本文主要是介绍GA-kmedoid 遗传算法优化K-medoids聚类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
遗传算法优化K-medoids聚类是一种结合了遗传算法和K-medoids聚类算法的优化方法。遗传算法是一种基于自然选择和遗传机制的随机优化算法,它通过模拟生物进化过程中的遗传、交叉、变异等操作来寻找问题的最优解。而K-medoids聚类算法是一种基于划分的聚类方法,它通过选择K个数据点作为簇中心,将数据点分配到最近的簇中心,以最小化每个数据点到其所属簇中心的距离之和。
K-medoids聚类算法是一种基于划分的聚类方法,与K-means算法相似,但有所不同。在K-medoids中,每个簇的中心是一个实际的数据点,即medoid(中心点),而不是通过计算得到的均值点。K-medoids算法的目标是选择K个数据点作为簇的中心,使得每个数据点与其所属簇的中心点的距离之和最小化。
K-medoids聚类算法的原理如下:
- 初始化:随机选择K个数据点作为初始的簇中心。
- 分配数据点到簇:根据每个数据点与簇中心点的距离,将数据点分配到最近的簇中。
- 更新簇中心:在每个簇中,选择一个数据点作为新的中心点,使得该数据点到簇内其他数据点的距离之和最小。
- 迭代:重复步骤2和3,直到簇中心不再发生变化或达到预设的迭代次数。
K-medoids聚类算法的优点主要包括以下几点:
- 对噪声和离群点鲁棒性:与K-means算法相比,K-medoids算法使用实际的数据点作为簇的中心,因此更能抵抗噪声和离群点的影响。当数据集中存在噪声或离群点时,K-medoids算法通常能够提供更稳定、更准确的聚类结果。
- 簇中心更具代表性:由于K-medoids算法选择实际的数据点作为簇的中心,这些中心点通常更具代表性,能够更好地反映簇内数据点的特征。
- 可解释性强:K-medoids算法的结果更容易解释和理解。每个簇的中心点是一个实际的数据点,可以直接观察和分析,从而更容易洞察数据的结构和模式。
需要注意的是,K-medoids算法也存在一些局限性,例如计算复杂度较高,因为每次迭代都需要在每个簇中选择一个新的中心点;同时,K-medoids算法也需要事先确定簇的数量K,这对于某些应用场景可能是一个挑战。另外,与K-means算法一样,K-medoids算法也仅适用于球形或凸形簇的情况,对于非球形簇可能无法得到理想的聚类结果。
以下是遗传算法优化K-medoids聚类的原理和过程的详细介绍:
1. 遗传算法优化原理
遗传算法通过模拟生物进化过程中的遗传机制来优化问题的解。它使用一种编码方式来表示问题的解,称为染色体。每个染色体都代表一个潜在的解,通过适应度函数来评估其优劣。遗传算法通过选择、交叉和变异等操作来生成新一代的染色体,并逐代进化,直到找到最优解或满足终止条件。
2. 遗传算法优化K-medoids聚类的过程
步骤1:初始化种群
- 随机生成一定数量的初始染色体,每个染色体表示一种簇中心的组合方式。
- 染色体的编码方式可以采用实数编码或整数编码,具体取决于问题的特点。
步骤2:计算适应度函数
- 对于每个染色体(即簇中心组合),使用K-medoids聚类算法将数据点分配到最近的簇中心。
- 计算每个数据点到其所属簇中心的距离之和,作为聚类的误差。
- 使用聚类误差的负值作为适应度函数值,以最小化聚类误差为目标。
步骤3:选择操作
- 根据适应度函数值选择优秀的染色体进入下一代。
- 可以使用轮盘赌选择、锦标赛选择等策略来进行选择操作。
步骤4:交叉操作
- 对选择的染色体进行交叉操作,生成新的后代染色体。
- 交叉操作可以采用单点交叉、多点交叉等方式,具体取决于染色体的编码方式。
步骤5:变异操作
- 对新生成的后代染色体进行变异操作,引入一定的随机性。
- 变异操作可以采用随机扰动、位变异等方式,以增加种群的多样性。
步骤6:更新种群
- 将新一代染色体组成新的种群,并用于后续的进化过程。
步骤7:终止条件
- 重复执行步骤2到6,直到达到预设的迭代次数、适应度函数值不再显著提高或满足其他终止条件。
步骤8:输出最终聚类结果
- 选择适应度最高的染色体作为最终的簇中心组合。
- 使用K-medoids聚类算法将数据点分配到最近的簇中心,得到最终的聚类结果。
通过结合遗传算法和K-medoids聚类算法,可以更有效地优化簇中心的选择,提高聚类的准确性和稳定性。遗传算法的全局搜索能力有助于避免K-medoids算法对初始簇中心敏感的问题,并找到更好的聚类结果。
效果图如下:

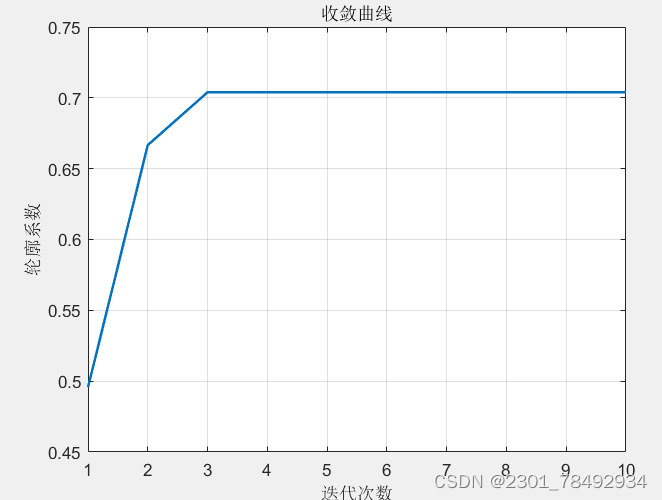
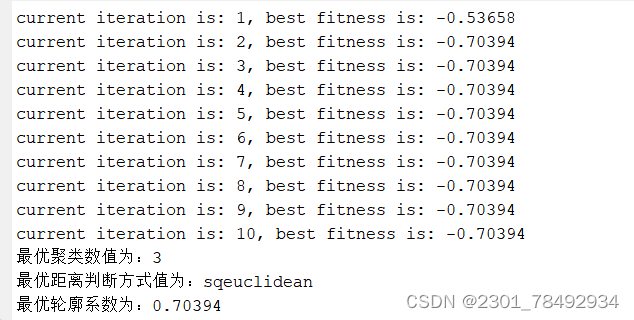
这篇关于GA-kmedoid 遗传算法优化K-medoids聚类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



