本文主要是介绍数据库管理-第152期 Oracle Vector DB AI-04(20240220),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据库管理152期 2024-02-20
- 数据库管理-第152期 Oracle Vector DB & AI-04(20240220)
- 1 常用的向量检索方法
- 聚类
- 图搜索
- 哈希
- 量化
- 2 Oracle Vector DB中的索引
- 索引(默认)
- 索引(高级)
- 3 EMBEDDINGS
- SQL EMBEDDINGS 函数
- OONX
- 总结
数据库管理-第152期 Oracle Vector DB & AI-04(20240220)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Associate: Database(Oracle与MySQL)
网思科技 DBA总监
10年数据库行业经验,现主要从事数据库服务工作
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP、认证技术专家,ITPUB认证专家,OCM讲师
圈内拥有“总监”、“保安”、“国产数据库最大敌人”等称号,非著名社恐(社交恐怖分子)
公众号:胖头鱼的鱼缸;CSDN:胖头鱼的鱼缸(尹海文);墨天轮:胖头鱼的鱼缸;ITPUB:yhw1809。
除授权转载并标明出处外,均为“非法”抄袭。
由于上一篇的一些“误操作”,导致公众号发文删了,当天重发没有办法触发群发效果,所以可能有些人会发现没看过03。
1 常用的向量检索方法
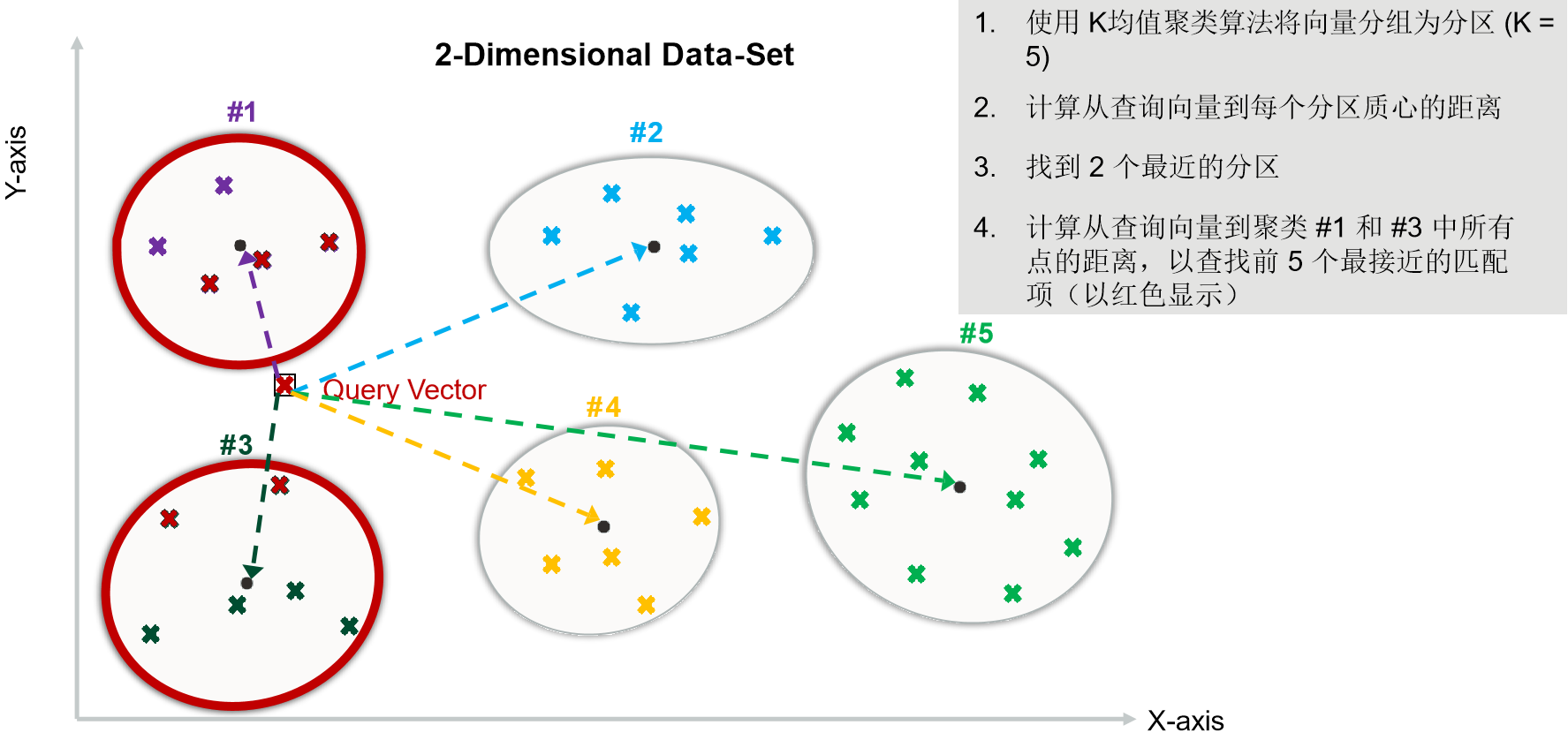
聚类
K-Means 和 Faiss
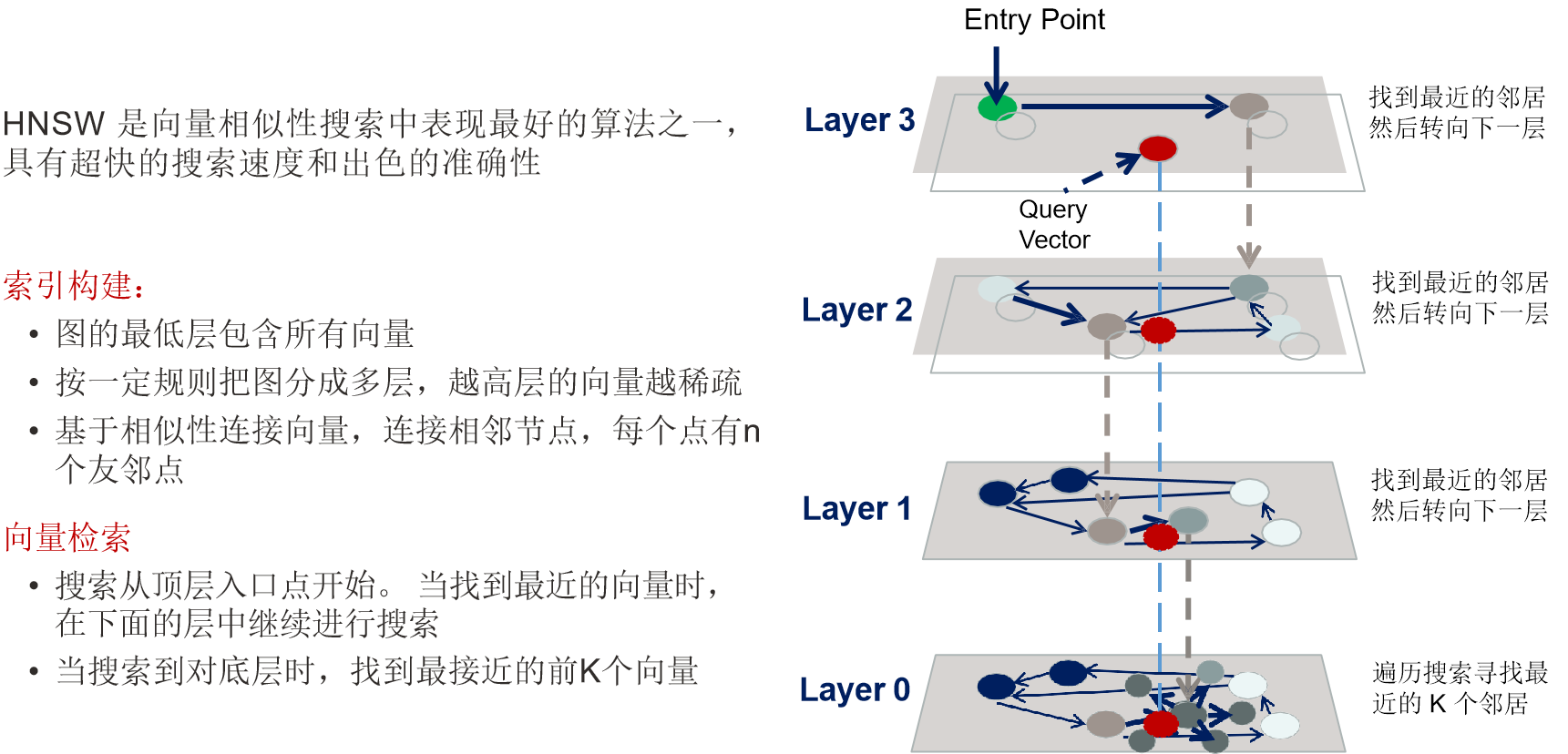
图搜索
Hierarchical Navigable Small Worlds (HNSW)
哈希
局部敏感哈希(Locality Sensitive Hashing)LSH
量化
Product Quantization (PQ):有损压缩
2 Oracle Vector DB中的索引
在Oracle Vector DB中,可以在Vector数据类型列上创建vector index来提升向量检索的性能:
索引(默认)
create vector index vector_idx on vector_table (data_vector)
organization [inmemory neighbor graph | neighbor partition]
距离计算:欧几里德
向量索引的选择取决于organization子句:
- In-Memory Neighbor Graph organization:HNSW
- Neighbor Partition organization:IVF
索引(高级)
可以指定向量索引类型参数、距离函数、精度等:
create vector index vector_idx on vector_table (data_vector) organization neighbor partition parameters (num_centroids 1024);
3 EMBEDDINGS
在Oracle Vector DB除直接通过外部导入向量外,也内建支持多种向量生产方式:
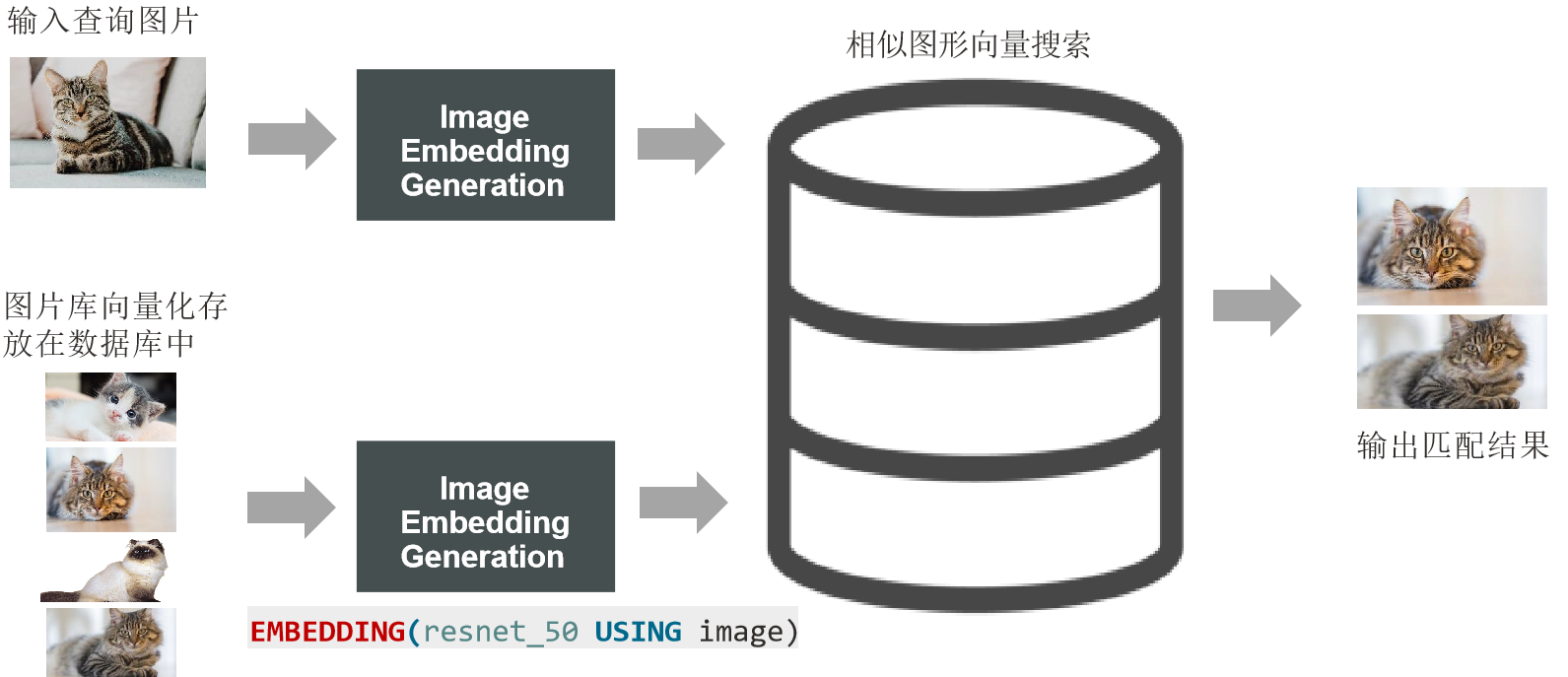
SQL EMBEDDINGS 函数
原生支持生成向量数据:
select id, image from cat_images order by VECTOR_DISTANCE(img_vec, EMBEDDING(resnet_50 USING :input_img)) fetch first 2 rows only;
OONX
Open Neural Network eXchange embedding 模型:
DECLAREmodel_source BLOB := NULL;
BEGINmodel_source :=DBMS_CLOUD.get_object( credential_name =>'OBJ_STORE_CRED',object_uri => 'https://objectstorage…bucketname/o/resnet50bundle.onnx’);DBMS_DATA_MINING.import_onnx_model( model_name => "resnet50",model_data => model_source,metadata => JSON('{ function : "embedding" }')
);
END;
总结
本期简单讲解了一下,Oracle Vector索引以及内建向量EMBEDDING能力。
老规矩,知道写了些啥。
这篇关于数据库管理-第152期 Oracle Vector DB AI-04(20240220)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





