本文主要是介绍Kettle8.2转换组件之拆分字段,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kettle8.2转换组件之拆分字段
- 一、相关说明
- 二、设计转换
- 三、转换配置
- 四、运行转换
- 五、查看结果
一、相关说明
-
需求说明:
从数据库表读取数据,将name字段内容拆分为first_name和last_name,并把结果数据保存在数据库目标表中。 -
数据源(数据库中表数据):
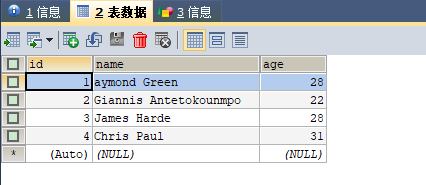
建表语句及插入数据语句,如下:CREATE DATABASE /*!32312 IF NOT EXISTS*/`itcollege` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci */;USE `itcollege`;/*Table structure for table `t_test_user` */DROP TABLE IF EXISTS `t_test_user`;CREATE TABLE `t_test_user` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(50) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓名',`age` tinyint(4) NOT NULL COMMENT '年龄',PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;/*Data for the table `t_test_user` */insert into `t_test_user`(`id`,`name`,`age`) values (1,'aymond Green',28),(2,'Giannis Antetokounmpo',22),(3,'James Harde',28),(4,'Chris Paul',31); -
目标表结构:
DROP TABLE IF EXISTS `t_target_user`;CREATE TABLE `t_target_user` (`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`first_name` VARCHAR(50) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓名',`last_name` VARCHAR(50) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓',`age` TINYINT(4) NOT NULL COMMENT '年龄',PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; -
拆分字段组件说明:
拆分字段是把字段按照分隔符拆分成两个或多个字段。 -
注意: 拆分字段后,原字段就不存在于数据流中!
二、设计转换
- 输入:表输入
- 转换: 拆分字段
- 输出:表输出

三、转换配置
-
Step1:表输入组件配置
- 双击组件,写上步骤名称等



- 双击组件,写上步骤名称等
-
Step2:拆分字段组件配置
- 双击打开,设置步骤名称
- 配置信息,如下

-
Step3:表输出组件配置
-
双击打开,设置步骤名称
-
配置信息,如下



-
保存转换
上述配置好后,点击确定即可!
-
四、运行转换
- 点击运行按钮,成功运行如下:

五、查看结果
-
数据库表(t_target_user)中查看结果
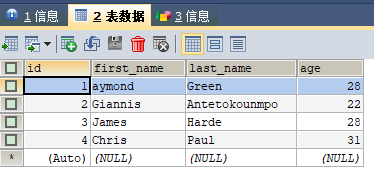
-
Preview data中查看结果
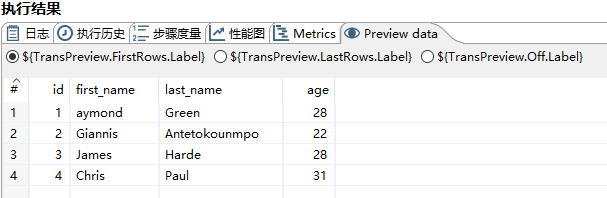
-
执行流程
E:表输入读取数据库表t_test_user中的数据到行集中进行缓存
T:通过Hop读取行集中的数据流,通过拆分字段组件将name字段按照空格进行分词,将结果数据缓存再rowsets中
L:通过Hop读取上一个步骤传递过来的行集数据,并将其写出到数据库表中
这篇关于Kettle8.2转换组件之拆分字段的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





