本文主要是介绍MPI Maelstrom MPI 大漩涡(最短路Dijkstra算法详解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MPI Maelstrom MPI 大漩涡
目录
MPI Maelstrom MPI 大漩涡
题意描述
解题思路
注意 :里面我们会用到 atoi()函数
AC
BIT has recently taken delivery of their new supercomputer, a 32 processor Apollo Odyssey distributed shared memory machine with a hierarchical communication subsystem. Valentine McKee's research advisor, Jack Swigert, has asked her to benchmark the new system.
``Since the Apollo is a distributed shared memory machine, memory access and communication times are not uniform,'' Valentine told Swigert. ``Communication is fast between processors that share the same memory subsystem, but it is slower between processors that are not on the same subsystem. Communication between the Apollo and machines in our lab is slower yet.''
``How is Apollo's port of the Message Passing Interface (MPI) working out?'' Swigert asked.
``Not so well,'' Valentine replied. ``To do a broadcast of a message from one processor to all the other n-1 processors, they just do a sequence of n-1 sends. That really serializes things and kills the performance.''
``Is there anything you can do to fix that?''
``Yes,'' smiled Valentine. ``There is. Once the first processor has sent the message to another, those two can then send messages to two other hosts at the same time. Then there will be four hosts that can send, and so on.''
``Ah, so you can do the broadcast as a binary tree!''
``Not really a binary tree -- there are some particular features of our network that we should exploit. The interface cards we have allow each processor to simultaneously send messages to any number of the other processors connected to it. However, the messages don't necessarily arrive at the destinations at the same time -- there is a communication cost involved. In general, we need to take into account the communication costs for each link in our network topologies and plan accordingly to minimize the total time required to do a broadcast.''
Input
The input will describe the topology of a network connecting n processors. The first line of the input will be n, the number of processors, such that 1 <= n <= 100.
The rest of the input defines an adjacency matrix, A. The adjacency matrix is square and of size n x n. Each of its entries will be either an integer or the character x. The value of A(i,j) indicates the expense of sending a message directly from node i to node j. A value of x for A(i,j) indicates that a message cannot be sent directly from node i to node j.
Note that for a node to send a message to itself does not require network communication, so A(i,i) = 0 for 1 <= i <= n. Also, you may assume that the network is undirected (messages can go in either direction with equal overhead), so that A(i,j) = A(j,i). Thus only the entries on the (strictly) lower triangular portion of A will be supplied.
The input to your program will be the lower triangular section of A. That is, the second line of input will contain one entry, A(2,1). The next line will contain two entries, A(3,1) and A(3,2), and so on.
Output
Your program should output the minimum communication time required to broadcast a message from the first processor to all the other processors.
“由于 Apollo 是分布式共享内存机器,内存访问和通信时间并不统一,”瓦伦丁告诉斯威格特。``共享同一内存子系统的处理器之间的通信速度很快,但不在同一子系统上的处理器之间的通信速度较慢。阿波罗和我们实验室机器之间的通信还比较慢。” “
阿波罗的消息传递接口 (MPI) 端口如何工作?”斯威格特问道。
“不太好,”瓦伦丁回答。``要将消息从一个处理器广播到所有其他 n-1 个处理器,它们只需执行 n-1 次发送的序列。这真的会连载事情并扼杀表演。
” “你有什么办法可以解决这个问题吗?
” “是的,”瓦伦丁笑着说。``有。一旦第一个处理器将消息发送给另一个处理器,这两个处理器就可以同时向其他两个主机发送消息。然后将有四台主机可以发送,依此类推。''
``啊,所以你可以将广播作为二叉树进行!''
``并不是真正的二叉树——我们应该利用我们网络的一些特殊功能。我们拥有的接口卡允许每个处理器同时向与其相连的任意数量的其他处理器发送消息。然而,消息不一定同时到达目的地——这涉及到通信成本。一般而言,我们需要考虑网络拓扑中每个链路的通信成本,并相应地进行计划以最大限度地减少广播所需的总时间。”
输入
输入的其余部分定义了一个邻接矩阵 A。邻接矩阵是正方形,大小为 nx n。它的每个条目将是一个整数或字符 x。A(i,j) 的值表示直接从节点 i 向节点 j 发送消息的费用。A(i,j) 的 x 值表示消息不能直接从节点 i 发送到节点 j。
请注意,节点向自身发送消息不需要网络通信,因此 A(i,i) = 0 for 1 <= i <= n。此外,您可以假设网络是无向的(消息可以以相同的开销沿任一方向传播),因此 A(i,j) = A(j,i)。因此,将只提供 A 的(严格的)下三角部分的条目。
程序的输入将是 A 的下三角部分。也就是说,输入的第二行将包含一个条目 A(2,1)。下一行将包含两个条目,A(3,1) 和 A(3,2),依此类推。
输出
Sample Input
5
50
30 5
100 20 50
10 x x 10Sample Output
35题意描述:本题就是第一行给你多个处理器,接下来的几行就是1-2、1-3、2-3...所用的时间,然后找第一个处理器到所有处理器所需的最短时间。具体如下:
拿题中的数据来说:
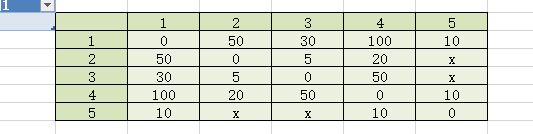
然后我们得到的35就是1-3-2 (30+5)和1-5-4(10+10);35>20即取为35,题目的意思就是就是一个处理器可以同时传给多个处理器,我们只需要传给时间最短的那个,一直到所有的处理器都被传到了,然后找到传达时间最长的输出。
解题思路:很明显是一个从一个点到所有点的最短路问题,其中x表示此路不通,所有我们还要利用字符串记录数据和字符,如果是字符的话直接把那条路的值初始化一个如果是数字的话就利用atoi函数把它转化成数字就可以了,本题我用了dijkstra算法来求,只需要最后加一个判断条件输出最短路里面最大的那个值就可以了。
注意:里面我们会用到 atoi()函数
atoi()函数原型为: int atoi(char *str),用途是将字符串转换成一个整数值,str是待转化成整数值的字符串.成功则返回转化后的整数值,失败返回0.具体看代码
AC:
#include<stdio.h> #include<string.h> #include<stdlib.h> #define N 110 int inf=999999,n; int e[N][N],dis[N],book[N]; void dijkstra() {int u,v,min;//初始化数组1到n的路程 for(int i=1;i<=n;i++)dis[i]=e[1][i];//book数组初始化 for(int i=1;i<=n;i++)book[i]=0;book[1]=1;//顶点为1//算法 for(int i=1;i<=n-1;i++){min=inf;for(int j=1;j<=n;j++){if(book[j]==0&&dis[j]<min){min=dis[j];u=j;}}book[u]=1;for(v=1;v<=n;v++){if(e[u][v]<inf){if(dis[v]>dis[u]+e[u][v]&&book[v]==0)dis[v]=dis[u]+e[u][v];}} } } int main(void) {while(~scanf("%d",&n)){char s[N];for(int i=1;i<=n;i++){for(int j=1;j<i;j++){scanf("%s",s);if(s[0]=='x')e[i][j]=e[j][i]=inf;elsee[i][j]=e[j][i]=atoi(s);//把参数 s所指向的字符串转换为一个整数}}dijkstra();//可别忘了 int maxx=-1;for(int i=1;i<=n;i++)//找里面所用时间最多的 {if(dis[i]>maxx)maxx=dis[i];}printf("%d\n",maxx);}return 0; }
这篇关于MPI Maelstrom MPI 大漩涡(最短路Dijkstra算法详解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





