessModes: - ReadWriteMany #PVC存储访问模式 resources: requests: storage: 2Gi #请求存储大小 |
创建持久化卷请求,命令如下:
| [root@ocp ~]# oc --config ~/admin.kubeconfig create -f app-cli-pvc.yaml persistentvolumeclaim "app-cli" created |
创建完毕后,通过 oc get pvc 查看刚创建成功的持久化卷请求,命令如下:
| [root@ocp ~]# oc get pvc |
结果如下:

同时再次查看 pv 的状态,其已经变成 Bound了。

3、关联持久化卷请求
通过如下命令为app-cli项目与持久化卷请求进行关联,命令如下:
| oc volume dc/app-cli --add \ --type=persistentVolumeClaim \ --claim-name=app-cli \ --mount-path=/opt/app-root/src/uploads |
结果如下:

使用 oc describe dc/app-cli 查看新的配置信息:
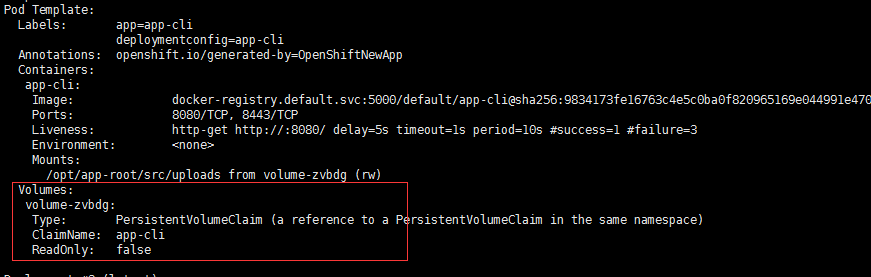
四、测试
在nfs server对应的挂载目录下创建一个文件,然后通过oc rsh 连接到app-cli容器中,看文件是否能在 /opt/app-root/src/uploads 目录下显示 。
这篇关于OpenShift 数据持久化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





