本文主要是介绍使用花生壳内网穿透,来部署spring boot项目,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我的前端代码放在了Hbuilder X里运行,后端在idea中运行,先依次启动前后端的代码,然后打开花生壳,点击加号来添加自定义映射。
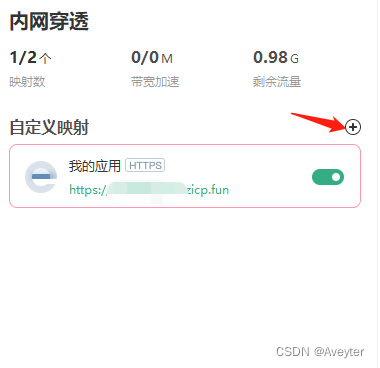
映射类型选择Https,内网主机填写127.0.0.1,也可以是自己主机的ipv4地址,内网端口填写项目的端口号,我的是8080
构建完成后,点击诊断,来判断是否内网穿透成功

我在第一次诊断后出现诊断失败,无法连接内网127.0.0.1:8080。原来自己的项目只能通过localhost:8080进行访问,无法使用127.0.0.1:8080,这就需要修改前端代码了。
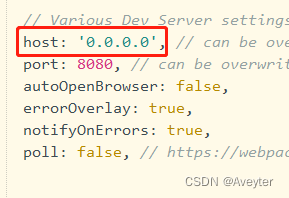
在前端代码→config/index.js文件中将host:'localhost'修改为host:'0.0.0.0'
还有一处前端代码→build/webpack.dev.conf.js添加
useLocalIp:true,
disableHostCheck: true,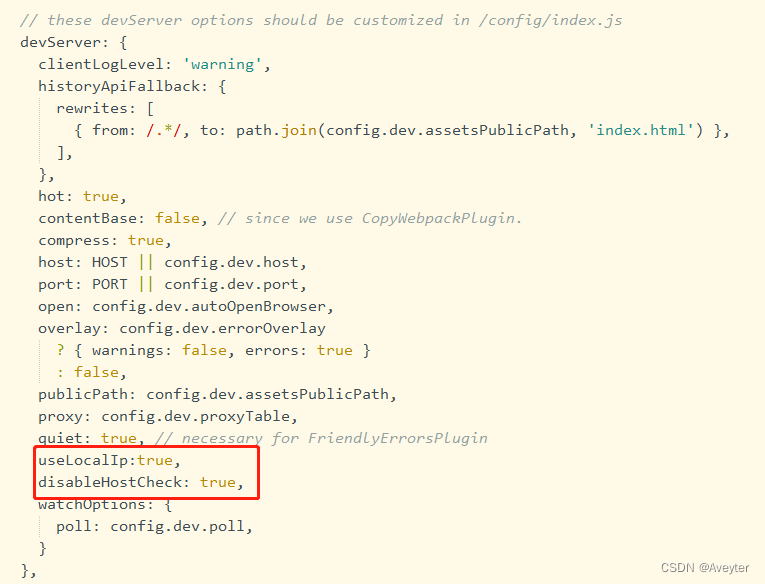
这样我们的前端页面不仅可以通过localhost:8080访问,也可以通过127.0.0.1:8080进行访问。
同时花生壳重新诊断
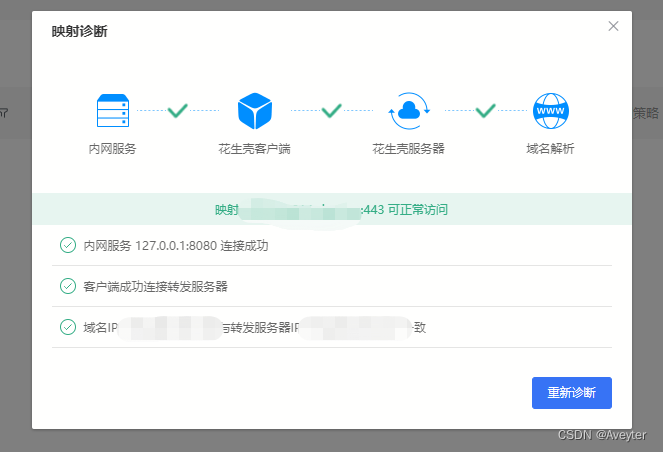
成功了!!!
别急,这时候我们还需要在后端代码中配置跨域操作,否则就算映射成功,我们还是无法通过花生壳给我们的外网域名来访问我们的项目。
我在后端代码 WebMVCConfig.java文件中配置跨域操作,
import org.springframework.web.servlet.config.annotation.EnableWebMvc;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;@EnableWebMvc
@Configuration
public class WebMVCConfig implements WebMvcConfigurer {@Overridepublic void addCorsMappings(CorsRegistry registry) {//跨域配置因为我的后端端口是:8888,前端端口是8080registry.addMapping("/**").allowedOrigins("http://localhost:8080").allowedOrigins("http://127.0.0.1:8080").allowedOrigins("花生壳给你的外网域名");}
}配置完成后,重新启动,这样就可以使用花生壳提供的外网域名访问我们的spring boot项目了,然而我发现,只有我的电脑可以访问前端页面,同时连接到后端接口,别的设备,比如我的手机只能访问前端页面,无法连接到后端接口,也就是说没法进行登录、新增、查看文章内容这些需要数据库配合的操作。
要解决这个问题,我们需要将花生壳给我们的外网域名添加到前端请求后端接口的url上,以登录接口为例,需要在前端代码路径为src/api/login.js中将url:'/login'改为url:'花生壳分配的域名/login'
export function login(account, password) {const data = {account,password}return request({url: '花生壳分配的域名/login',method: 'post',data})
}!!!也可以直接在前端路径config/dev.env.js中,将BASE_API:'"花生壳给点外网域名"'!!!
这种方法部署的项目缺点是离你电脑较远的人访问你的网站,可能打不开网页,我女朋友在广东,她就打不开。但是隔壁市还是没问题的,主要这样部署的成本很低,只需六块钱。
这篇关于使用花生壳内网穿透,来部署spring boot项目的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





