本文主要是介绍Python数据分析案例-中国电影网电影数据可视化分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天来给大家分享一个Python数据分析案例-中国电影网电影数据可视化分析
需要用到的包有:pandas,numpy,datetime,matplotlib.pyplot,seaborn,pyecharts,pygwalker
一. 数据获取
Excel数据展示如下:

导入包并获取数据:
# 导入包和数据
import pandas as pd
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
import seaborn as sns
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType
sns.set_style('ticks')
import warnings
warnings.filterwarnings('ignore') # 忽略警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示data = pd.read_excel('moive.xlsx')
data.head()二. 数据预处理
查看数据信息
data.info()缺失值处理
# 是否有缺失值
data.isnull().any()
# 删除具有缺失值的行
data.dropna(inplace=True)
data.reset_index(drop=True,inplace=True)重复值处理
# 删除重复值
data=data.drop_duplicates()
# 检查一下,看看是不是真的删掉了重复行
duplicatedFlag = data.duplicated(keep=False) # 重复的行,均标记为True
booleanIdx = duplicatedFlag.to_numpy()三. 可视化分析
3.1 时间
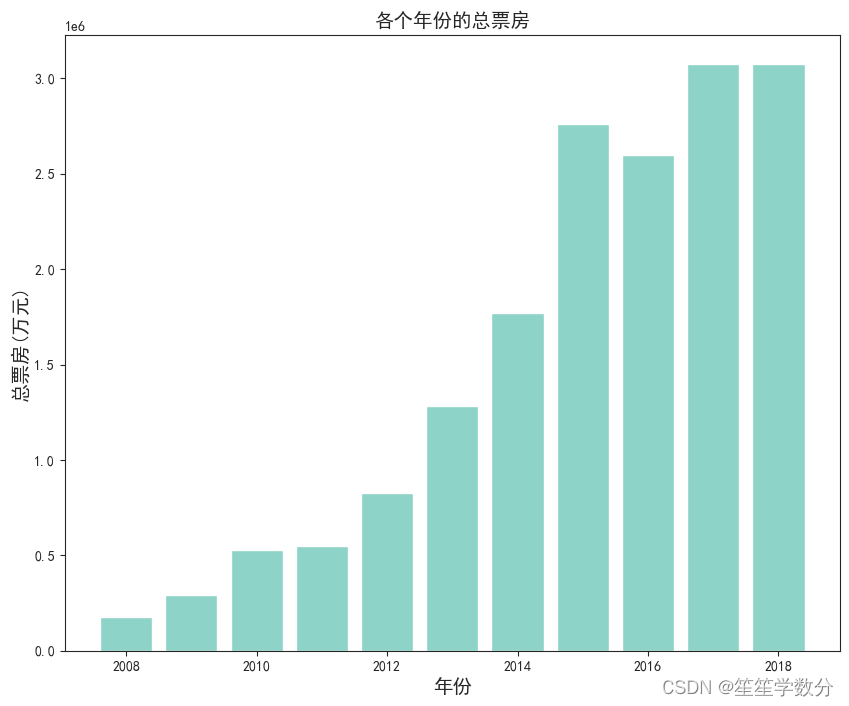
3.1.1 各个年份的总票房
分析各个年份的总票房
# 去掉上映日期里面的“(中国)”,方便后续对上映时间的分析
data['上映时间']=pd.to_datetime(data['上映时间'].replace('(中国)',''))
# 新增“上映年份”列
data['上映年份']=data['上映时间'].dt.year
# data['上映年份'] = data['上映时间'].astype('str').apply(lambda x:x.split('-')[0]) 法三
# 观察到“累计票房”列数据类型为“累计票房47159.2万”,需要将数据提取出来
data['票房'] = data['累计票房'].astype('str').apply(lambda x:x[4:][:-1]).astype('float')
# data['票房'] = data['票房'].apply(lambda x : float(x[i]) for i in range(len(data['票房'])))
df1 = data['票房'].groupby(data['上映年份']).sum()
# 绘图
plt.figure(figsize=(10,8))
plt.title('各个年份的总票房',fontsize=14)
plt.xlabel('年份',fontsize=14)
plt.ylabel('总票房(万元)',fontsize=14)
plt.bar(x=df1.index,height=df1.values)
plt.show()结果展示如下,可得出从2008年到2018年票房整体呈上升趋势。
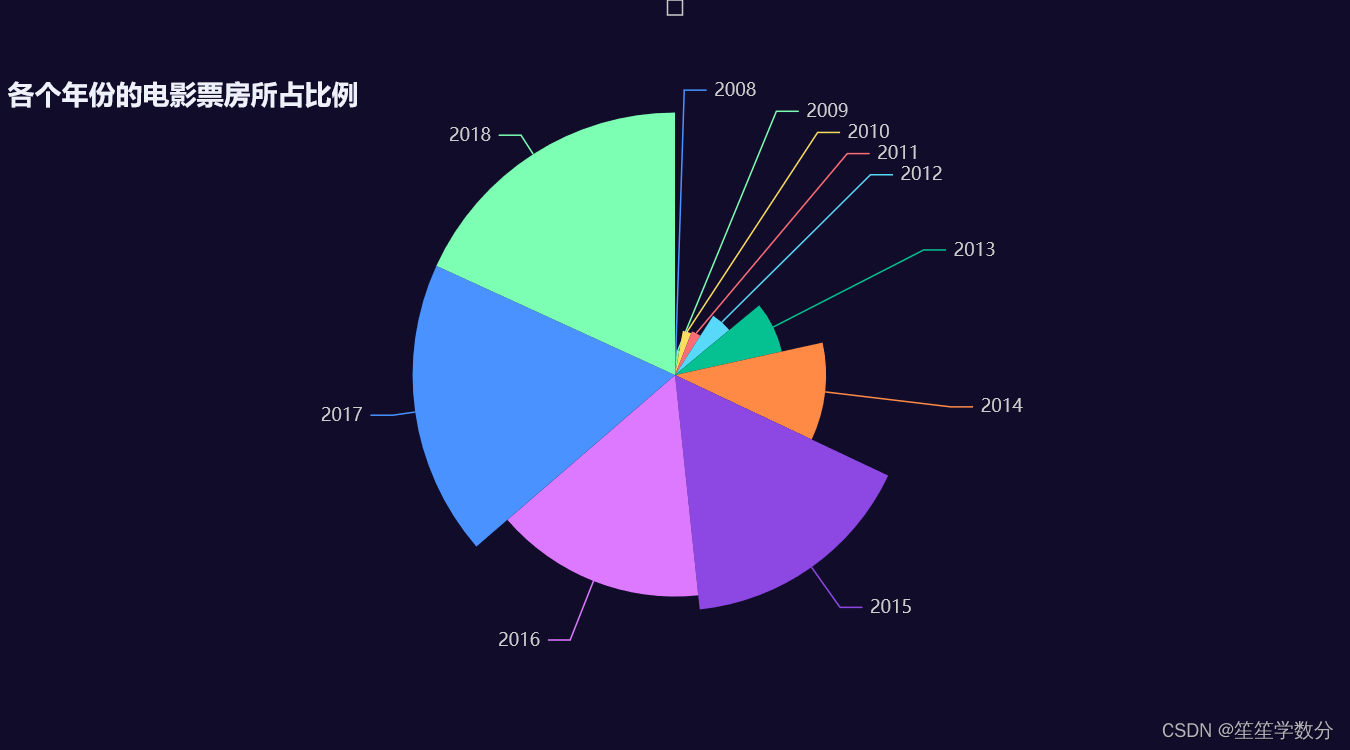
3.1.2 各个年份的电影票房所占比例
分析各个年份的电影票房所占比例
# 各个年份的电影票房所占比例
result_list = [(i,j) for i,j in zip(df1.index.to_list(),df1.values.tolist())]
a = Pie(init_opts=opts.InitOpts(theme = ThemeType.DARK)) # 主题:黑色
a.add(series_name='年份',data_pair=result_list,rosetype='radius',radius='70%',)
a.set_global_opts(title_opts=opts.TitleOpts(title="各个年份的电影票房所占比例",pos_top=50))
a.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a.render()结果展示如下,也可得出从2008年到2018年票房整体呈上升趋势。
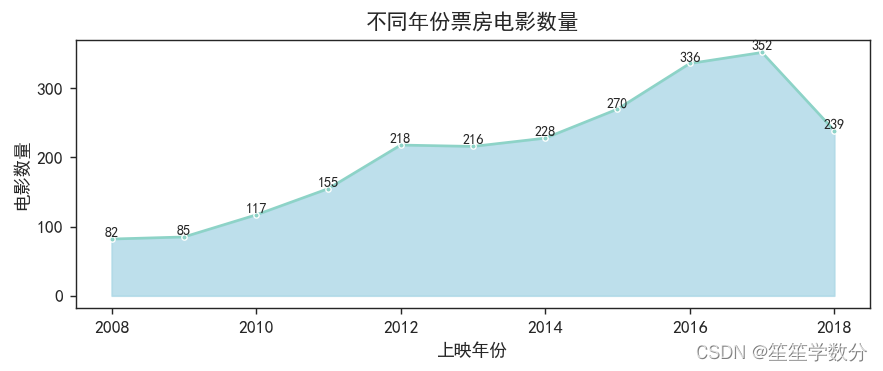
3.1.3 各个年份的上映电影数量
分析各个年份的上映电影数量
# 不同年份的票房电影数量:
plt.figure(figsize=(7, 3), dpi=128)
year_count = data['上映年份'].value_counts().sort_index()
sns.lineplot(x=year_count.index, y=year_count.values, marker='o', lw=1.5, markersize=3)
plt.fill_between(year_count.index, 0, year_count, color='lightblue', alpha=0.8)
plt.title('不同年份票房电影数量')
plt.xlabel('上映年份')
plt.ylabel('电影数量')
# 在每个数据点上标注数值
for x, y in zip(year_count.index, year_count.values):plt.text(x, y+0.2, str(y), ha='center', va='bottom', fontsize=8)plt.tight_layout()
plt.show()结果展示如下,可以看到,我国高票房的电影,从2008年开始增长,到2017年到达峰值,著名的《战狼2》就是2017年上映的,然后2018开始下降。
3.1.4 各个月份的上映电影数量
分析各个月份的上映电影数量
# 对票房电影不同月份的占比百分比分析:
# 新增“上映月份”列
data['上映月份']=data['上映时间'].dt.month
plt.figure(figsize=(4, 4),dpi=128)
month_count = data['上映月份'].value_counts(normalize=True).sort_index()
# 绘制饼图
sns.set_palette("Set3")
plt.pie(month_count, labels=month_count.index, autopct='%.1f%%', startangle=140, counterclock=False,wedgeprops={'alpha': 0.9})
plt.axis('equal') # 保证饼图是正圆形
plt.text(-0.3,1.2,'不同月份票房电影数量',fontsize=8)
plt.tight_layout()
plt.show()结果展示如下,可以看到,票房电影主要集中在8月,9月,两个月份区间,因为电影喜欢在暑假上映。

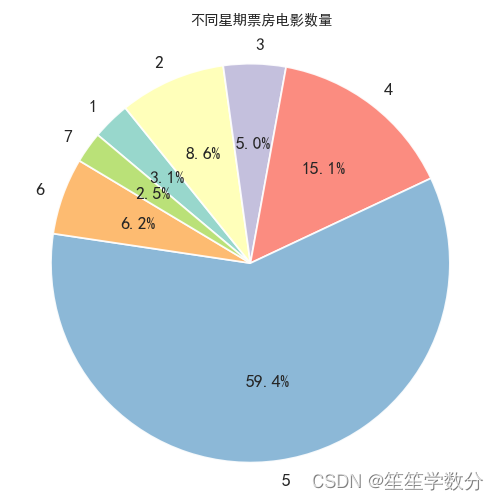
3.1.5 各个星期的上映电影数量
分析各个星期的上映电影数量
# 对票房电影不同上映星期的占比百分比分析:
# 新增“上映星期”列
data['上映星期'] = data['上映时间'].map(datetime.isoweekday)
plt.figure(figsize=(4, 4),dpi=128)
week_count = data['上映星期'].value_counts(normalize=True).sort_index()
# 绘制饼图
sns.set_palette("Set3")
plt.pie(week_count, labels=week_count.index, autopct='%.1f%%', startangle=140, counterclock=False,wedgeprops={'alpha': 0.9})
plt.axis('equal') # 保证饼图是正圆形
plt.text(-0.3,1.2,'不同星期票房电影数量',fontsize=8)
plt.tight_layout()
plt.show()结果展示如下,可以看到,票房电影主要集中周五上映,可能是因为休息日即将到来,上班族比较想放松一下,导致电影倾向于在周五上映。
折线图代码及结果展示如下,仍然可以看到票房电影主要集中周五上映。
# 绘制折线图
data.groupby('上映星期')[['电影名']].count().plot()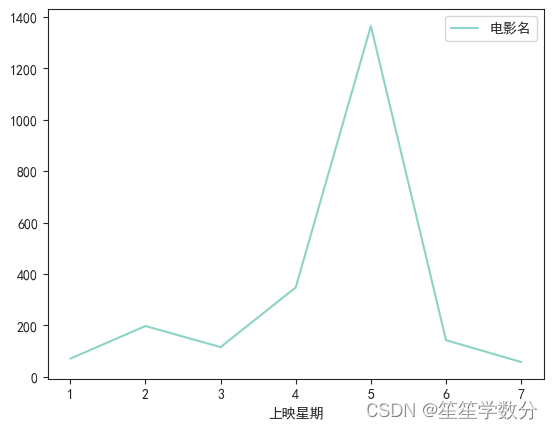
3.1.6 pygwalker分析
导入pygwalker包
import pygwalker as pyg
pyg.walk(data)结果展示如下,仍然可以看到每月的电影主要集中周五上映。

3.2 电影类型
3.2.1 各种类型电影的词云图
绘制各种类型电影的词云图
# 分析各种类型的电影出现的次数
from pyecharts.charts import WordCloud
import collections
result_list = []
for i in data['类型'].values:word_list = str(i).split('/')for j in word_list:result_list.append(j)
result_list
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
# 绘制词云图
wc = WordCloud()
wc.add('',word_counts_top)
wc.render()结果展示如下,从图中可以看出,爱情、喜剧、剧情、动作类电影类型更多。

3.2.2 各种类型电影的饼图
绘制各种类型电影的饼图
# 分析各种类型电影的比例
word_counts_top = word_counts.most_common(10) # 获取前10最高频的词
a3 = Pie(init_opts=opts.InitOpts(theme = ThemeType.MACARONS))
a3.add(series_name='类型',data_pair=word_counts_top,rosetype='radius',radius='60%',)
a3.set_global_opts(title_opts=opts.TitleOpts(title="各种类型电影的比例",pos_left='center',pos_top=50))
a3.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a3.render()结果展示如下,仍可从图中可以看出,爱情、喜剧、剧情、动作类电影类型更多。

3.3 上映电影数前五的发行公司
分析上映电影数前五的发行公司
# 分析拍电影数前五的发行公司
df3 = data['发行公司'].value_counts().head()
a1 = Pie(init_opts=opts.InitOpts(theme = ThemeType.CHALK))
a1.add(series_name='发行公司',data_pair=[list(z) for z in zip(df3.index.to_list(),df3.values.tolist())],rosetype='radius',radius='60%',)
a1.set_global_opts(title_opts=opts.TitleOpts(title="拍电影数前五的发行公司",pos_left='center',pos_top=30))
a1.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a1.render()结果展示如下,从图中可以得出,中国电影集团上映电影最多。
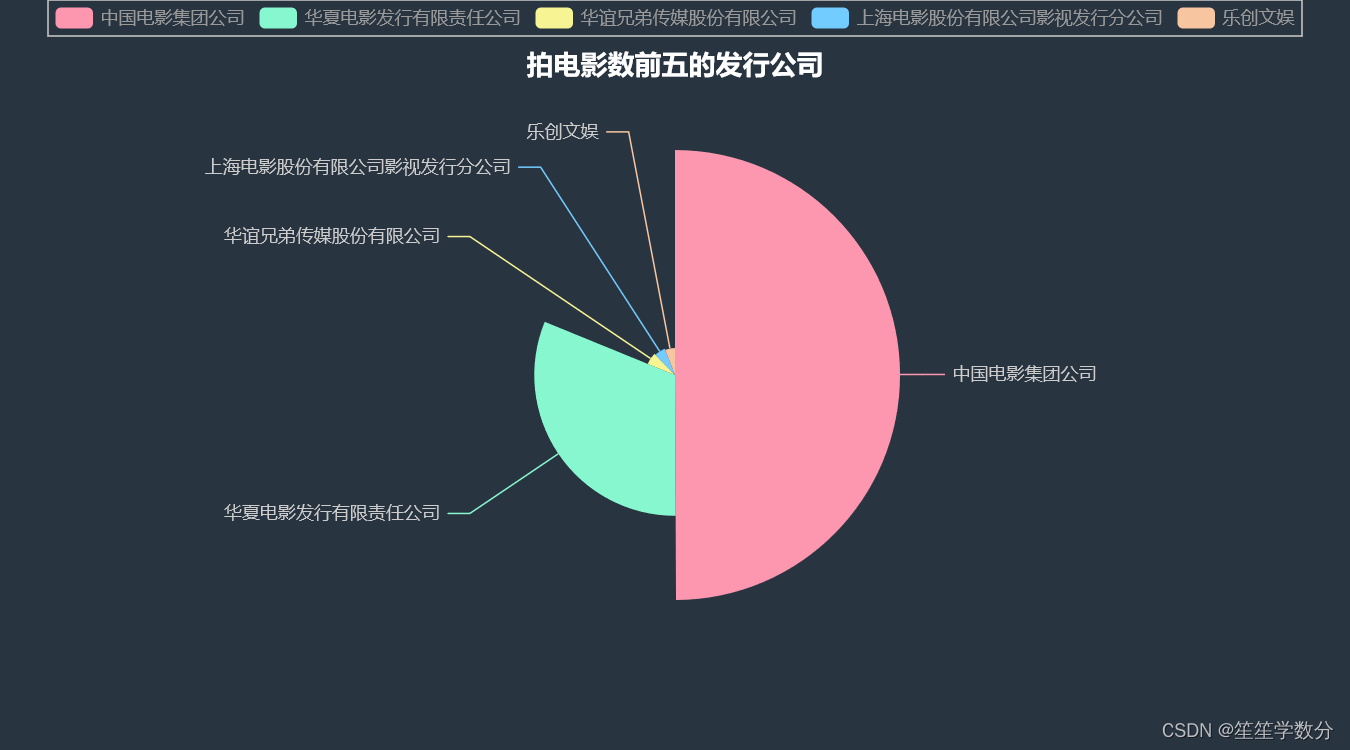
3.4 票房排名前20的电影
分析各个年份的上映电影数量
# 对票房排名前20的电影画柱状图
# 发现“电影名”列的数据形如“让子弹飞(2010)”
data['电影名'] = data['电影名'].apply(lambda x : x.split('(')[0])
# 选出票房前20的电影
top_movies = data.nlargest(20, '票房')
plt.figure(figsize=(7, 4),dpi=128)
ax = sns.barplot(x='票房', y='电影名', data=top_movies, orient='h',alpha=0.5)
#plt.xticks(rotation=80, ha='center')# 在柱子上标注数值
for p in ax.patches:ax.annotate(f'{p.get_width():.2f}', (p.get_width(), p.get_y() + p.get_height() / 2.),va='center', fontsize=8, color='gray', xytext=(5, 0),textcoords='offset points')plt.title('票房前20的电影')
plt.xlabel('票房数量(万元)')
plt.ylabel('电影名称')
plt.tight_layout()
plt.show()结果展示如下,截止到2018年,《战狼2》票房最高,其次是《红海行动》。
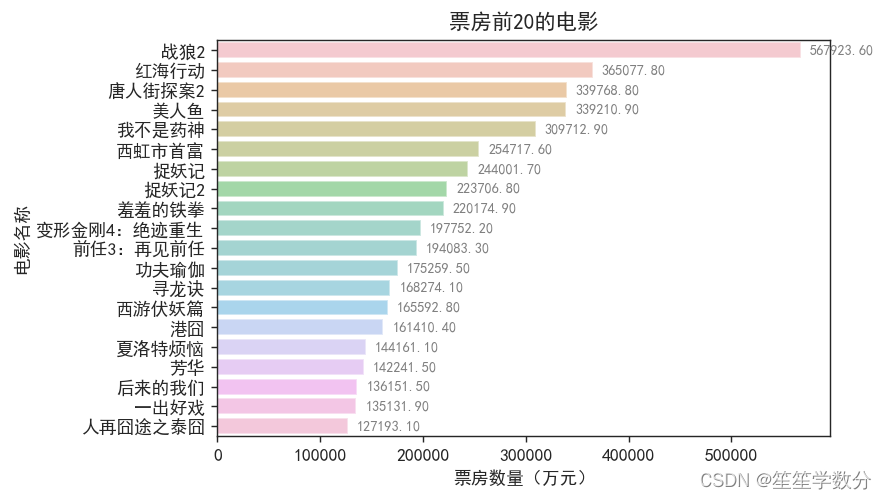
四. 心得体会
借助B站的相关视频,系统学习了《利用Python进行数据分析(第二版)》,学的时候感觉还挺顺利,感觉没什么难点,但一到实际操作阶段,就会Bug百出,而且Python的知识点太多太琐碎,需要充分利用Python自带的搜索功能以及各种搜索引擎,遇到不会的要学会自己检索并记录下来。
总之需要不断学习,不断充实自己。
好啦,本期就分享到这里!
这篇关于Python数据分析案例-中国电影网电影数据可视化分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





