本文主要是介绍记 350亿数据从 es 迁移到 ClickHouse 遇到的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一次:es 读取速度快,ClickHouse 插入速度慢,导致ClickHouse CPU和内存压力缓慢上升,最终打爆,于是读与写分离,这里对 es 读取功能加了速度控制功能,在 scrollid 不到期的情况下,能够动态调整速度两边保持平衡。
第二次:ClickHouse 每次插入的数据少,然后插入次数比较频繁,会报错too many parts,这里推荐每批次插入20-50万条数据最佳,否则会导致ClickHouse 频繁的数据合并,我这边读 es 线程每次 scroll 65000 条记录,写 ClickHouse 线程开了 100 个,判断队列长度大于 20 万的时候,一次全部取出,然后插入 ClickHouse。
如果报错如下错误,问了腾讯云,也是加大每批次的插入数据条数,减少与 CK 的交互次数,因为小文件过多,后台就会生成很多的 merge 任务。
Table is in readonly mode
- 问题现象:在笔者的项目环境下,由于存在大数据量的数据写入(200MB/s以上的写入速度),时常会在clickhouse-server的日志中看到
Table is in readonly mode的告警信息。 - 问题原因:翻阅资料后发现这其实是很多人都会遇到的一个问题,大体原因当然是和zk的处理性能相关,随着写入数据量的增多,zk的log和snapshot文件会不断膨胀,有时就会出现zk服务不可用的情况,而clickhouse的ReplicatedMergeTree又强依赖于zk,一旦zk不可用,为了保证数据的一致性,系统就会进行“写保护”,出现上述提示。
- 解决办法:
- 方案1:调整use_minimalistic_part_header_in_zookeeper参数; 网上有些朋友说是调整这个参数可以减少写入zk日志的数据量,但因为我们使用的是21的版本,此版本默认这个参数已经是开启了,因此这个方案对我们实际无效。
- 方案2:一个CH集群使用多个zk集群来提供服务; 这属于压力转移的策略,我们最后也无奈使用了这种办法,当然能解决问题,但带来的副作用就是zk集群运维管理成本的上升。
第三次:ClickHouse 插入无法部分成功,statement execute 失败之后,事务 context 会断开,会导致你 commit 的时候,整体失败,因为每次我都插入20-50万条记录,其中一两条数据异常会导致其他几十万数据也插入失败,最终导致插入10亿条数据的时候有几百万数据未插入,
这里我的方案是,statement execute 失败之后,不立即回滚,跑完所有语句,然后记录所有失败的语句,最后回滚事务,然后再重启一个事务,剔除异常的数据之后,再跑一次,那么就会只有少量失败记录插入失败,把这些失败数据写入 redis 集合,后续再处理。
第四次:es 按月分索引,读取数据 scroll 默认按 _doc 排序,这个查询效率是最高的,但是因为不是按照时间序排的,取出来的数据可能分布在不同的天,而 ClickHouse 是按照天来建立 partition,这样就导致了,每次插入的 50万数据,会分配到 N 个分区,由于 ClickHouse 的合并是按照分区来的,这样就导致每次插入需要合并 N 个分区,ck 压力暴增,最终拒绝服务,所以这里需要按照时间排序来 scroll es 数据,这样子,每次插入的数据,以及最近一段时间插入的数据,基本上都在同一天,提升了 ClickHouse 合并效率。
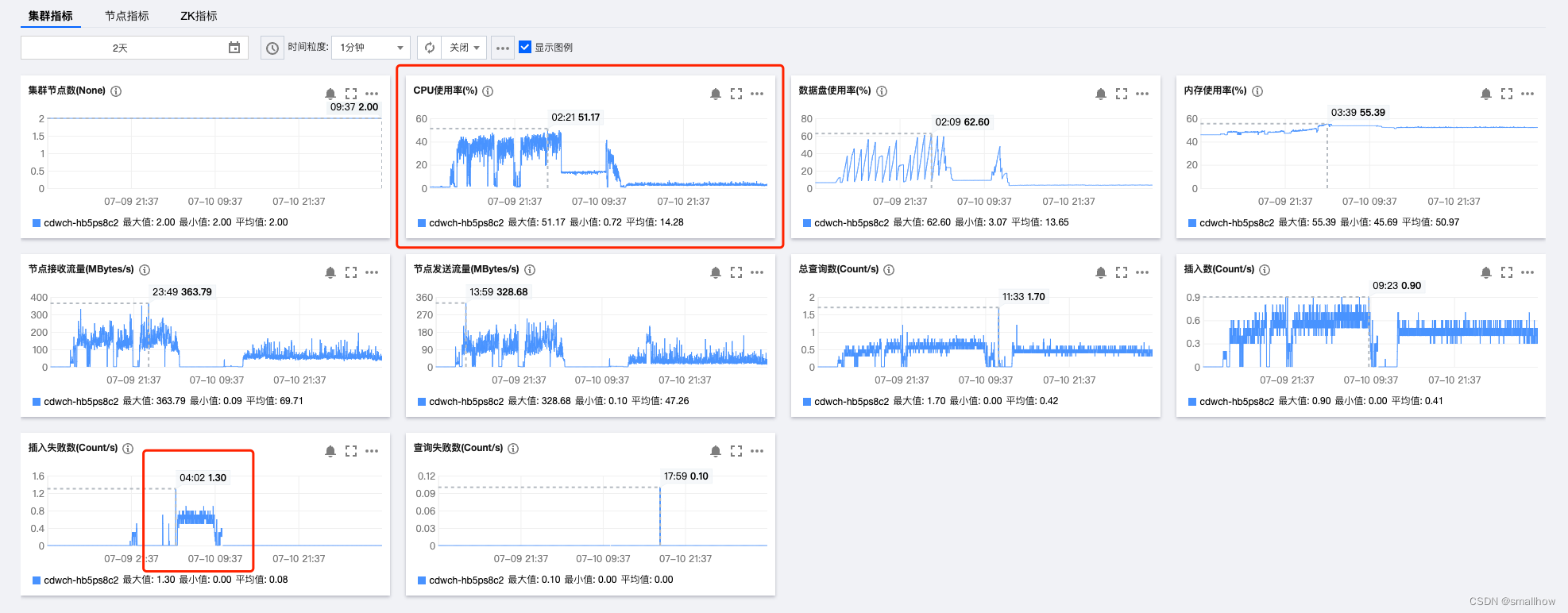
修改前每分钟 600万插入,CPU使用率在高位运行,说明一直在合并数据,修改后每分钟插入 400万数据,会慢一些,但是 CPU 一直在 10% 以下。
从上图还可以看出,之前的数据插入,会一直写到热盘,并且等合并完成之后,才会合并数据并迁移到冷盘,优化之后,会持续合并数据到冷盘,热盘的整体使用率一直稳定在低位。
迁移程序也因为数据处理速度快,避免了数据堆积,内存占用大的问题。
这篇关于记 350亿数据从 es 迁移到 ClickHouse 遇到的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









