本文主要是介绍推荐模型复现(二):精排模型DeepFM、DIN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.DeepFM模型
1.1 DeepFM模型产生背景
- DNN的参数过大:当特征One Hot特征转换为Dense Vector时,网络参数过大。
- FNN和PNN的交叉特性少:使用预训练好的FM模块,连接到DNN上形成FNN模型,后又在Embedding layer和hidden layer1之间增加一个product层,使用product layer替换FM预训练层,形成PNN模型
FNN:
PNN:PNN使用product的方式做特征交叉的想法是认为在ctr场景中,特征的交叉更加提现在一种“且”的关系下,而add的操作,是一种“或”的关系,所以product的形式更加合适,会有更好的效果。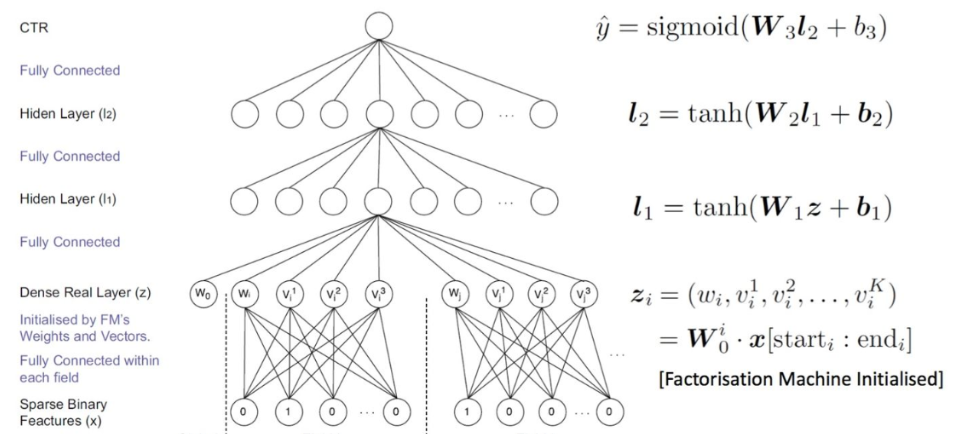
1.2 DeepFM模型
DeepFM主要在FNN和PNN的基础上,采用并行方式,结合FM Layer和Deep Layer,提高模型计算效率。

1.2.1 FM部分
主要功能:有效地训练出交叉特征的权重
模型公式:
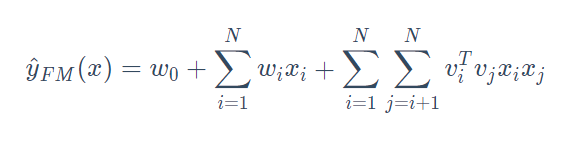
FM Layer主要是由一阶特征和二阶特征组合,再经过Sigmoid得到logits
FM Layer的优点:
- 通过向量内积作为交叉特征的权重,可以在数据非常稀疏的情况下,有效地训练出交叉特征的权重(因为不需要两个特征同时不为零)
- 计算效率非常高
- 尽管推荐场景下的总体特征空间非常大,但是FM的训练和预测只需要处理样本中的非零特征,这也提升了模型训练和线上预测的速度
- 由于模型的计算效率高,并且在稀疏场景下可以自动挖掘长尾低频物料,可适用于召回、粗排和精排三个阶段。应用在不同阶段时,样本构造、拟合目标及线上服务都有所不同“
1.2.2 Deep部分
- 使用全连接的方式将Dense Embedding输入到Hidden Layer,解决DNN中的参数爆炸问题
- Embedding层的输出是将所有id类特征对应的embedding向量连接到一起,并输入到DNN中
1.3 DeepFM代码
from torch_rechub.basic.layers import FM, MLP, LR, EmbeddingLayer
from tqdm import tqdm
import torchclass DeepFM(torch.nn.Module):def __init__(self, deep_features, fm_features, mlp_params):"""Deep和FM分别处理deep_features和fm_features两个不同的特征mlp_params表示MLP多层感知机的参数"""super().__init__()self.deep_features = deep_featuresself.fm_features = fm_featuresself.deep_dims = sum([fea.embed_dim for fea in deep_features])self.fm_dims = sum([fea.embed_dim for fea in fm_features])# LR建模一阶特征交互self.linear = LR(self.fm_dims)# FM建模二阶特征交互self.fm = FM(reduce_sum=True)# 对特征做嵌入表征self.embedding = EmbeddingLayer(deep_features + fm_features)# 设置MLP多层感知机self.mlp = MLP(self.deep_dims, **mlp_params)def forward(self, x):# Dense Embeddingsinput_deep = self.embedding(x, self.deep_features, squeeze_dim=True) input_fm = self.embedding(x, self.fm_features, squeeze_dim=False)y_linear = self.linear(input_fm.flatten(start_dim=1))y_fm = self.fm(input_fm)y_deep = self.mlp(input_deep)# 最终的预测值为一阶特征交互,二阶特征交互,以及深层模型的组合y = y_linear + y_fm + y_deep# 利用sigmoid将预测得分规整到0,1区间内return torch.sigmoid(y.squeeze(1))
2. DIN (深度兴趣网络)
2.1 DIN产生背景
- 历史信息关注度不足
- 单方面点击预测难以预测用户广泛的兴趣
- 历史数据量大
2.2 DIN模型

2.2.1 Base model

-
Activation Unit:
作用: 在当前候选广告和用户的历史行为之间引入注意力的机制,与当前商品更加相关的历史行为更能促进用户的点击行为。
举例: 在当前候选广告和用户的历史行为之间引入注意力的机制,与当前商品更加相关的历史行为更能促进用户的点击行为。

- Embedding Layer:将高维稀疏的输入转成低维稠密向量
- Pooling Layer and Concat Layer:将用户的历史行为的上述
- Embedding结果变成一个定长的向量,并进行拼接作为MLP的输入
- MLP:全连接层,学习特征的各种交互
- Loss:使用如下公式计算损失
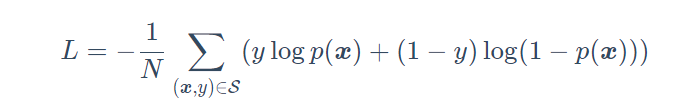
2.3 DIN代码
# 实现注意力部分
class ActivationUnit(torch.nn.Module):def __init__(self, emb_dim, dims=[36], activation="dice", use_softmax=False):super(ActivationUnit, self).__init__()self.emb_dim = emb_dimself.use_softmax = use_softmax# Dice(36)self.attention = MLP(4 * self.emb_dim, dims=dims, activation=activation)def forward(self, history, target):seq_length = history.size(1)target = target.unsqueeze(1).expand(-1, seq_length, -1)# Concatatt_input = torch.cat([target, history, target - history, target * history], dim=-1) # Dice(36)att_weight = self.attention(att_input.view(-1, 4 * self.emb_dim)) # Linear(1)att_weight = att_weight.view(-1, seq_length)if self.use_softmax:att_weight = att_weight.softmax(dim=-1)# (batch_size,emb_dim)output = (att_weight.unsqueeze(-1) * history).sum(dim=1)return output
# DIN的实现
class DIN(torch.nn.Module):def __init__(self, features, history_features, target_features, mlp_params, attention_mlp_params):super().__init__()self.features = featuresself.history_features = history_featuresself.target_features = target_features# 历史行为特征个数self.num_history_features = len(history_features)# 计算所有的dimself.all_dims = sum([fea.embed_dim for fea in features + history_features + target_features])# 构建Embeding层self.embedding = EmbeddingLayer(features + history_features + target_features)# 构建注意力层self.attention_layers = nn.ModuleList([ActivationUnit(fea.embed_dim, **attention_mlp_params) for fea in self.history_features])self.mlp = MLP(self.all_dims, activation="dice", **mlp_params)def forward(self, x):embed_x_features = self.embedding(x, self.features)embed_x_history = self.embedding(x, self.history_features)embed_x_target = self.embedding(x, self.target_features)attention_pooling = []for i in range(self.num_history_features):attention_seq = self.attention_layers[i](embed_x_history[:, i, :, :], embed_x_target[:, i, :])attention_pooling.append(attention_seq.unsqueeze(1)) # SUM Poolingattention_pooling = torch.cat(attention_pooling, dim=1)# Concat & Flattenmlp_in = torch.cat([attention_pooling.flatten(start_dim=1),embed_x_target.flatten(start_dim=1),embed_x_features.flatten(start_dim=1)], dim=1)# 可传入[80, 200]y = self.mlp(mlp_in)# 代码中使用的是sigmoid(1)+BCELoss,效果和论文中的DIN模型softmax(2)+CELoss类似return torch.sigmoid(y.squeeze(1))
3. 总结
- Deep在FNN和PNN的基础上,采用并行方式,结合了FM 有效实现交叉特征的优点,有效提高了模型的预测效果。
- DIN主要结合了历史信息,利当前信息与客户历史信息的相似度来确认对历史信息的关注度,有效利用了客户的历史信息,提高了对客户点击预测。
参考:
我的组队学习
推荐模型之DeepFM与DIN_莱维贝贝、的博客-CSDN博客
这篇关于推荐模型复现(二):精排模型DeepFM、DIN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





