本文主要是介绍ERA5数据下载的那些事,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ERA5数据下载那些事
- 基本操作
- 常见问题汇总
- 资源分享
基本操作
近年做的数据处理都是气象气候数据,最近需要处理ERA5的suface data(以下简称2D数据)和pressure level data(以下简称3D数据),第一个碰到的问题就是下载数据的问题。
数据下载方案初步设计有三:
- 租国外的服务器,起码2T的内存,从国外服务器传到国内的服务器,最后转存到大型机
- 分任务利用同事的机子和账号并行下,下载数据用CDS提供的镜像(copernicus-climate.eu)
- 分任务利用同事的机子和账号并行下,下载数据切换成国内的镜像(nuist.love)
先来对比一下3种方法的优缺点:
| 方法编号 | 优点 | 缺点 |
|---|---|---|
| 1 | 国外网速快 | 传到国内机器网速就一般了,1M/s左右,最重要是要花钱,排队时间是否有地区差异,这个暂时不明 |
| 2 | 分而治之,并行下载,原生的镜像支持断点续传,可以自动retry直到最大次数为止 | 排队时间长,要有人写分批下载脚本,统一管理,总得来说废人力,少废钱 |
| 3 | 分而治之,并行下载,国内镜像以为会快一点,但优势胜在小文件 | 缺点和方法2是一样的,网速的提升也适用于小文件,网络不能中断,不支持断点续传,大文件显然就不是很合适 |
鉴于经费,直接排除了第一种,租国外服务器的方法,这种费钱也不见得快多少的方法,肯定是被领导排除的。最后我选择了第二种,因为断点续传,对大文件(现在基本上30G一个文件)来说是很必要的。再说一下我为什么要一次提交这么多 ,我注册的账号在国内,排队的时间很长,而任务提交需要经过 queue-> in progress->download的过程,所以每次提交的一次计算的量大点会划算一点,这里需要说明的是,每次提交的计算量最多12万item,怎么样看自己想要计算的item到底有多少,可以直接在(下载官网页面),选择要下载的数据的参数,如果超过12万个item,页面最下方有显示,如下图所示:

反过来要是没有这个提示,就可以大大方方下载。
测试下来,3d变量一年得分2个,上半年一个,下半年一个,2D变量是10年一个,1991-2021分3个下载。
PS:大家且看看,快速实现的,没有全部函数通用化,用的时候可自行修改!!!
生成好的目录结构和脚本大概是这样:

现在把数据下载放在dataset目录下,对所有down开头和py结尾的下载文件都支持,然后这个下载脚本放在dataset同级目录即可执行,本脚本假如下载的文件不完整的话,会打印文件名。
只要算好可用内存,在dataset目录下就放几个下载任务,晚上下载,白天拷贝,隔两天上传大型机。
常见问题汇总
-
问题1:.cdsapirc这个文件里面的内容设置错误,简单的下载代码都会出现tuple is not callable
解答:其实在添加链接描述已经有详细的cds api使用描述,一步步走下来,唯一有疑惑的点就是.cdsapirc文件里面放什么,放在哪里。这里直接给出答案,登录上述链接,黑框框里就是自己.cdsapirc的内容了,不需要根据自己的key做拼接。还有就是这个文件放哪里,我在windows下直接放在c盘,Users目录下的当前用户目录下,即C:\Users\当前用户名.cdsapirc,如果是linux目录那就打印 $HOME,然后放到这个目录下就可以了。 -
问题2:下载ERA5的数据,其实是想要daily数据的,官网也提供了一个获取这些统计量的页面,也提供了脚本下载的接口代码,奈何,只能以月为单位,如果要下载多年的话,得循环提交多次,这样就导致了任务多,排队时间长,听说提交多请求会被限制,所以得不偿失。
解答:官方给出的原话是:
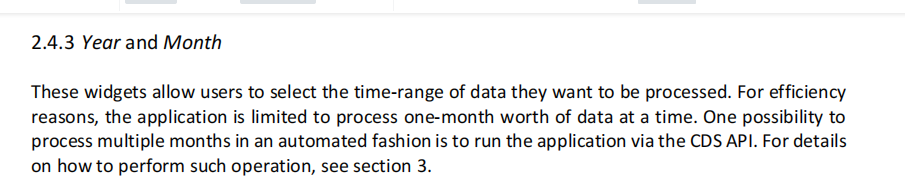
is limited to 和 for efficiency就已经框死了,所以加速无望,只能是下载原始的hourly数据,自己算。下载的数据的时候要把一天24个时刻的数据都选上,而不是选几个所谓的代表性的,去代表这一天。 -
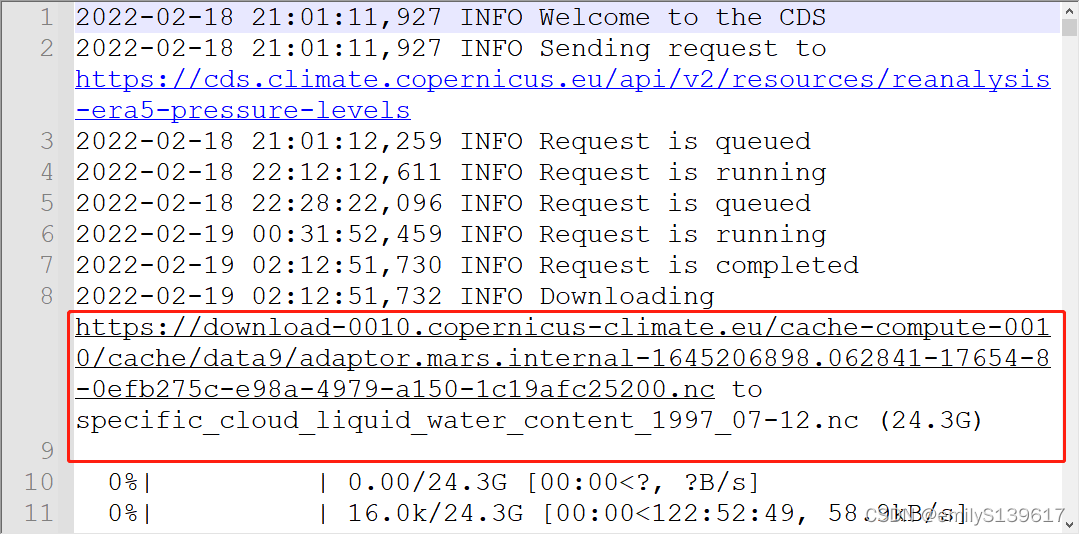
问题3:如果数据中断之后,怎么下载
解答:正常情况下我们会打开一个cmd窗口,提交自己批处理的脚本,在下载过程中,输出的文件名就是没有下载完整的,然后我们可以根据这个文件名,找到同目录运行的log,log名与脚本名相同,在log里面给出了数据链接,可以手动复制到迅雷下载里面补算。
资源分享
-
获取ERA5统计数据的地址
-
total precipitation计算参考地址
-
用python代码计算total precipitation参考地址
-
2米温度计算T2MAX、T2MIN说明参考地址
这篇关于ERA5数据下载的那些事的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





