本文主要是介绍LeetCode解法汇总105. 从前序与中序遍历序列构造二叉树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录链接:
力扣编程题-解法汇总_分享+记录-CSDN博客
GitHub同步刷题项目:
https://github.com/September26/java-algorithms
原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
描述:
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:
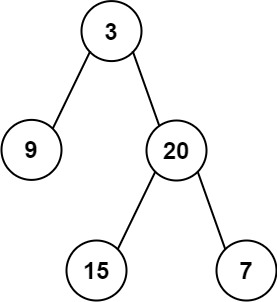
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7] 输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1] 输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
解题思路:
1.我们可以通过前序遍历和中序遍历发现一个规律,前序遍历的第一个数字,一定是根结点。然后中序遍历中找到这个根节点,就可以分成左右两份,分别对应左子树和右子树。 2.比如前序遍历是[1,2,3,4],中序遍历是[3,2,1,4],那么1就是根节点,[3,2]就位于根节点的左子树上,[4]位于根节点的右子树上。此时我们就可以构建一个1的节点。 3.我们继续对[4]的部分继续采取上面的分割流程,就可以生成一个4的节点,此时无法继续分割。继续对[2,3]的部分进行分割,则可以生成一个2的节点,然后继续分割。 4.所以,我们可以采取递归的策略,不断的分割,每次分割取出其前序和中序遍历的部分进行下一轮的遍历,直到长度为1,并添加到其左右节点上。就可以得到我们想要的结果。
代码:
class Solution {
public:TreeNode *buildTree(vector<int> &preorder, vector<int> &inorder){TreeNode *node = buildNode(preorder, inorder, 0, preorder.size() - 1, 0, inorder.size() - 1);return node;}TreeNode *buildNode(vector<int> &preorder, vector<int> &inorder, int preStart, int preEnd, int inStart, int inEnd){int expectValue = preorder[preStart];// inorder.at(expectValue);auto it = find(inorder.begin(), inorder.end(), expectValue);int index = std::distance(inorder.begin(), it);int leftLength = index - inStart;int rightLength = inEnd - index;TreeNode *root = new TreeNode(expectValue);if (leftLength >= 1){root->left = buildNode(preorder, inorder, preStart + 1, preStart + leftLength, inStart, index - 1);}if (rightLength >= 1){root->right = buildNode(preorder, inorder, preEnd - rightLength + 1, preEnd, index + 1, inEnd);}return root;}
};这篇关于LeetCode解法汇总105. 从前序与中序遍历序列构造二叉树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








