本文主要是介绍Softmax的硬件友好型替代品;1-bit量化感知训练;基于LLM的数据可视化;视觉概念驱动的图像生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文首发于公众号:机器感知
Softmax的硬件友好型替代品;1-bit量化感知训练;基于LLM的数据可视化;视觉概念驱动的图像生成
ConSmax: Hardware-Friendly Alternative Softmax with Learnable Parameters
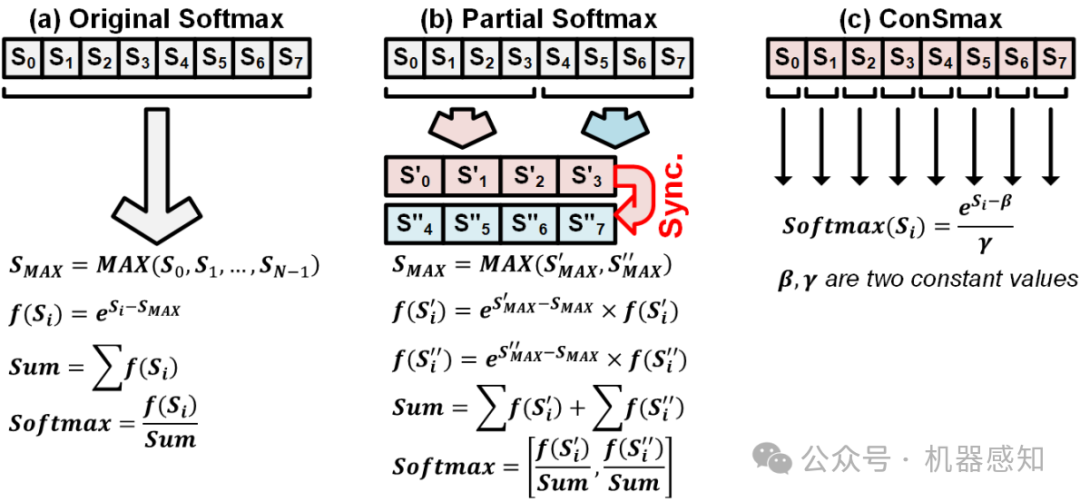
The self-attention mechanism sets transformer-based large language model (LLM) apart from the convolutional and recurrent neural networks. Despite the performance improvement, achieving real-time LLM inference on silicon is challenging due to the extensively used Softmax in self-attention. Apart from the non-linearity, the low arithmetic intensity greatly reduces the processing parallelism, which becomes the bottleneck especially when dealing with a longer context. To address this challenge, we propose Constant Softmax (ConSmax), a software-hardware co-design as an efficient Softmax alternative. ConSmax employs differentiable normalization parameters to remove the maximum searching and denominator summation in Softmax. It allows for massive parallelization while performing the critical tasks of Softmax. In addition, a scalable ConSmax hardware utilizing a bitwidth-split look-up table (LUT) can produce lossless non-linear operation and support mix-precision computing. It further facilitates efficient LLM inference. Experimental results show that ConSmax achieves a minuscule power consumption of 0.43 mW and area of 0.001 mm2 at 1-GHz working frequency and 22-nm CMOS technology. Compared to state-of-the-art Softmax hardware, ConSmax results in 14.5x energy and 14.0x area savings with a comparable accuracy on a GPT-2 model and the WikiText103 dataset.
OneBit: Towards Extremely Low-bit Large Language Models
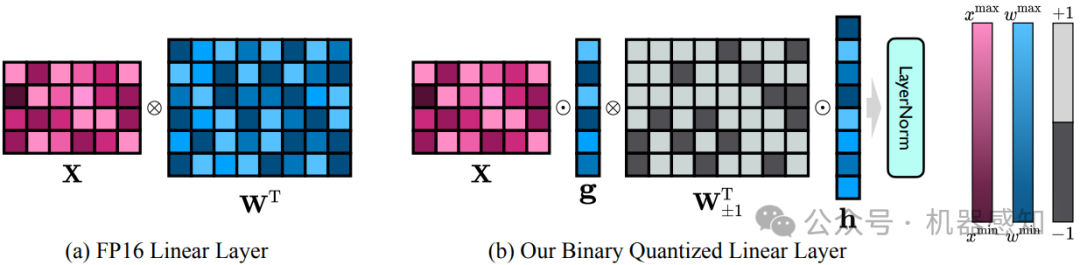
Model quantification uses low bit-width values to represent the weight matrices of models, which is a promising approach to reduce both storage and computational overheads of deploying highly anticipated LLMs. However, existing quantization methods suffer severe performance degradation when the bit-width is extremely reduced, and thus focus on utilizing 4-bit or 8-bit values to quantize models. This paper boldly quantizes the weight matrices of LLMs to 1-bit, paving the way for the extremely low bit-width deployment of LLMs. For this target, we introduce a 1-bit quantization-aware training (QAT) framework named OneBit, including a novel 1-bit parameter representation method to better quantize LLMs as well as an effective parameter initialization method based on matrix decomposition to improve the convergence speed of the QAT framework. Sufficient experimental results indicate that OneBit achieves good performance (at least 83% of the non-quantized performance) with robust training processes when only using 1-bit weight matrices.
LoRETTA: Low-Rank Economic Tensor-Train Adaptation for Ultra-Low-Parameter Fine-Tuning of Large Language Models
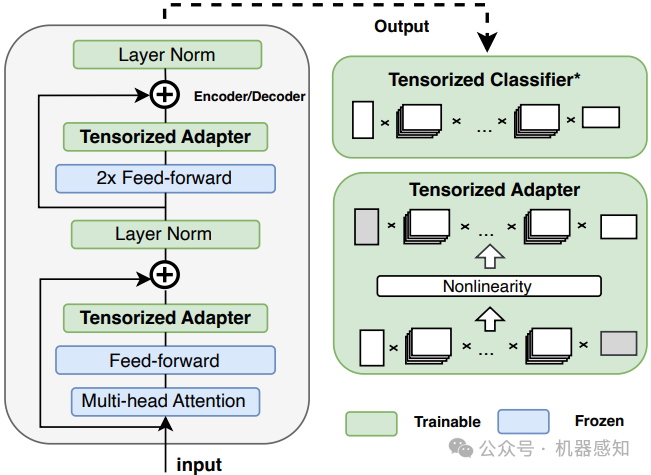
Various parameter-efficient fine-tuning (PEFT) techniques have been proposed to enable computationally efficient fine-tuning while maintaining model performance. However, existing PEFT methods are still limited by the growing number of trainable parameters with the rapid deployment of Large Language Models (LLMs). To address this challenge, we present LoRETTA, an ultra-parameter-efficient framework that significantly reduces trainable parameters through tensor-train decomposition. Specifically, we propose two methods, named {LoRETTA}$_{adp}$ and {LoRETTA}$_{rep}$. The former employs tensorized adapters, offering a high-performance yet lightweight approach for the fine-tuning of LLMs. The latter emphasizes fine-tuning via weight parameterization with a set of small tensor factors. LoRETTA achieves comparable or better performance than most widely used PEFT methods with up to $100\times$ fewer parameters on the LLaMA-2-7B models. Furthermore, empirical results demonstrate that the proposed method effectively improves training efficiency, enjoys better multi-task learning performance, and enhances the anti-overfitting capability. Plug-and-play codes built upon the Huggingface framework and PEFT library will be released.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
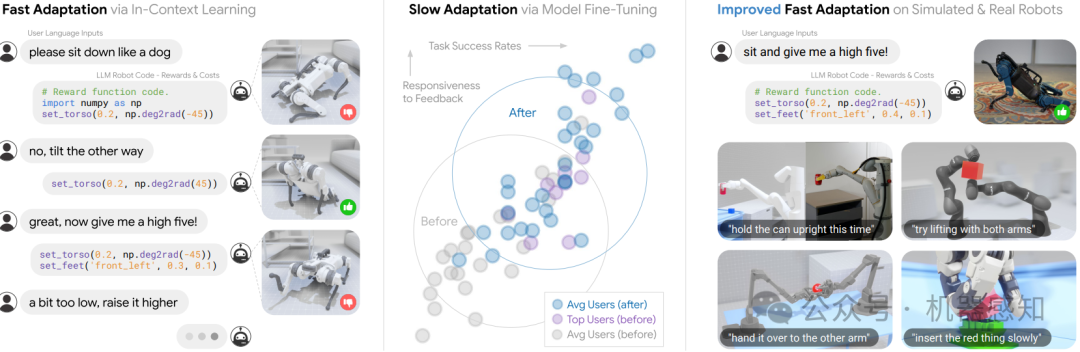
Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
MatPlotAgent: Method and Evaluation for LLM-Based Agentic Scientific Data Visualization
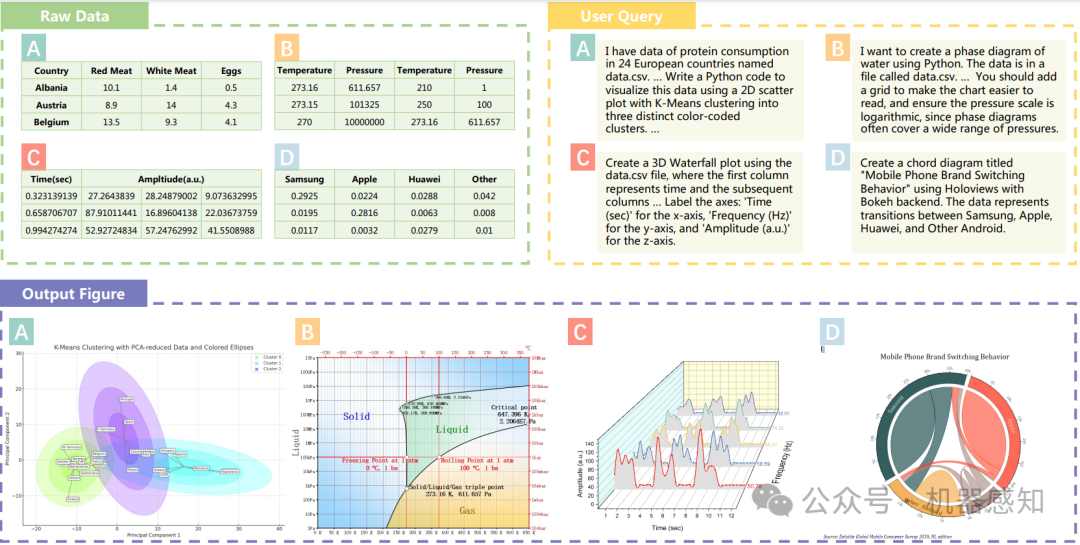
Scientific data visualization plays a crucial role in research by enabling the direct display of complex information and assisting researchers in identifying implicit patterns. Despite its importance, the use of Large Language Models (LLMs) for scientific data visualization remains rather unexplored. In this study, we introduce MatPlotAgent, an efficient model-agnostic LLM agent framework designed to automate scientific data visualization tasks. Leveraging the capabilities of both code LLMs and multi-modal LLMs, MatPlotAgent consists of three core modules: query understanding, code generation with iterative debugging, and a visual feedback mechanism for error correction. To address the lack of benchmarks in this field, we present MatPlotBench, a high-quality benchmark consisting of 100 human-verified test cases. Additionally, we introduce a scoring approach that utilizes GPT-4V for automatic evaluation. Experimental results demonstrate that MatPlotAgent can improve the performance of various LLMs, including both commercial and open-source models. Furthermore, the proposed evaluation method shows a strong correlation with human-annotated scores.
Visual Concept-driven Image Generation with Text-to-Image Diffusion Model
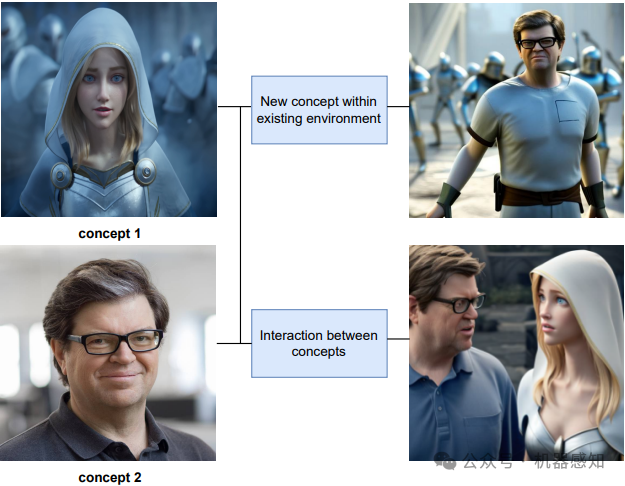
Text-to-image (TTI) diffusion models have demonstrated impressive results in generating high-resolution images of complex and imaginative scenes. Recent approaches have further extended these methods with personalization techniques that allow them to integrate user-illustrated concepts (e.g., the user him/herself) using a few sample image illustrations. However, the ability to generate images with multiple interacting concepts, such as human subjects, as well as concepts that may be entangled in one, or across multiple, image illustrations remains illusive. In this work, we propose a concept-driven TTI personalization framework that addresses these core challenges. We build on existing works that learn custom tokens for user-illustrated concepts, allowing those to interact with existing text tokens in the TTI model. However, importantly, to disentangle and better learn the concepts in question, we jointly learn (latent) segmentation masks that disentangle these concepts in user-provided image illustrations. We do so by introducing an Expectation Maximization (EM)-like optimization procedure where we alternate between learning the custom tokens and estimating masks encompassing corresponding concepts in user-supplied images. We obtain these masks based on cross-attention, from within the U-Net parameterized latent diffusion model and subsequent Dense CRF optimization. We illustrate that such joint alternating refinement leads to the learning of better tokens for concepts and, as a bi-product, latent masks. We illustrate the benefits of the proposed approach qualitatively and quantitatively (through user studies) with a number of examples and use cases that can combine up to three entangled concepts.
PreAct: Predicting Future in ReAct Enhances Agent's Planning Ability
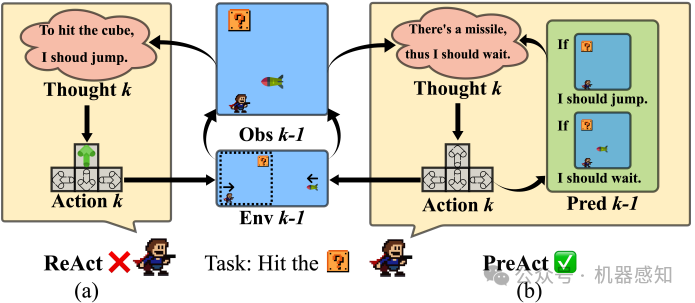
Addressing the discrepancies between predictions and actual outcomes often aids individuals in expanding their thought processes and engaging in reflection, thereby facilitating reasoning in the correct direction. In this paper, we introduce $\textbf{PreAct}$, an agent framework that integrates $\textbf{pre}$diction with $\textbf{rea}$soning and $\textbf{act}$ion. Leveraging the information provided by predictions, a large language model (LLM) based agent can offer more diversified and strategically oriented reasoning, which in turn leads to more effective actions that help the agent complete complex tasks. Our experiments demonstrate that PreAct outperforms the ReAct approach in accomplishing complex tasks and that PreAct can be co-enhanced when combined with Reflexion methods. We prompt the model with different numbers of historical predictions and find that historical predictions have a sustained positive effect on LLM planning. The differences in single-step reasoning between PreAct and ReAct show that PreAct indeed offers advantages in terms of diversity and strategic directivity over ReAct.
这篇关于Softmax的硬件友好型替代品;1-bit量化感知训练;基于LLM的数据可视化;视觉概念驱动的图像生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






