本文主要是介绍【MATLAB】鲸鱼算法优化混合核极限学习机(WOA-HKELM)回归预测算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有意向获取代码,请转文末观看代码获取方式~也可转原文链接获取~

1 基本定义
鲸鱼算法优化混合核极限学习机(WOA-HKELM)回归预测算法是一种结合鲸鱼优化算法和混合核极限学习机的混合算法。其原理主要包含以下几个步骤:
-
初始化:设定鲸鱼群体的初始位置及速度,设定混合核极限学习机的初始参数。
-
计算适应度:根据目标函数值计算每只鲸鱼的适应度,并根据适应度选择最优解。
-
更新位置和速度:根据鲸鱼的适应度和目标函数值更新每只鲸鱼的位置和速度。
-
边界约束:对鲸鱼的位置进行边界约束处理,确保鲸鱼在合理范围内移动。
-
构建核极限学习机模型:利用鲸鱼算法优化后的核函数参数,构建混合核极限学习机模型。
-
训练模型:利用训练数据对模型进行训练,通过计算输出权重矩阵,实现对输入数据的分类。
-
预测:利用训练好的模型对测试数据进行预测,输出预测结果。
-
终止条件:当满足一定的终止条件时,算法停止迭代。常见的终止条件包括达到最大迭代次数、适应度达到预设阈值等。
通过以上步骤,WOA-HKELM算法能够利用鲸鱼优化算法优化核函数的参数,提高混合核极限学习机的分类性能和预测精度。同时,WOA-HKELM算法还具有较好的鲁棒性和可扩展性,适用于处理各种类型的数据。
鲸鱼混合核极限学习机(WOA-HKELM)是一种结合鲸鱼优化算法和混合核极限学习机的混合算法,用于回归预测问题。这种算法的优点和缺点如下:
优点:
-
高效性:WOA-HKELM算法结合了鲸鱼优化算法和混合核极限学习机,能够在较短时间内找到最优解,提高预测精度。
-
鲁棒性:WOA-HKELM算法对输入数据的异常值和噪声具有较强的鲁棒性,能够有效地避免模型出现过拟合现象。
-
可扩展性:WOA-HKELM算法可以应用于各种类型的数据,包括连续型、离散型、静态型和动态型等,具有较强的可扩展性。
-
灵活性:WOA-HKELM算法可以根据实际问题的需求,调整混合核极限学习机的参数,以获得更好的预测效果。
缺点:
-
参数敏感性:WOA-HKELM算法中的参数对预测结果的影响较大,需要仔细调整参数以达到最优的预测效果。
-
对大数据集处理能力有限:由于WOA-HKELM算法在处理大数据集时需要消耗大量的计算资源和时间,因此对于大规模数据的处理能力有限。
-
需要大量标注数据:WOA-HKELM算法需要大量的标注数据来进行训练和预测,而在某些领域中标注数据可能难以获取。
总体来说,WOA-HKELM算法在回归预测问题中具有较好的性能和效果,但也存在一些局限性,需要根据具体问题进行权衡和选择。
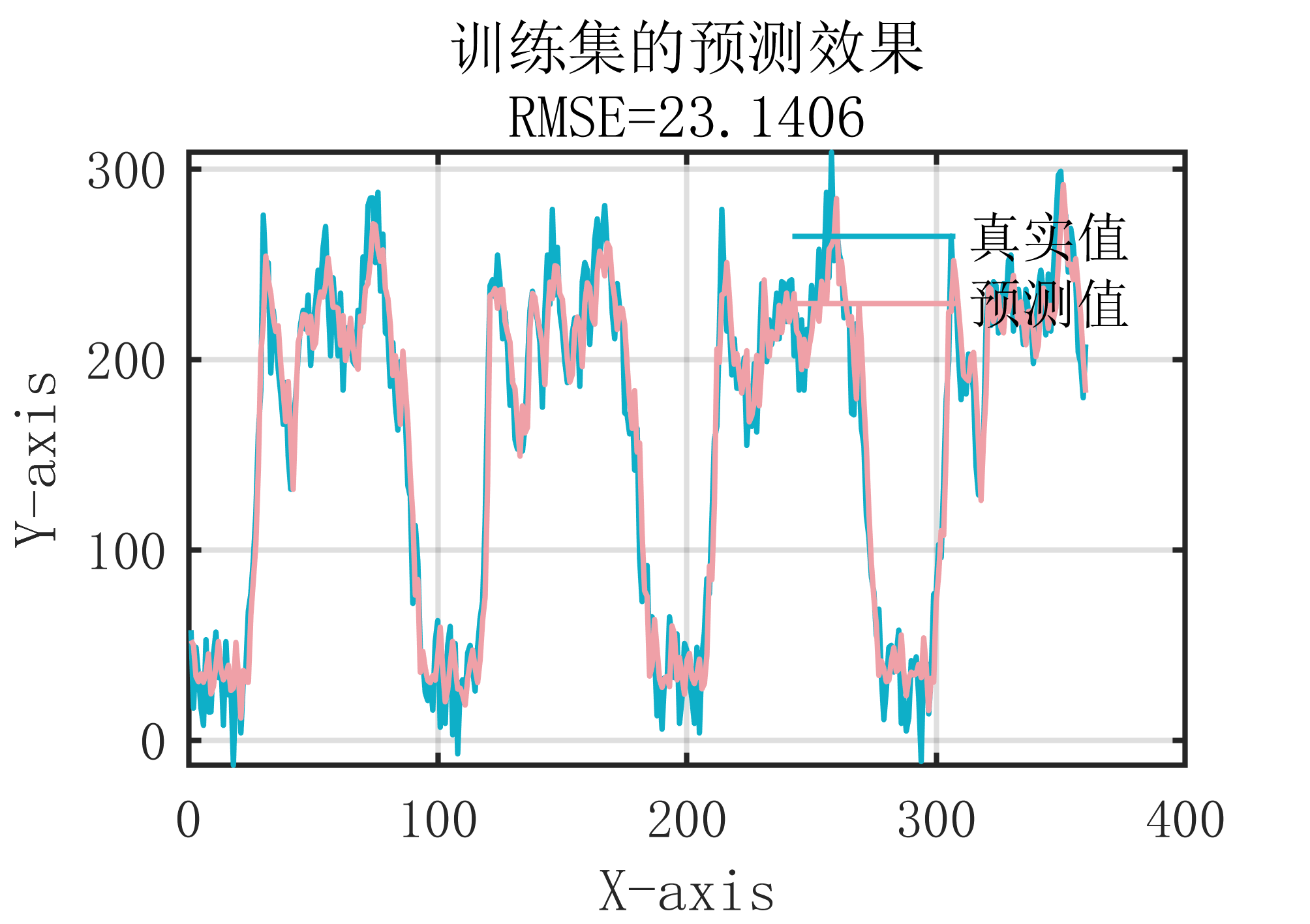
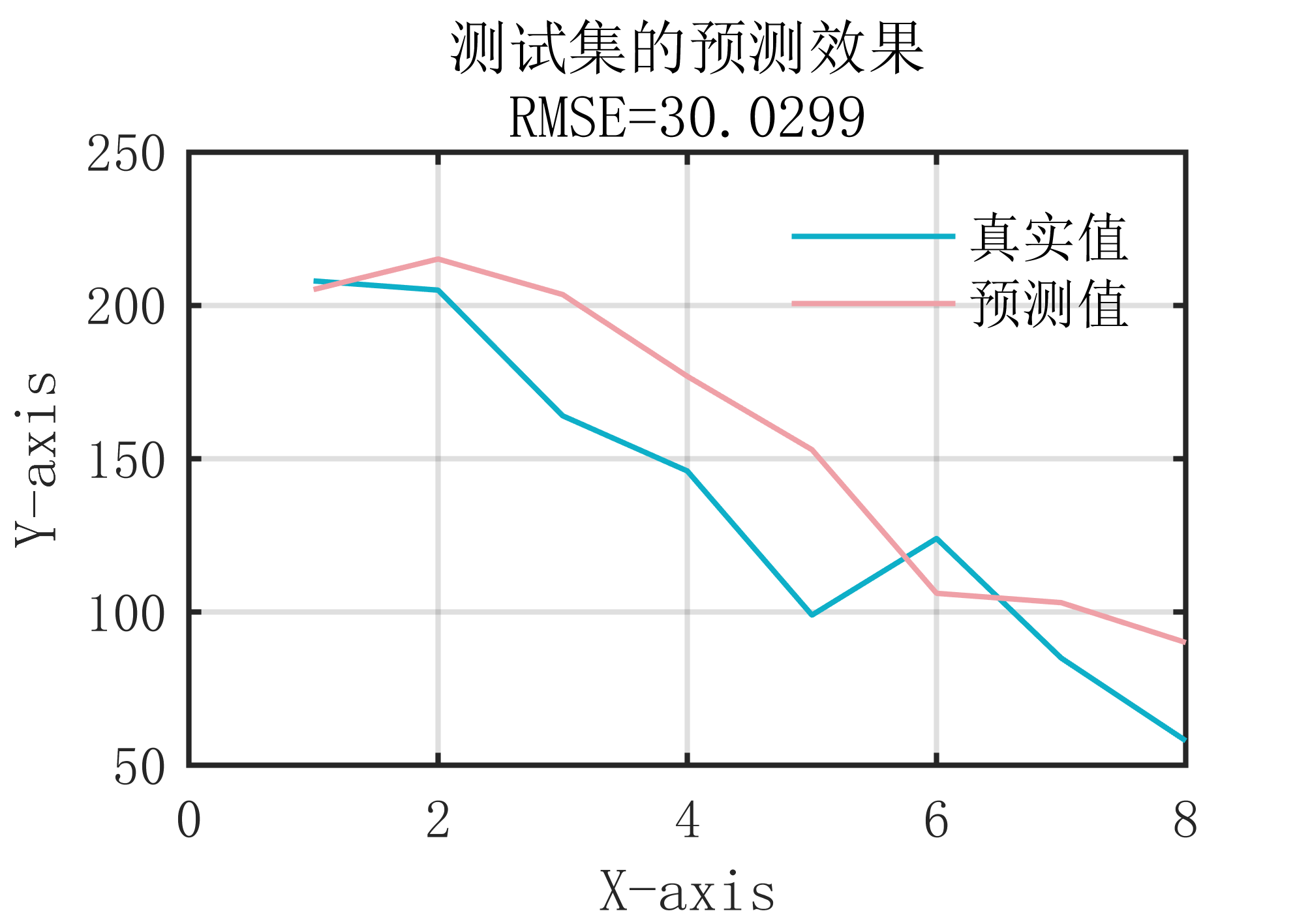
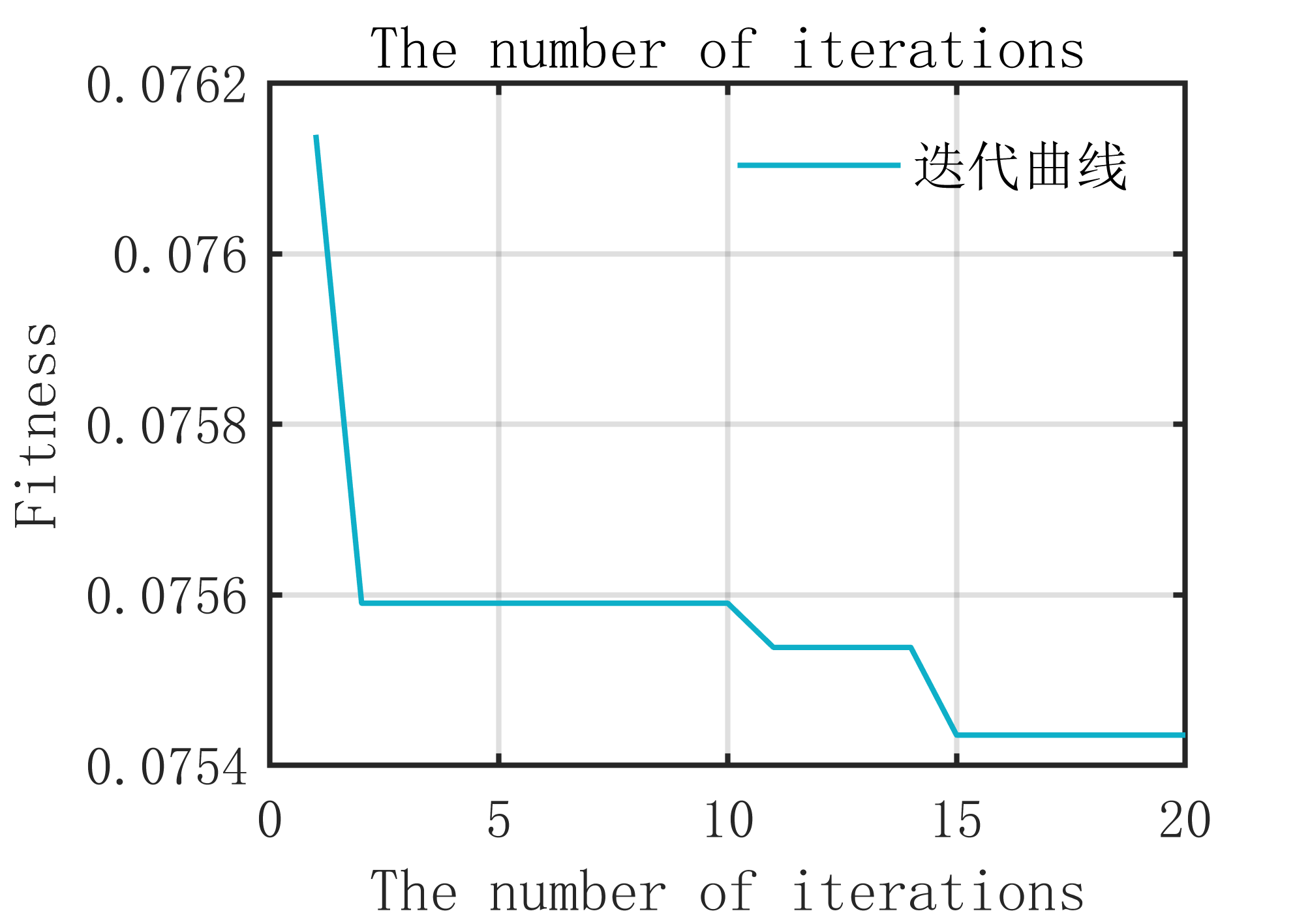
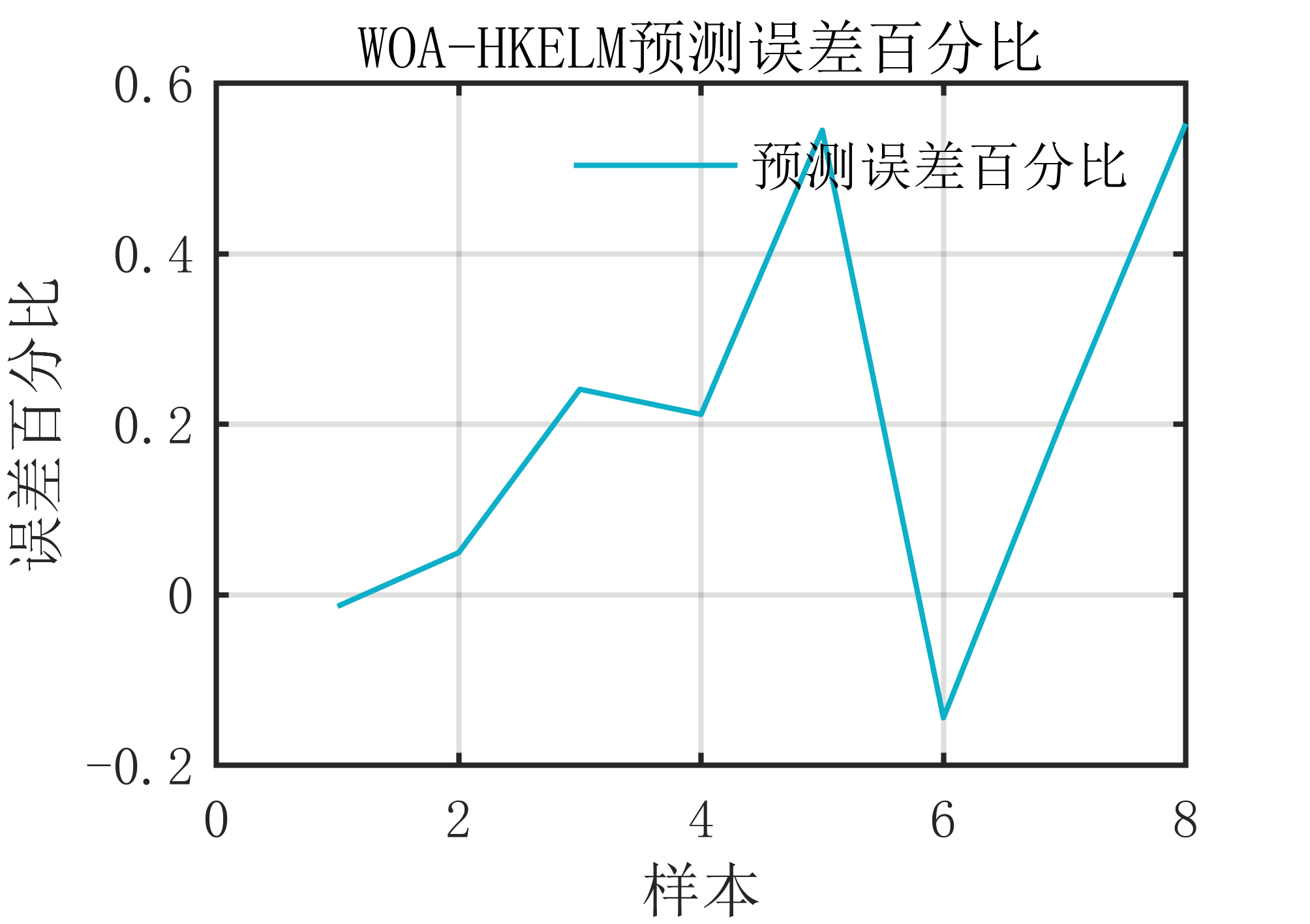
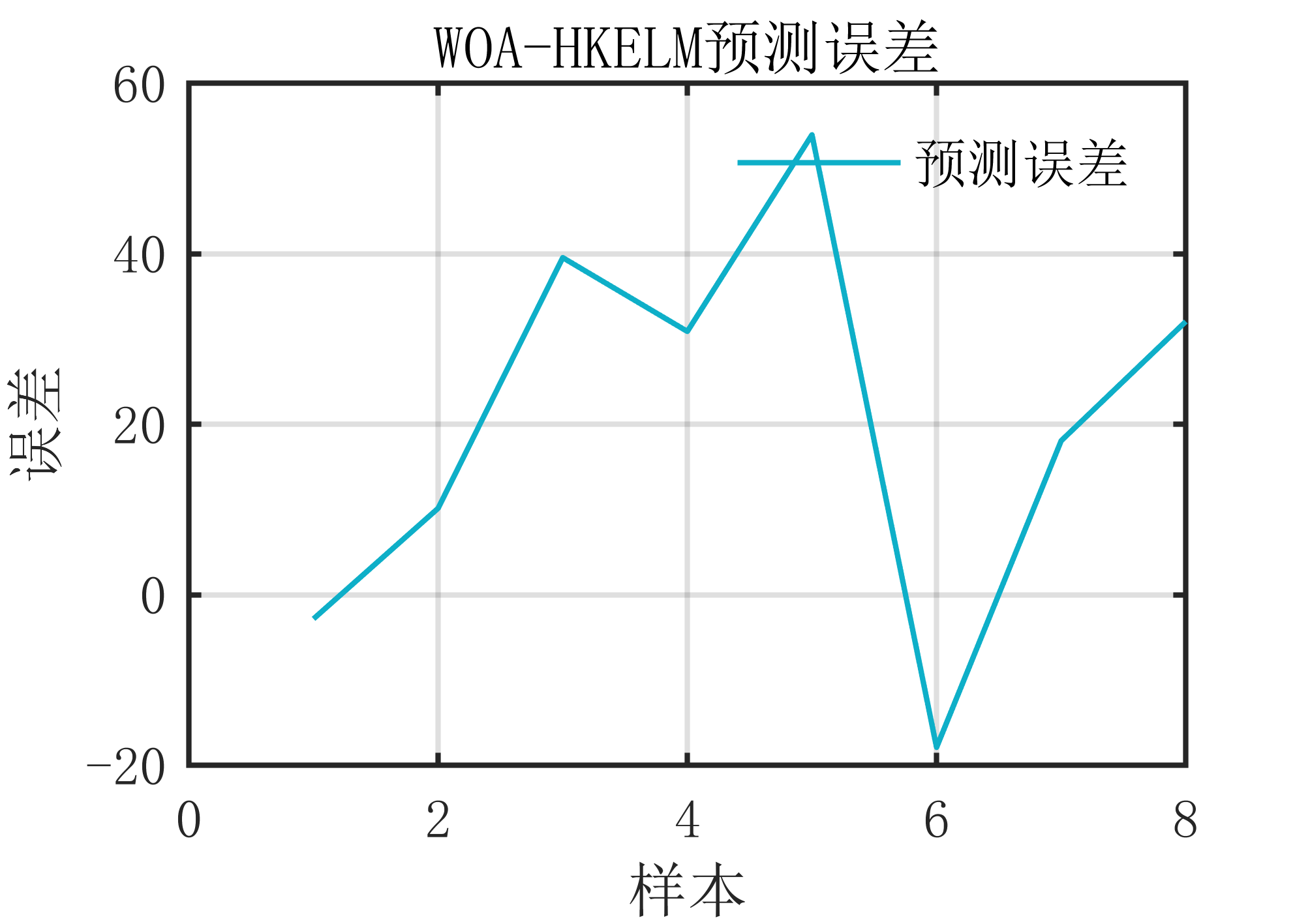
2 出图效果
附出图效果如下:
附视频教程操作:
【MATLAB】鲸鱼算法优化混合核极限学习机(WOA-HKELM)回归预测算法
这篇关于【MATLAB】鲸鱼算法优化混合核极限学习机(WOA-HKELM)回归预测算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


