本文主要是介绍建模杂谈系列239 物品协同过滤-ItemCF,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
推荐是很重要的一块内容,丢下有点久了。计划先快速恢复一部分基础内容,然后再和产品改进结合,丰富这块的内容。
内容
具体的理论部分可以参考这篇文章,以下从实操和我的理解做一个实践。
本质上,协同过滤是利用用户的选择,来给任意两个物品打标。
1 计算数据
以购买为例,一个用户如果购买过a,b,c,说明这三个物品存在关联。在参考文章的例子中,有5个客户,每个客户喜欢(或可认为是购买过)几种物品。
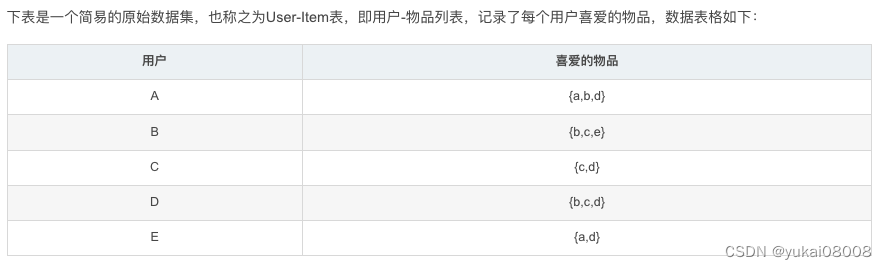
# 例子中的数据
data_list = ['abd','bce','cd','bcd','ad']
item_counts = dict(pd.Series(list(''.join(data_list))).value_counts()){'d': 4, 'c': 3, 'b': 3, 'a': 2, 'e': 1}
以下是两个函数
# 用户ABCDE,物品abcde
# 计算用户的C(n,2)
from itertools import combinations
import pandas as pd
import numpy as np
def generate_combinations_cn2(input_list):# 生成C(n, 2)的组合comb = list(combinations(input_list, 2))# 筛选不包含相同元素的组合unique_combinations = [c for c in comb if c[0] != c[1]]# 每个组合按照字母排序sorted_combinations = [tuple(sorted(c)) for c in unique_combinations]return sorted(sorted_combinations) # 返回排序后的结果
import pandas as pd
# 将数据框中的n列压成一列字典表示 | 用于SRule的入参构造 | 假设pandas是统一中间体
def cols2s(some_df, cols = None, cols_key_mapping = None):assert isinstance(some_df, pd.DataFrame),'some_df Must Be DataFrame'assert isinstance(cols, list), 'cols Must Be List'assert isinstance(cols_key_mapping, list), 'cols_key_mapping Must Be List'assert len(cols) == len(cols_key_mapping),'cols and cols_key_mapping Must Be Same Length'some_df_cols = list(some_df.columns)if not set(some_df_cols) >= set(cols):raise ASetError('集合判定错误')some_df1 = some_df[cols]some_df1.columns = cols_key_mappingreturn pd.Series(some_df1.to_dict(orient='records'))
# # 示例用法
# input_list = ["b", "a", "c", "b", "d"]
# result = generate_combinations_cn2(input_list)
# print(result)
# # [('a', 'b'), ('a', 'b'), ('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'c'), ('b', 'd'), ('b', 'd'), ('c', 'd')]
函数generate_combinations_cn2会将给定的列表进行C(n,2)组合,并将组合结果按照字母排序,这样可以用唯一的key来表达一对组合。
函数cols2s则是将一个表压缩成一个列,每个元素都是一条记录(字典)。
将每个用户的物品进行C(n,2)组合,这样可以列出一对物品出现的次数(这里也就是对共现矩阵进行一种实现)
res_list = []
for some_data in data_list:comb_res = generate_combinations_cn2(list(some_data))res_list.append(comb_res)
res_list1 = sum(res_list, [])
res_df = pd.DataFrame(res_list1)
res_df.columns = ['i','j']
res_df1 = res_df.groupby(['i','j']).size().reset_index()
res_df1.columns = ['i','j','cnt']i j cnt
0 a b 1
1 a d 2
2 b c 2
3 b d 2
4 b e 1
5 c d 2
6 c e 1
将这个结果压缩为一列字典。
res_s = cols2s(res_df1, cols=['i','j','cnt'],cols_key_mapping=['i','j','cnt'] )
0 {'i': 'a', 'j': 'b', 'cnt': 1}
1 {'i': 'a', 'j': 'd', 'cnt': 2}
2 {'i': 'b', 'j': 'c', 'cnt': 2}
3 {'i': 'b', 'j': 'd', 'cnt': 2}
4 {'i': 'b', 'j': 'e', 'cnt': 1}
5 {'i': 'c', 'j': 'd', 'cnt': 2}
6 {'i': 'c', 'j': 'e', 'cnt': 1}
dtype: object
一对物品,除了要计算频率,还需要归一化。这点和TFIDF也很像。
def cal_weight(input_dict, item_cnt_dict = item_counts):i = input_dict['i']j = input_dict['j']cnt = input_dict['cnt']
# print(cnt)
# print(item_cnt_dict[i])
# print(item_cnt_dict[j])res = cnt / np.sqrt(item_cnt_dict[i] * item_cnt_dict[j])return res
res_df1['weight'] = list(res_s.apply(cal_weight))i j cnt weight
0 a b 1 0.408248
1 a d 2 0.707107
2 b c 2 0.666667
3 b d 2 0.577350
4 b e 1 0.577350
5 c d 2 0.577350
6 c e 1 0.577350
2 推荐
现在假设要对用户C进行推荐,用户C购买了c和d。
# 目标客户是 C: cd
c_set = set(list('cd'))
{'c', 'd'}# 相关集合
rel_set_dict = {}
total_rel_set = set()
for some_item in sorted(list(c_set)):print(some_item)set_j = set(res_df1[res_df1['i'] ==some_item]['j'])set_i = set(res_df1[res_df1['j'] ==some_item]['i'])rel_set_dict[some_item] = set_i | set_jtotal_rel_set = total_rel_set | rel_set_dict[some_item] 其中 rel_set_dict 是和用户购买产品相关的物品集合
{'c': {'b', 'd', 'e'}, 'd': {'a', 'b', 'c'}}total_rel_set是所有相关的物品集合
{'a', 'b', 'c', 'd', 'e'}
现在要对用户没有买过的物品进行推荐
cand_set = total_rel_set - c_setcand_set是用户没有买过的
{'a', 'b', 'e'}
推荐
for cand in sorted(list(cand_set)):w = 0 for c_item in sorted(list(c_set)):if c_item <= cand:i = c_itemj = candelse:i = candj = c_item
# print(i,j)i_sel = res_df1['i'] == ij_sel = res_df1['j'] == jij_sel = i_sel & j_selif ij_sel.sum() > 0:tem_w = res_df1[ij_sel]['weight'].iloc[0]w+= tem_wprint(cand, w)
a 0.7071067811865475
b 1.2440169358562925
e 0.5773502691896258
推荐过程如下
- 1 遍历候选推荐物品 (cand),其对用户的总权重w初始化为0
- 2 遍历目标用户购买的物品(c_item)
- 3 将cand和c_item进行排序后,形成查询键,查找是否窜在关联记录(即i,j = cand, c_item)
- 4 如果存在,那么将该权重加到w上。
通过每个cand去和用户C购买的所有物品进行查询和权重相加,获得每个cand对用户的权重,也就是推荐值。
按照TopK的方式给用户进行推荐,这样就完成了。本例中最应该推荐b。
这篇关于建模杂谈系列239 物品协同过滤-ItemCF的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








