本文主要是介绍Ocr之TesseractOcr的安装及使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、安装环境
二、安装内容
三、安装过程及识别测试
1. 安装过程
2. 程序编写
总结
1. 安装复杂度较低
2. 国外开源Ocr
3. 可设置识别参数
4. 工具类
一、 系统环境windows 10
linux环境也可安装, 可借鉴此篇文章>> |
二、安装内容
Tesseract exe 程序安装
exe程序下载地址, 可选择版本安装>> |
# 我们这里安装的版本是
tesseract-ocr-w64-setup-5.3.1.20230401.exe
三、安装过程及识别测试
1. 安装过程
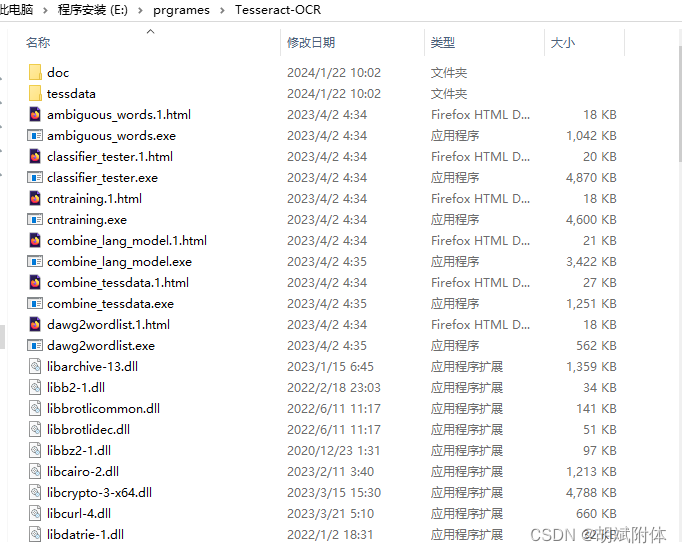
- 安装后的目录结构
默认安装在C盘。可选择路径。傻瓜式安装就可以
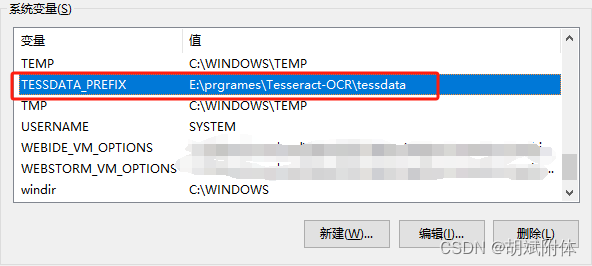
- 添加环境变量
TESSDATA_PREFIX=<安装的tessoract-ocr.exe后文件夹根路径>/tessdata
2. 程序编写
-
使用Tesseract进行识别程序的编写
目前使用TesseractOcr已经更换为 PaddleOcr 了。源于TesseractOcr对背景模糊的图片识别率不高,使用PaddleOcr后识别率有明显提高。
不过使用PaddleOcr识别过程会将图片进行预处理(图片放大和模糊处理再使用paddleocr识别效果更佳:后期会做记录并将链接加到此处) -
使用java程序进行识别需要引用 mvn 第三方依赖
<!--ocr图像识别--><dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>5.3.0</version></dependency> -
单元测试用例+执行结果

下方代码中对上方图片进行识别(图片名称:new33.jpg)@Test public void readImageByOcr() throws TesseractException {String imgSrc = "C:\\...\\changepic\\new33.jpg";File imgFile = new File(imgSrc);//创建tesseract对象Tesseract tes = new Tesseract();//语言包位置 根据实际环境修改替换tes.setDatapath("E:\\...\\Tesseract-OCR\\tessdata");//配置使用的语言 中文tes.setLanguage("eng");String imgText = tes.doOCR(imgFile);System.out.println("解析结果:" + imgText); }执行后

-
业务代码示例
结合业务代码使用TesseractOcr。TesseractOcr使用时可传入不通参数。如language, variable等。
tessedit_char_whitelist:设置白名单。下方demo限制内容为只能识别数字和字母/*** ocr识别* @param img* @param dataPath* @param replacedEmp 是否替换回车和空格为空, true:替换, false, 不替换(含回车和空格符)* @param dpi 分辨率, 默认 96* @param charNoLimit 识别空格: true, 不识别空格: false* @return* @throws TesseractException*/private static String doOcrImpl(BufferedImage img, String dataPath, boolean replacedEmp, String dpi, boolean charNoLimit) throws TesseractException {// 初始化 OCR 引擎Tesseract tesseract = new Tesseract();File tessDataFolder = LoadLibs.extractTessResources("tessdata");tesseract.setDatapath(tessDataFolder.getAbsolutePath());//语言包位置 根据实际环境修改替换tesseract.setDatapath(dataPath);//配置使用的语言 中文tesseract.setLanguage("eng");if(!charNoLimit) {//限制只识别数字字母tesseract.setVariable("tessedit_char_whitelist", "0123456789CDFGMRTX");}//设置分辨率tesseract.setVariable("user_defined_dpi", dpi);String result = tesseract.doOCR(img);if(replacedEmp) {// 文字识别-过滤空白、换行符result = result.replace(StrUtil.SPACE, StrUtil.EMPTY).replace(StrUtil.LF, StrUtil.EMPTY);}return result;}
总结
- 安装复杂度较低。
相比于paddleocr的安装要简单的多(需要安装python环境及下载paddleocr相关内容)。paddleocr安装借鉴 gitee paddleocr开源代码>> | - 属于国外开源Ocr。
- 可设置识别参数。可设置变量与识别语言。
- 使用Ocr时用到的工具类。可自行测试
package util;import cn.hutool.core.util.StrUtil;
import common.aspect.core.StringUtils;
import common.exception.CustomException;
import PO.RecognizeTemplate;
import service.PrintDcmOcrRecognizeService;
import lombok.extern.slf4j.Slf4j;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import net.sourceforge.tess4j.util.LoadLibs;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.PDFRenderer;
import org.springframework.beans.factory.annotation.Value;import javax.imageio.ImageIO;
import javax.imageio.ImageReader;
import javax.imageio.stream.ImageInputStream;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.awt.image.RasterFormatException;
import java.io.File;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;@Slf4j
public class ReadTextFromFileRegion {/*** @Description: ocr按区域识别文件**/public static String doRecognize(File file, Rectangle rectangle, String dataPath, String formateName, String dpi)throws Exception {if (!file.exists()) {throw new CustomException(0, "待识别文件不存在");}// OCR 文字识别return doOcr(createImg(file, rectangle, formateName), dataPath, dpi);}/*** file: 图片文件* rectangle: 图片中需要识别的区域。如new Rectangle(x, y, w, h), 坐标及宽高* dataPath: tessData的路径(文章开头已添加到环境变量,也可传入)* formateName: file文件的格式。如 JPG, PNG, DICOM等, * dpi: tesseractOcr识别时传入的参数。如:tesseract.setVariable("user_defined_dpi", dpi);*/public static String doRecognizeOrcOriginResult(File file, Rectangle rectangle, String dataPath, String formateName, String dpi)throws Exception {if (!file.exists()) {throw new CustomException(0, "待识别文件不存在");}// OCR 文字识别return doOcrImpl(createImg(file, rectangle, formateName), dataPath, false, dpi, true);}/*** 截取的图像缓冲区*/private static BufferedImage createImg(File file, Rectangle rectangle, String formateName) throws Exception {BufferedImage img = readFile(file, rectangle, formateName);if(img == null) {log.warn("读取图像异常: img == null");throw new Exception("文件读取异常, 创建img为空.");}return img;}/*** @Description: 把文件转为BufferedImage对象,并截取指定区域**/private static BufferedImage readFile(File file, Rectangle region, String formateName) throws IOException {ImageInputStream iis = null;ImageReader reader = null;try {// 创建 ImageInputStream 对象iis = ImageIO.createImageInputStream(file);// 获取 指定 文件的 ImageReader 实例reader = ImageIO.getImageReadersByFormatName(formateName).next();// 设置解码器reader.setInput(iis);// 如果需要截取图像,获取完整的BufferedImage,然后截取指定区域BufferedImage image = reader.read(0);BufferedImage subImage = null;try{subImage = image.getSubimage(region.x, region.y, region.width, region.height);}catch (RasterFormatException e) {log.warn("截取图像异常: 识别区域超出边界. err.msg: {}", e.toString());return subImage;}// 释放完整的BufferedImageimage.flush();return subImage;} finally {// 关闭资源if (reader != null) {reader.dispose();}if (iis != null) {iis.close();}}}/*** @Description: ocr按区域识别pdf文件**/public static String doPdfRecognize(File pdfFile, String dataPath) throws Exception {BufferedImage img = readPdfToImage(pdfFile);// 按自定义区域截取图像BufferedImage subImage = img.getSubimage(460, 170, 320, 100);// OCR 文字识别return doOcr(subImage, dataPath, "120");}/*** @Description: 把pdf转为图像,renderImageWithDPI方法的第二个参数dpi影响图像分辨率,经测试dpi为300,生成2k分辨率的图像**/private static BufferedImage readPdfToImage(File pdfFile) throws IOException {try (PDDocument document = PDDocument.load(pdfFile)) {PDFRenderer renderer = new PDFRenderer(document);return renderer.renderImageWithDPI(0, 300);}}/*** @Description: 使用Tesseract进行ocr识别**/private static String doOcr(BufferedImage img, String dataPath, String dpi) throws TesseractException {return doOcrImpl(img, dataPath, true, dpi, false);}/*** ocr识别* @param img* dataPath: tessData的路径(文章开头已添加到环境变量,也可传入)* @param replacedEmp 是否替换回车和空格为空, true:替换, false, 不替换(含回车和空格符)* @param dpi 分辨率, 默认 96* @param charNoLimit 识别空格: true, 不识别空格: false* @return* @throws TesseractException*/private static String doOcrImpl(BufferedImage img, String dataPath, boolean replacedEmp, String dpi, boolean charNoLimit) throws TesseractException {// 初始化 OCR 引擎Tesseract tesseract = new Tesseract();File tessDataFolder = LoadLibs.extractTessResources("tessdata");tesseract.setDatapath(tessDataFolder.getAbsolutePath());//语言包位置 根据实际环境修改替换tesseract.setDatapath(dataPath);//配置使用的语言 中文tesseract.setLanguage("eng");if(!charNoLimit) {//限制只识别数字字母tesseract.setVariable("tessedit_char_whitelist", "0123456789CDFGMRTX");}//设置分辨率tesseract.setVariable("user_defined_dpi", dpi);String result = tesseract.doOCR(img);if(replacedEmp) {// 文字识别-过滤空白、换行符result = result.replace(StrUtil.SPACE, StrUtil.EMPTY).replace(StrUtil.LF, StrUtil.EMPTY);}return result;}
}这篇关于Ocr之TesseractOcr的安装及使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






