本文主要是介绍深度学习之google deepmind的alphago AI人工智能算法技术演变历程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、简介
最近大家比较关心的围棋人机大战(alphago vs 李世石)中,deep mind基于Nature2016文章的alphago在5局制的比赛中已经取得了3-1的成绩提前锁定了胜局。2016年google与facebook两个大拿在围棋领域基于深度学习都发表了文章,其中facebook文章如下:《BETTER COMPUTER GO PLAYER WITH NEURAL NET- WORKAND LONG-TERM PREDICTION》 ;Google文章如下:《Mastering the game of Go with deep neural networks and tree search》。这两篇文章都是蒙特卡洛搜索树+DCNN,效果google的alphago优于facebook的方法,刚好借此机会将之前看到的deep mind该领域的文章捋了一下。
google在alphago之前就已经发表了相当多这方面的demo(https://www.youtube.com/channel/UCP7jMXSY2xbc3KCAE0MHQ-A)与文章,从其最早的NIPS2013文章《Playing Atari with Deep ReinforcementLearning》到现在的Nature2016 《Mastering the game of Go with Deep Neural Networks & Tree Search》。deep mind在此期间做了很多扎实的研究工作,本文将进行简单的描述。本文接下去会按如下几点内容进行叙述:1.Q-learning 2. Reinforcement learning 3. deep Q-Networks 4. alphago
二、Q-learning与Reinforcement learning
增强学习Reinforcement learning的场景大部分有一个共同的特点,那就是这些场景有序列决策或者控制的问题,对于当前的任何一个state不能明确的对不同的action给出一个事先well defined的score值。它大多应用于如下的领域:机器人控制,市场决策,工业控制等。
Q-learning是用于解决Reinforcement learning问题的一种常见方法,其经典的公式如下:

三、deep Q-Networks(DQN)
2013发表NIPS文章《Playing Atari with Deep ReinforcementLearning》是deep mind公开的最早使用raw pixels作为输入的,用于解决reinforcement learning的深度学习网络DQN。在该文章中,作者在atari一系列的游戏上做了各种算法的比较,如下图所示:
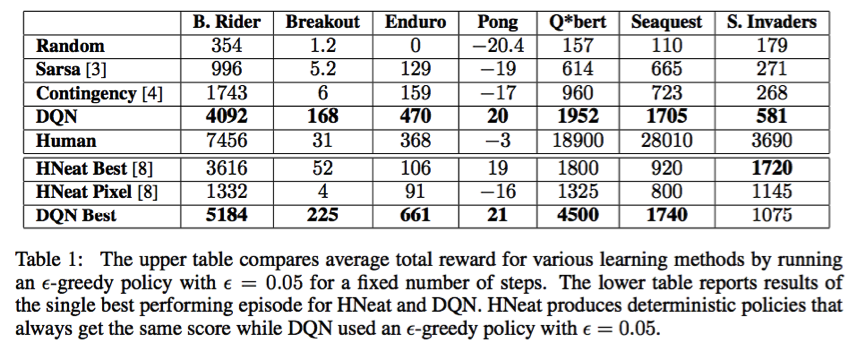
在总共7个游戏中,有6个做到了算法中最好,其中还有3个做到了比人类专家还要好。该文章中提到的DQN有两个特点:1. 用来更新参数的minibatch是是从replay memory(回放记忆)中采样出来的,而不是仅仅的用当前一个片段或者session,这样能使得模型收敛性更好,否则会很容易训飞。2. value函数是一个多层网络。
在上述文章提出后,deep mind在该问题上不停的打磨,不断的优化其工程与算法:
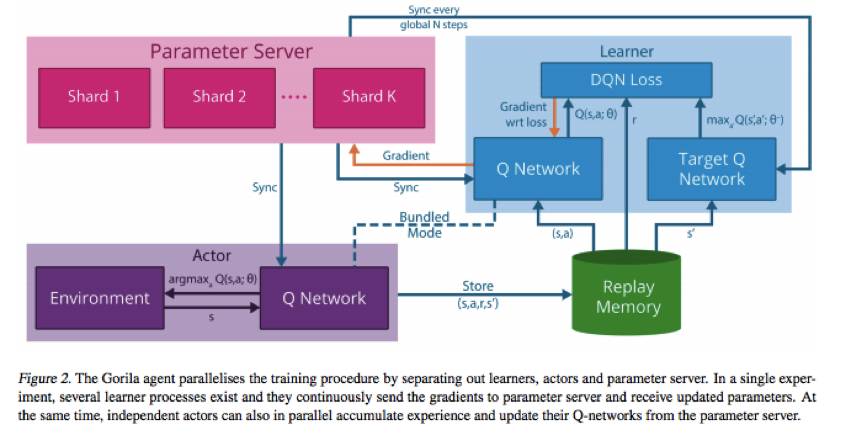
1. 2015发表ICML文章《MassivelyParallel Methods for Deep Reinforcement Learning》,该文章从工程上了做了4个方面的分布式:学习、决策、价值、经验,第1个属于学习,第2、3个属于网络方面,第4个偏存储方面。DQN的全面分布式将DQN的学习时间成本与模型效果都提升了一个档次。DQN分布式结构简要如下:
2. 2016发表ICLR文章《PRIORITIZEDEXPERIENCE REPLAY》,该文章指出了原DQN中经验均匀采样的问题,并从防过拟合、防局部最优这些点上,设计了介于均匀采样与纯优先级贪心之间的经验采样方法,提出的这个改进再次将DQN的模型效果提升了一个档次。
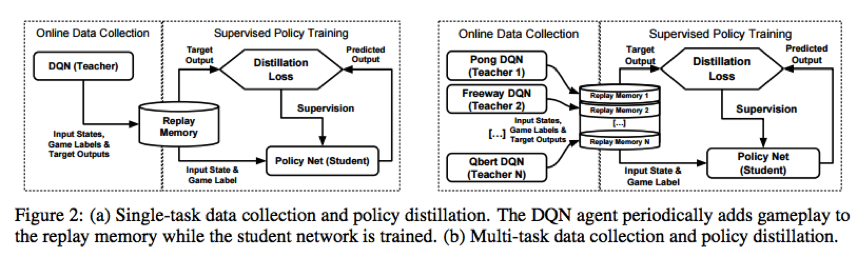
3. 2016发表ICLR文章《PolicyDistillation》,该篇文章实际上是做了DQN的transfer learning的实验,有很多思想与hinton的dark knowledge里面的东西都很相似,其方法示意图如下所示:
四、alphago
训练阶段:
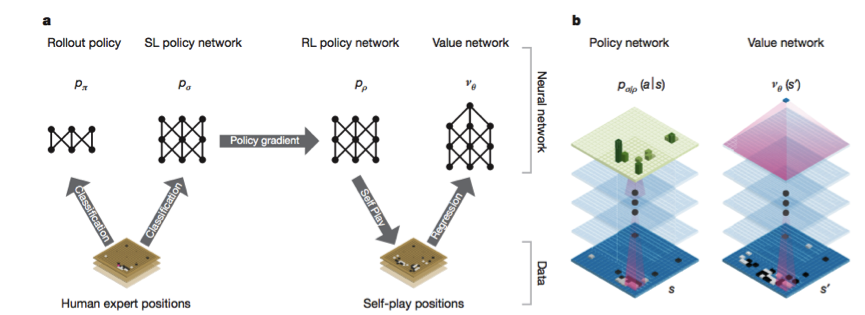
1. policy network(14层,输出棋盘每步move概率值),它首先采用supervisedlearning训练方法在KGS数据集上达到了55.7%的专家moves预测准确率,然后由reinforcement learning训练方法进行自我训练(每一次训练都在前几次迭代完的模型中随机一个模型做决策),自我训练的policy network在80%的情况下打败了supervised learning训练出来的policy network。
2. value network(15层,预测棋盘下一步move),该网络由pair训练数据做regressionloss反馈更新得到。在KGS的数据集上,该训练方法出现了过拟合的现象(训练MSE0.19,测试MSE0.37),但若在reinforcement learning学出来的policy network基础上产生出的自我训练集里进行采样学习的话,就可以有效的避免该问题(训练MSE0.226,测试MSE0.234)。
预测阶段:
在alphago系统模拟的时候,每一个action由如下三个因素决定:s状态下a的访问次数,RL policy network for action value,SL policy networkfor prior probability;在alphago系统模拟的时候,每一个叶子节点价值由如下两个因素决定:value network,rollout network;在alphago系统所有模拟都结束后,由上述两点计算得到s状态下a的value值。综上RL与SL学习出来的两个policy network共同决定了蒙特卡洛搜索树节点的选择,value network与rollout network决定了模拟出来的叶子节点的价值,最终s状态下a的value由上述两部分共同影响得到。最后alphago系统选择s状态下最优的action作为围棋当前的move。
这篇关于深度学习之google deepmind的alphago AI人工智能算法技术演变历程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





