本文主要是介绍Pandas快问快答16-30题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
16. 如何对一个Pandas数据框进行聚合操作?
聚合操作是数据处理中的一种重要方式,主要用于对一组数据进行汇总和计算,以得到单一的结果。在聚合操作中,可以执行诸如求和、平均值、最大值、最小值、计数等统计操作。这些操作通常用于从大量数据中提取有用的信息,以便进行进一步的分析和决策。
在Pandas中,你可以使用groupby函数来对一个数据框进行聚合操作。groupby函数允许你根据一个或多个列对数据进行分组,然后对每个组执行聚合操作。
import pandas as pd # 创建一个简单的数据框
df = pd.DataFrame({ 'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'], 'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'], 'C': [1, 2, 2, 3, 3, 4, 5, 6], 'D': [10, 20, 30, 40, 50, 60, 70, 80]
}) # 根据列 'A' 和 'B' 进行分组,并计算每个组的平均值
grouped = df.groupby(['A', 'B'])['C'].mean() print(grouped)
在上面的例子中,我们根据列 'A' 和 'B' 对数据框进行分组,并计算每个组的平均值。你可以使用其他聚合函数,如sum、min、max等,来执行其他类型的聚合操作。 如果你想对整个数据框进行聚合操作,而不是仅针对某一列,你可以省略列名,直接调用groupby函数:
# 根据列 'A' 和 'B' 进行分组,并计算每个组的总和
grouped = df.groupby(['A', 'B']).sum() print(grouped)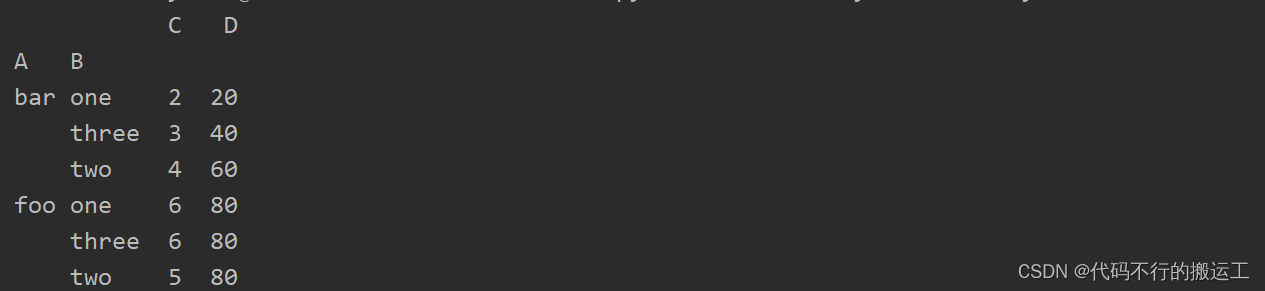
17. 如何对一个Pandas数据框进行合并操作?
Pandas 是一个用于数据分析和处理的强大 Python 库,提供了多种方法来合并数据框(DataFrame)。以下是一些常见的方法:
-
merge():这是最常用的方法,它基于一个或多个公共列(也称为键)组合两个数据框。默认情况下,只有具有匹配键的行才会包含在生成的数据框中。
merged_df = pd.merge(df1, df2, on='key')-
concat():按照行或列索引合并数据框。可以通过设置参数
axis来选择合并的方向(纵向或横向)。
merged_df = pd.concat([df1, df2], axis=0)-
append():用于在 DataFrame 的末尾添加行。需要注意的是,必须指定行名(name)。
df_append = df.loc[:3,['Gender','Height']].copy()
s = pd.Series({'Gender':'F','Height':188},name='new_row')
df_append.append(s)18. 如何在 Pandas 数据框中添加一列数据?
在 Pandas 数据框中添加一列数据可以通过多种方式实现,以下是其中的几种方法:
- 通过直接给新的列名赋值来添加一列。
# 添加新列 'new_column'
df['new_column'] = [100, 200, 300, 400, 500] -
使用
assign()方法:assign()方法可以用于在数据框中添加新列,并返回一个新的数据框。
# 使用 assign() 方法添加新列
df = df.assign(new_column=[100, 200, 300, 400, 500]) 在上面的例子中,我们给 df 数据框添加了一个名为 'new_column' 的新列,并为它分配了一个列表 [100, 200, 300, 400, 500] 作为值。如果你需要基于现有列的值来计算新列的值,可以直接使用现有列的名称。例如,如果你想添加一个列 'C',其值是列 'A' 和列 'B' 的和,可以这样做:
# 添加新列 'C',它是列 'A' 和列 'B' 的和
df['C'] = df['A'] + df['B'] # 或者使用 assign() 方法
df = df.assign(C=df['A'] + df['B']) 如果希望new_column 列的值是 existing_column 列值的两倍,则可以使用assign() 方法结合lambda:
df = df.assign(new_column=lambda x: x['existing_column'] * 2)
df['new_column'] = df['existing_column'] * 2-
使用
insert()方法:如果你想在特定位置插入新列,可以使用insert()方法。例如,假设你想在第一列之前插入一个名为new_column的新列:
df.insert(0, 'new_column', df['existing_column'] * 2)
请注意,在执行这些操作之前,你需要确保数据框的索引是正确的。你可以使用 reset_index() 方法来重置数据框的索引。
18. 如何在 Pandas 数据框中删除一列数据?
在 Pandas 数据框中删除一列数据有几种方法。以下是其中两种常见的方法:
- 使用
drop()方法。drop()方法是 Pandas 中用于删除行或列的函数。要删除一列,你需要指定列名或列的索引位置。
# 删除名为 'B' 的列
df_dropped = df.drop('B', axis=1) # 或者,删除索引为 1 的列(即 'B' 列)
df_dropped = df.drop(df.columns[1], axis=1) 在上面的代码中,axis=1 参数指定了我们要删除的是列(而不是行,行的话 axis 会是 0)。
- 使用
del语句。你也可以使用 Python 的del语句来删除数据框中的列。这种方法会直接修改原始数据框。
# 删除名为 'C' 的列
del df['C'] 使用 del 语句删除列会直接从原始数据框 df 中移除 'C' 列,不需要创建一个新的数据框。
drop()方法默认不会修改原始数据框,而是返回一个新的数据框。如果你希望修改原始数据框,可以传递参数inplace=True给drop()方法。- 使用
del语句会直接修改原始数据框,因此在删除列之前,请确保这是你想要的操作,并且已经备份了数据(如果需要的话)。
19. 如何在Pandas 数据框中添加一行数据?
在Pandas数据框中添加一行数据有几种方法。以下是两种常见的方法:
- 使用
loc或iloc。你可以使用loc或iloc来在数据框的末尾添加一行。这通常涉及到创建一个新的行作为一个Series对象,然后使用loc或iloc将其添加到数据框中。
# 创建一个新的行作为Series对象
new_row = pd.Series([4, 40], index=df.columns) # 使用loc在末尾添加新行
df.loc[len(df)] = new_row - 使用
append()方法。append()方法允许你将一行或多行作为一个新的数据框添加到现有数据框的末尾。
# 创建一个新的行作为一个字典
new_row = {'A': 4, 'B': 40} # 将新行转换为DataFrame
new_row_df = pd.DataFrame([new_row]) # 使用append()方法添加新行
df = df.append(new_row_df, ignore_index=True) 在上面的例子中,ignore_index=True 参数确保新的行索引会被重新排序,以适应新的数据框大小。如果不设置这个参数,新添加的行将保留其原始索引,这可能会导致索引不连续。
- 使用
loc或iloc直接在数据框上修改时,请确保索引是唯一的,否则可能会覆盖现有的行。 append()方法不会修改原始数据框,而是返回一个新的数据框。因此,你需要将结果赋值回原始变量(如示例中的df = df.append(...))。
20. 如何在 Pandas 数据框中删除一行数据?
在 Pandas 数据框中删除一行数据,你可以使用几种不同的方法。以下是几种常见的方法:
- 使用
drop()方法。drop()方法可以用来删除行或列。要删除一行,你需要指定行的索引。
# 删除索引为 2 的行(即第三行,因为索引从0开始)
df_dropped = df.drop(2) - 使用布尔索引。你可以使用布尔索引来删除满足特定条件的行。
# 删除 'A' 列值等于 3 的行
df_dropped = df[df['A'] != 3] - 使用
loc或iloc。你也可以使用loc(基于标签)或iloc(基于整数位置)来删除行。
# 删除索引为 2 的行(使用 loc)
df_dropped = df.loc[df.index.drop(2)] # 或者,删除第一行(使用 iloc)
df_dropped = df.iloc[1:] - 使用
query()方法。query()方法允许你使用字符串形式的条件表达式来删除行。
# 删除 'A' 列值等于 3 的行
df_dropped = df.query('A != 3') drop()方法默认返回一个新的数据框,不会修改原始数据框。如果你希望修改原始数据框,可以传递参数inplace=True给drop()方法。- 使用
loc或iloc时,需要确保你正确地指定了行的索引或位置。 - 如果你的数据框有多级索引(MultiIndex),你可能需要指定多个索引级别来删除特定的行。
21. 如何在 Pandas 数据框中选择某个范围内的行?
在 Pandas 数据框中,你可以使用几种不同的方法来选择某个范围内的行。以下是几种常见的方法:
- 使用
.loc[]或.iloc[]。.loc[]是基于标签的索引方式,而.iloc[]是基于整数位置的索引方式。你可以使用这两种方法来选择特定范围内的行。
# 选择索引 '1' 到 '3'(包括两端)的行
selected_rows = df.loc[1:4] # 注意,结束索引是包含的,但开始索引是不包含的# 选择第2行到第4行(包括两端)的行
selected_rows = df.iloc[1:4] # 同样,结束索引是包含的,开始索引是不包含的 - 使用布尔索引。你也可以使用布尔索引来选择满足特定条件的行范围。
# 选择 'A' 列值在 2 到 4 之间的行
selected_rows = df[(df['A'] >= 2) & (df['A'] <= 4)] - 使用
query()方法。query()方法允许你使用字符串形式的条件表达式来选择行。
# 选择 'A' 列值在 2 到 4 之间的行
selected_rows = df.query('2 <= A <= 4') - 在使用
.loc[]和.iloc[]时,开始索引是不包含的,而结束索引是包含的。因此,df.loc[1:4]会选择索引为 1, 2, 3 的行。 - 如果你想要包含开始索引,你需要将其包括在切片中,例如
df.loc[1:5]会选择索引为 1, 2, 3, 4 的行。 - 布尔索引和
query()方法提供了更灵活的条件选择,你可以根据列的值来动态地选择行的范围。
22. 如何在Pandas 数据框中选择某个范围内的列?
- 选择第1列到第3列(包括第1列和第3列)的列:
selected_columns = df.iloc[:, 0:3]- 选择第1行和第2列到第4列的列:
selected_rows_and_columns = df.iloc[0, 1:4]23. 如何在 Pandas 数据框中按特定条件选择行?
在 Pandas 数据框中按特定条件选择行,可以使用布尔索引。
- 选择列
'A'中大于 1 的所有行:
selected_rows = df[df['A'] > 1]- 选择列
'B'中等于特定值'aaa'的所有行:
selected_rows = df[df['B'] == 'aaa']- 选择列
'A'中大于 1 且列'B'中等于'aaa'的所有行:
selected_rows = df[(df['A'] > 1) & (df['B'] == 'aaa')]24. 如何在 Pandas 数据框中对某一列进行排序?
# 对列 'A' 进行升序排序
sorted_df = df.sort_values(by='A')25. 如何在 Pandas 数据框中计算某一列的总和?
# 计算列 'A' 的总和
sum_value = df['A'].sum() 26. 如何在 Pandas 数据框中计算某一列的平均值?
# 计算列 'A' 的平均值
average = df['A'].mean() 27. 如何在 Pandas 数据框中计算某一列的中位数?
# 计算列 'A' 的中位数
median = df['A'].median()28. 如何在 Pandas 数据框中计算某一列的标准差?
# 计算列 'A' 的标准差
std_dev = df['A'].std() 29. 如何在 Pandas 数据框中计算某一列的方差?
# 计算列 'A' 的方差
variance = df['A'].var() 请注意,默认情况下,var() 方法会计算样本方差,这意味着它会自动排除数据框中的第一个和最后一个观测值。如果你想计算总体方差而不是样本方差,可以将参数 ddof 设置为 0,例如 df['A'].var(ddof=0)。
30. 如何在 Pandas 数据框中查找最大值和最小值?
在Pandas数据框中查找最大值和最小值有多种方法。
- 使用
max()和min()函数:这些函数可以直接应用于整个数据框或特定列。 -
查找整个数据框的最大值和最小值:
max_value = df.max()
min_value = df.min()-
查找特定列的最大值和最小值:
max_value_column_A = df['A'].max()
min_value_column_A = df['A'].min()- 使用
idxmax()和idxmin()函数:这些函数不仅返回最大值和最小值,还返回这些值所在行的索引。
max_idx = df.idxmax()
min_idx = df.idxmin()-
查找特定列的最大值和最小值的索引:
max_idx_column_A = df['A'].idxmax()
min_idx_column_A = df['A'].idxmin()- 使用
describe()方法:此方法提供有关数据的一些统计摘要,包括计数、平均值、标准差、最小值、25%、50%、75%分位数以及最大值。
请注意,如果数据框中有NaN值,max()、min()和idxmax()、idxmin()默认情况下会忽略这些值。如果你想在计算中包括NaN值,可以使用参数skipna=False。例如:df['A'].max(skipna=False)。
这篇关于Pandas快问快答16-30题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







