本文主要是介绍Apache Iceberg 在网易云音乐的实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1
iceberg 详细设计
Apache iceberg 是Netflix开源的全新的存储格式,我们已经有了parquet、orc、arvo等非常优秀的存储格式以后,Netfix为什么还要设计出iceberg呢?和parquet、orc等文件格式不同, iceberg在业界被称之为Table Foramt,parquet、orc、avro等文件等格式帮助我们高效的修改、读取单个文件;同样Table Foramt帮助我们高效的修改和读取一类文件集合,大家可以类比的Hive的元数据系统, Hive的Schema帮助我们了解数据, Hive的分区帮助我们高效过滤数据。那么iceberg和hive相比的优势是什么呢?且看下文详细介绍,Netfilx对iceberg的定义为:
Iceberg is a scalable format for tables with a lot of best practices built in.
希望大家在看完本篇文章以后都能够在脑子里面印证上面这句定义。
1.1 Hive的一些问题
1.1.1 不可靠的更新操作
我们针对某张HIVE表的数据做 load data overwrite into 操作时, 整个操作分两个部分, 删除已存在的文件,移动新的文件到分区目录下,此时如果有人任务正在读取这个数据, 受文件删除操作的影响,整个任务就GG了,HIVE的操作整体是没有ACID保障的。
1.1.2 column rename 问题
在使用parquet、json、orc、avro等文件格式时, 如果我们重命名某个column的名字时,整个数据表都要重新复写,代价很大, 一些大的数据表基本是不可接受的。
1.1.3 太多分区造成的性能问题
hive的分区元数据都是保存到目录级别,在读取hive表做完分区下推查询以后,需要对所有过滤出来的分区做一次list操作,得到所有的明细文件然后生成任务,对于分区非常多表的来说,在云音乐目前的量级下,大量的list操作非常的耗时的,高峰期的NameNode压力非常大,大量的list操作的耗时的占比甚至和任务在计算上花费的时长相当,这也是为什么一些公司的hive表只允许两层分区的原因之一。
1.1.4 元数据保存在元数据和文件系统两个地方
分区信息保存在元数据库, 文件信息保存在NameNode当中,整体没有原子性保障,如果文件发生变化,多了数据或者少了数据,对于元数据是不感知的,数据虽然能被正常读取,但数据的可靠性是缺乏保障的。
1.2 iceberg设计
1.2.1 设计目标
和HIVE一样成为开放的静态数据存储标准, 标准清晰, 和语言无关和项目无关
强大的扩展性以及可靠性: 透明简单的使用, 用户只需写入数据所有元数据的变更都是自动和底层序列化方式无关的, 支持并发写
解决存储可用性问题: 更好的schema管理方式、时间旅行、多版本回滚支持等
1.2.2 详细设计
每次写入都会成一个snapshot, 每个snapshot包含着一系列的文件列表

基于MVCC(Multi Version Concurrency Control)的机制,默认读取文件会从最新的的版本, 每次写入都会产生一个新的snapshot, 读写相互不干扰
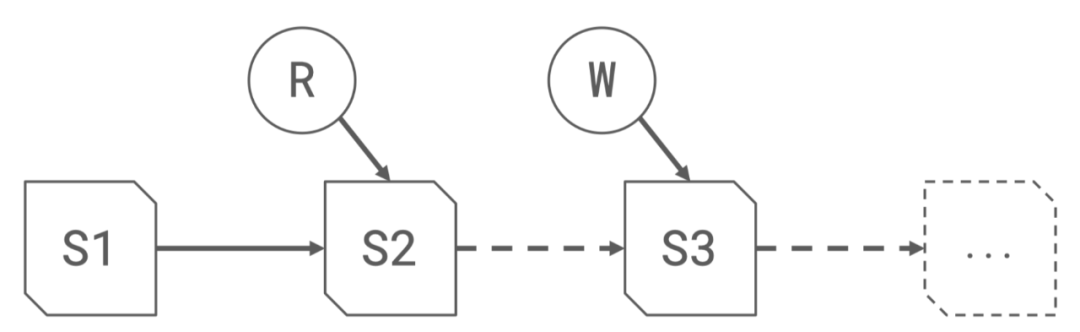
1.2.3 基于多版本的机制可以可用轻松实现回滚和时间旅行的功能, 读取或者回滚任意版本的snapshot数据
1.2.4 精准完善的元数据信息:
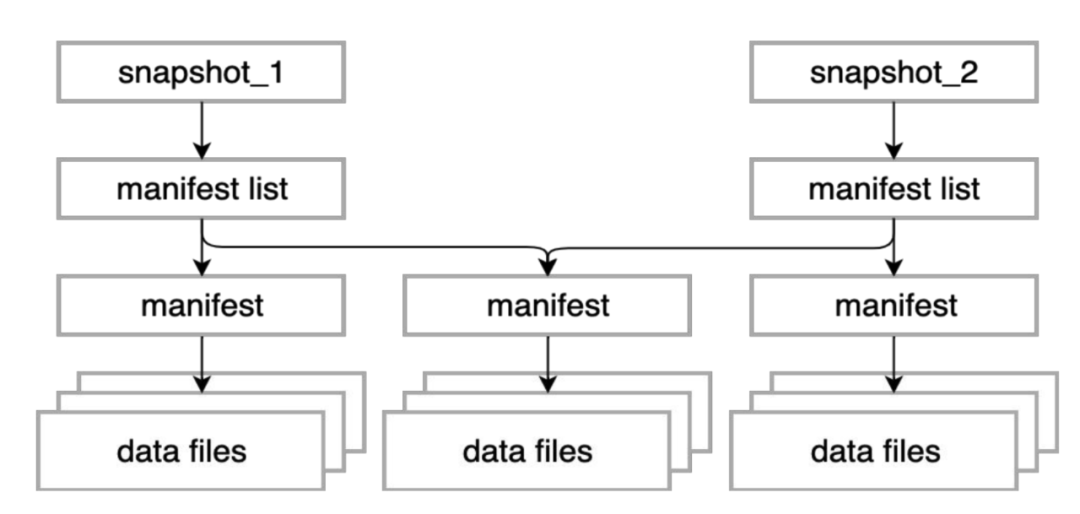
如上图所示, snapshot信息、manifest信息以及文件信息, 一个snapot包含一系列的manifest信息, 每个manifest存储了一系列的文件列表
snapshot列表信息:包含了详细的manifest列表,产生snapshot的操作,以及详细记录数、文件数、甚至任务信息,充分考虑到了数据血缘的追踪

manifest列表信息:保存了每个manifest包含的分区信息

文件列表信息:保存了每个文件字段级别的统计信息,以及分区信息

如此完善的统计信息,利用查询引擎层的条件下推,可以快速的过滤掉不必要文件,提高查询效率,熟悉了iceberg的机制,在写入iceberg的表时按照需求以及字段的分布,合理的写入有序的数据,能够达到非常好的过滤效果。
1.2.5 ID映射的方式管理Schema:
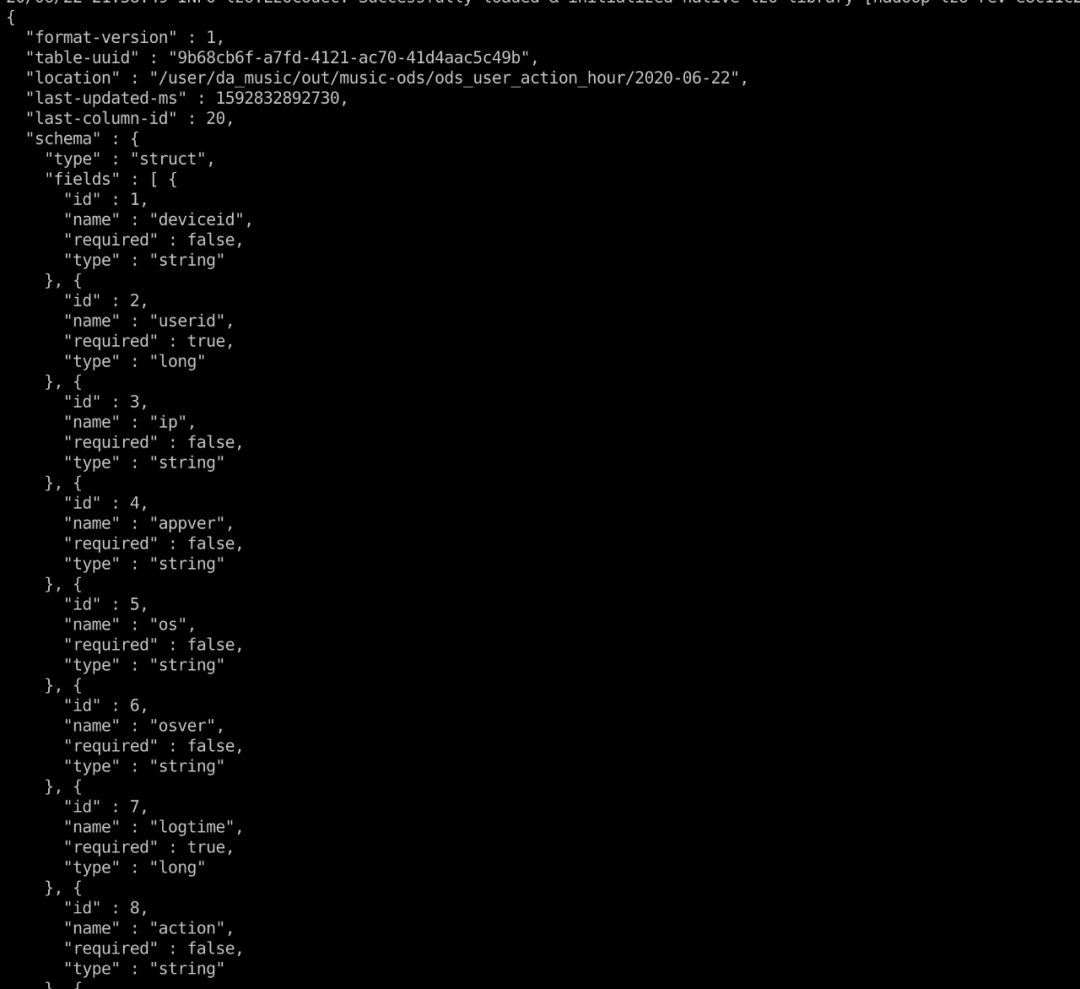
在iceberg的实际的存储文件中,schema的那么都是id,读取时和上图的元数据经过整合生成用户想要的schema,利用这种方式iceberg可以轻松的做的column rename,数据文件不需要修改的目录,且历史文件也能够完美的兼容的新的schema。
2
iceberg在云音乐的实践
云音乐仅主站的用户行为日志每天就会产生25T~30T,每天归档的文件数11万+,如果用spark直读这个11万+的文件的话,单单分区计算任务初始化的时间就要超过1个小时,如果每个业务域的DWD的数据都直接从原始的DS归档数据抽取数据的话,基本是不现实的,所以我们对底层数据按照小时的粒度进行预处理的工作,预处理工作主要包含两个部分:脏数据的清洗过滤和日志的分区,保障下游任务能够正确的只读取自己想要的数据。
但是即使是这样,我们依然有一些任务需要读取全量的日志数据,经过清洗的数据包含上百个分区,5万+个文件,加上凌晨高峰期的时候音乐的NameNode压力非常大,NameNode的请求队列经常处于满负荷状态,上百个分区需要Call NameNode上百次,这导致读取全量数据的时在任务初始化阶段就要耗费30分钟左右,在任务高峰期时整个时长高达1个小时,占了将近一半的任务执行时长,如果在执行期间机器发生故障,导致任务重试的话,整个延迟高达两个小时以上,整体不可接受。我们面临的问题和NetFlix早期面临的问题一致,也是iceberg想要解决的问题之一,所以我们利用iceberg的特性做了一些重构工作:
利用iceberg提供的HadoopCatalog的API新建了一张iceberg表,按照小时和行为分区,然后按照小时粒度清洗日志数据,并将数据结果写入到iceberg的表中,整体实践下来,由于iceberg不需要Call NameNode来获取文件信息以及其完善精准的统计信息,读取整表的速度有了质的提升,任务初始化的速度从以前的30分钟到一个小时,提升到5到10分钟,我们整体ETL任务的速度和稳定性也有了很大的提升,解决了长久以来困扰已久的稳定性问题。
当然这里使用iceberg只是我们优化的一小部分,在此就不为iceberg做过多的吹嘘,了解其中的原理,什么时候适合使用iceberg重构现有的存储,什么情况下能带来多大的提升基本心里应该也是有数的;在完成以上的改造以后也有一些使用的收获:
iceberg表的文件结构:iceberg表包含两个目录,metadata和data,metadata包含了所有的元数据文件,data中包含了数据文件:

其中data文件结果和hive的文件目录结构基本相同,在此不做过多的描述,metadata文件目录主要包含了三类文件,基本层级结构和上面第三张图的结果基本一致。
metadata文件:

每个meta文件相当于一个snapshot,其中包含了当前版本的schema信息、产生此版本的任务信息、以及manifest文件地址信息。
manifest-list文件:

包含了所有mainfest的文件的元数据信息,包含了manifest地址,分区范围以及一些统计信息:
java -jar avro-tools-1.9.2.jar tojson --pretty snap-8844883026140670978-1-0e32a3de-51d1-4641-9235-181c87a8a2f8.avro
----------------------------------------------------------------------------------------
{ "manifest_path" : "/user/da_music/out/music-ods/ods_user_action_hour/2020-06-26/metadata/0e32a3de-51d1-4641-9235-181c87a8a2f8-m0.avro","manifest_length" : 790541,"partition_spec_id" : 0,"added_snapshot_id" : {"long" : 8844883026140670978 },"added_data_files_count" : {"int" : 0 },"existing_data_files_count" : {"int" : 3639 },"deleted_data_files_count" : {"int" : 0 },"partitions" : {"array" : [ {"contains_null" : false,"lower_bound" : {"bytes" : "\u0000\u0000\u0000\u0000" },"upper_bound" : {"bytes" : "\u0001\u0000\u0000\u0000" } }, {"contains_null" : false,"lower_bound" : {"bytes" : "future" },"upper_bound" : {"bytes" : "user" } }, {"contains_null" : false,"lower_bound" : {"bytes" : "ABTest" },"upper_bound" : {"bytes" : "zan" } }, {"contains_null" : false,"lower_bound" : {"bytes" : "\u0000\u0000\u0000\u0000" },"upper_bound" : {"bytes" : "S\u0002\u0000\u0000" } } ] },"added_rows_count" : {"long" : 0 },"existing_rows_count" : {"long" : 6963879270 },"deleted_rows_count" : {"long" : 0 }}
manifest文件:
java -jar avro-tools-1.9.2.jar tojson --pretty 0e32a3de-51d1-4641-9235-181c87a8a2f8-m0.avro
---------------------------------------------------------------------------------------------
{ "status" : 0,"snapshot_id" : {"long" : 4472068361392595880 },"data_file" : {"file_path" : "/user/da_music/out/music-ods/ods_user_action_hour/2020-06-26/data/hour=1/group=future/action_partition=other/action_bucket=0/00000-22771-6dc69840-9f4f-4605-a297-3e63312bdf8a-00000.parquet","file_format" : "PARQUET","partition" : {"hour" : {"int" : 1 },"group" : {"string" : "future" },"action_partition" : {"string" : "other" },"action_bucket" : {"int" : 0 } },"record_count" : 48469,"file_size_in_bytes" : 3031083,"block_size_in_bytes" : 67108864,//每个字段存储大小信息"column_sizes" : {.... },//每个字段的COUNT信息"value_counts" : {.... }//每个字段的最小值信息"lower_bounds" : {... },//每个字段的最大值信息"upper_bounds" : {... },//文件分区信息"split_offsets" : {"array" : [ 4, 132073718, 265190437 ] }....
包含了所有的数据地址细化到具体文件,所以读取时不需list所有的文件,包含了分区信息,所有字段的存储大小、每个字段的行数信息、空值统计信息、每个字段的最大值、最小值信息、分区信息等等,上层引擎可以利用这些做JOIN的Cache优化、做文件级别的下推过滤,精准的分区信息,大大提高了上层引擎查询初始化的速度。
分区写入时必须按照分区字段写入有序的数据,iceberg本身应该采用了顺序写入的方式,在分区字段发生变化时,关闭当前写入的分区文件,创建并开始写入下一个分区的文件,如果数据不是有序的,写入时就会抛出写入已关闭文件的错误,所以在写入iceberg表之前必须按照分区的字段进行全局的sort操作,spark全局排序写入需要注意以下几点:
调大spark.driver.maxResultSize: spark的全局sort方法使用了RangePartition的策略,写入前会对每个分区抽样一定量的数据来确定整体数据的范围,所以如果写入数据量很大,分区很多时,必须调大spark.driver.maxResultSize防止driver端内存溢出。
文件数控制:通过调整spark.sql.shuffle.partitions的大小来控制全局排序后输出的文件数量,防止输出太多的小文件。
在按照分区字段排序以外,可以按照需求方的查询习惯额外加一些字段排序,利用精准的统计信息,来提升查询速度。
写入有序数据还有一个额外的好处就是能够获得更好的压缩率,这一点大家可以自己测试下,结果可能让人惊喜;iceberg这样的设计的可能就是有意为之,也是作者想要融合的最佳实践之一。
uaDF.sort(expr("hour"), expr("group"), expr("action"), expr("logtime")).write.format("iceberg").option("write.parquet.row-group-size-bytes", 256 * 1024 * 1024).mode(SaveMode.Overwrite).save(output)
iceberg的设计本身不受底层文件格式限制,目前支持avro、orc、parquet等文件格式, 本身parquet的元数据也包含了很多和iceberg类似的精准的统计元信息,在数据量较小时,iceberg提升不会特别明显,甚至没有提升,iceberg比较适合超大数据量的表。
3
未来规划
3.1 合并支持,解决FLINK归档到iceberg的大量小文件问题。
3.2 MergeInto支持,和Hudi、DeltaLake类似,支持数据的更新删除操作,支持merge on read 以及 merge on write,将iceberg作为以后批流一体的数仓的主力存储。
以上规划目前杭研的同学都已经在推进当中,期待后续的落地分享。
4
参考文档
官网:https://iceberg.apache.org/
关于TableFormat:https://www.youtube.com/watch?v=iRXNtsayENg
关于Iceberg:https://www.youtube.com/watch?v=mf8Hb0coI6o&t=939s
NetFilx使用iceberg归档流数据的分享:https://www.youtube.com/watch?v=-Q4UcXcIv1o
这篇关于Apache Iceberg 在网易云音乐的实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








