本文主要是介绍python爬取上海旅游景点(详细),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天爬取的是去哪儿网上的上海旅游景点,我们要爬取的是景点的经纬度、景点名称、点评数、星级、攻略提到的次数
爬取出来的数据如下(我只截取了前10条数据):
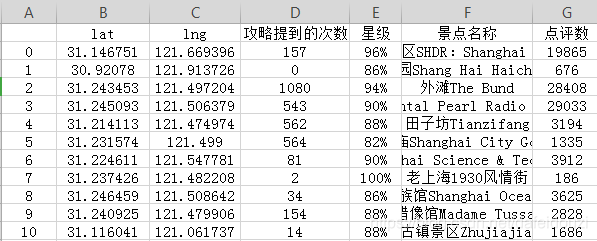
爬取的网址是:https://travel.qunar.com/p-cs299878-shanghai-jingdian
首先是导入工具库![]()
用途:用requests对网址发出请求后,用BeautifulSoup解析网址

这里拓展一下:200 说明服务器已成功处理请求
302 说明服务器目前从不同位置的网页响应请求,类似跳转页面
404 说明服务器找不到请求的页面

通过requests对网址发出请求后,咱们可以使用r.text获取网页的html文档,密密麻麻一大堆~
接着咱们试一试使用BeautifulSoup解析网址,看看会产生什么结果
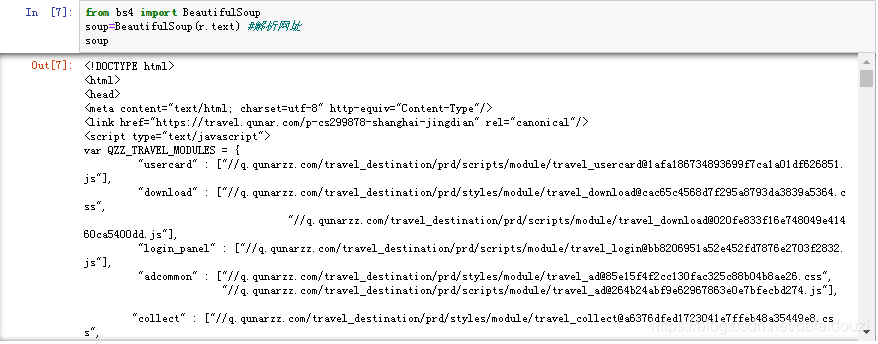
嗯~看起来好多了~在html中,h1表示最大的标题,h6表示最小的标题
咱们试试获取h1这个标题信息 ,可以看到我们获取到的是网页的标题

现在差不多知道requests和BeautifulSoup的用法啦,那么就开始爬取上海的旅游景点信息吧
登录网址后咱们可以发现这是列表页面,每个页面的网址都基本相同,唯一不同的就是所在的页面,如下,第二页和第三页不同的地方只有最后面2、3所在的位置
![]()
![]()
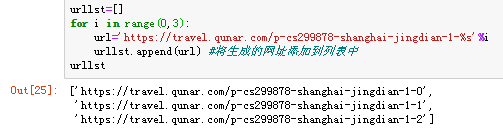
根据上面的信息,获取前3页的网址看看~这里我创建了一个空列表urllst,用来准备装生成的网址,用的是.append将生成的网址添加到列表
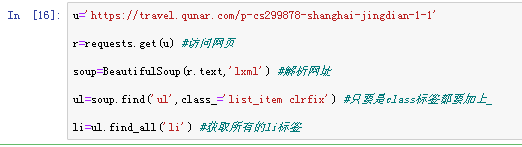
我们试试采集第一页的信息,可以看到下面截图中圈出来部分可以完全包含我们所要爬取的信息,所以可以从class为list_item clrfix的ul标签中获取信息,每一个li标签对应着每一个景点的信息

find_all()表示查找所有的标签
因为每个li对应的是每个景点的信息,我们来看看第一个景点的信息
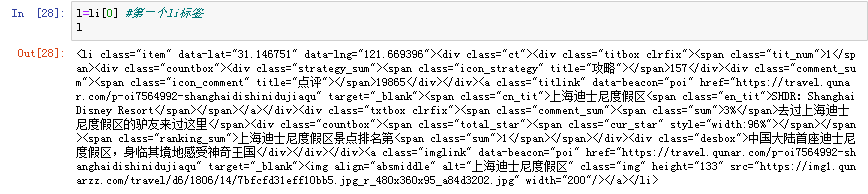
如果我要获取的是这个景点的位置、名称、点评数、星级、攻略提到的次数,应该怎么办?
图中标注出来的标签就是对应的景点位置、攻略提到的次数、名称、点评数、星级
因为经纬度直接在li里的,是属性值,直接索引就可以了
景点名称属于元素,存储在class为cn_tit的span标签中,需要用find()函数找到标签,找到标签后,在其后面加.text就可以获取到景点的名称啦;攻略提到的次数是div标签中的,它的span标签其实是空的,只是嵌套在了div标签下;点评数是在class为comment_sum的span标签下;星级是在class为cur_star的span标签下的style中,找到星级标签后采用的是split对width:96%进行分割

下面代码使用了字典dic存储获取到的数据
我们获取到的是第一个景点的信息:

这个上海旅游景点的网站中每个网页有10个景点,那么如果我想要获取200个网页的信息呢
具体代码如下:
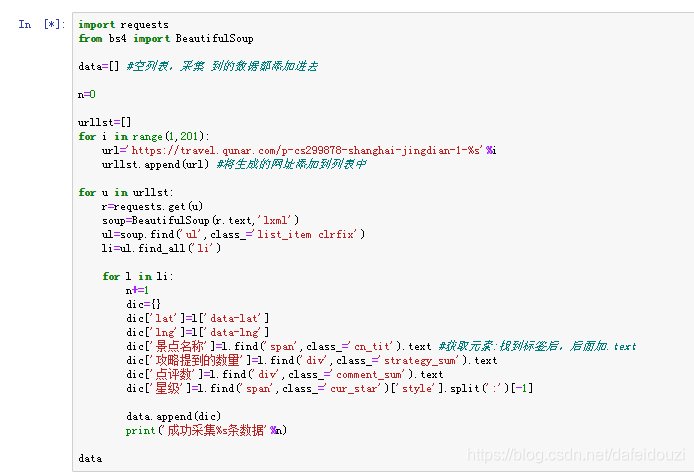
最后一共爬取了2000条数据

爬好的数据,将其转化成数据框的形式再保存为CSV的格式,然后就完成了~~~得到的结果就是开头我发的那张数据截图

我很黑,但我是小白是真的,所以我是往详细了写~这样后面遇到不懂的还能回头看看
完整代码奉上~~~
import requests
from bs4 import BeautifulSoupdata=[] #空列表,采集 到的数据都添加进去n=0urllst=[]
for i in range(1,201):url='https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-%s'%iurllst.append(url) #将生成的网址添加到列表中for u in urllst:r=requests.get(u)soup=BeautifulSoup(r.text,'lxml')ul=soup.find('ul',class_='list_item clrfix')li=ul.find_all('li')for l in li:n+=1dic={}dic['lat']=l['data-lat']dic['lng']=l['data-lng']dic['景点名称']=l.find('span',class_='cn_tit').text #获取元素:找到标签后,后面加.textdic['攻略提到的数量']=l.find('div',class_='strategy_sum').textdic['点评数']=l.find('div',class_='comment_sum').textdic['星级']=l.find('span',class_='cur_star')['style'].split(':')[-1]data.append(dic)print('成功采集%s条数据'%n)dataimport pandas as pd
df=pd.DataFrame(data)
df.to_csv('C:/Users/Administrator/Desktop/dd.csv')
这篇关于python爬取上海旅游景点(详细)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






