本文主要是介绍利用pip和pipreqs导出当前python环境下所依赖的包总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
很多时候我们会去GitHub上找项目,或者说从其它的地方找到相关的代码,然后有一些已经帮忙做好了requirements文本,我们只需要利用pip就可以进行安装,但还有一部分其实是没有的,所以我们必须要通过其它的方式来得到我们想要的所有依赖。
生成依赖方式
当我们拿到一份较为完整的项目代码时,项目的根目录下是一定会有一个requirements文本文件的,这是作为有利于自己总结当前使用了多少包,并服务于他们节省相应时间的举措,互利共赢用在这里恰逢时机,所以,pip提供了相应的命令:
pip list # 列举出pip当前环境下的包
pip freeze > requirements.txt # 生成当前pip环境下的包文件
这里我们可以用如上的两条命令查看当前所需的包,然后如果没有错误提示基本就保证生成requirements文件成功。

但这里有一个问题,其实项目中用不到这么多的包,这里生成的requirements文件包含了整个环境下的所有包,那么我们可以通过删除包来达到效果。另外还要提及一下虚拟环境的好处了,因为每个虚拟环境都是作为一个项目,如果在端口切换成当前某个虚拟环境,就不会出现包的困扰了,虚拟环境的配置我之前都有总结过,可看如下链接:
linux下搭建虚拟环境
在Windows下搭建虚拟环境
上述只是基于我们是该项目的管理者,然后怎样使得当前项目能更有助于分享,同时也让项目更利于维护做的一些调整,那么当我们拿到一个新的没有requirements文件的怎么办?
第一种方式:边报错边调试
当我们拿到一个新项目,完全不知道缺少什么依赖或者条件,但知道该程序已经是开发完成没有错误的时候,就可以边运行,看着控制台的报错,一般是importerror,一个个装,这样直到不报错为止,就说明该环境安装成功了,但这样的后果花费的精力很大,另外就是即使能运行了还是对整个项目的脉络不清晰,对这些包的作用与版本没有一个完整的认识。
第二种方式:安装pipreqs模块
我们通过pip安装pipreqs包能对项目文件进行扫描,生成相对应的requirements文件,下面是我的步骤:
如果安装好了pipreqs文件,那么切换到当前项目目录下:
pipreqs ./ # 导出相应的包环境
pipreqs ./ --encoding=utf8 # 以utf8的形式导出包环境
pipreqs ./ --force # 强制导出包环境,包括如果有同名requirements,可以进行重写
上述一般运行第一条命令就行,但我当时是在Windows的cmd下运行的,这里问题就出现了,它提示我有编码问题:
Traceback (most recent call last):File "f:\anaconda\lib\runpy.py", line 193, in _run_module_as_main"__main__", mod_spec)File "f:\anaconda\lib\runpy.py", line 85, in _run_codeexec(code, run_globals)File "F:\anaconda\Scripts\pipreqs.exe\__main__.py", line 9, in <module>File "f:\anaconda\lib\site-packages\pipreqs\pipreqs.py", line 396, in maininit(args)File "f:\anaconda\lib\site-packages\pipreqs\pipreqs.py", line 341, in initextra_ignore_dirs=extra_ignore_dirs)File "f:\anaconda\lib\site-packages\pipreqs\pipreqs.py", line 75, in get_all_importscontents = f.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 621: illegal multibyte sequence
然后我就运行第二句,指定编码为utf8,但还是报一样的错误:
Traceback (most recent call last):File "f:\anaconda\lib\runpy.py", line 193, in _run_module_as_main"__main__", mod_spec)File "f:\anaconda\lib\runpy.py", line 85, in _run_codeexec(code, run_globals)File "F:\anaconda\Scripts\pipreqs.exe\__main__.py", line 9, in <module>File "f:\anaconda\lib\site-packages\pipreqs\pipreqs.py", line 396, in maininit(args)File "f:\anaconda\lib\site-packages\pipreqs\pipreqs.py", line 341, in initextra_ignore_dirs=extra_ignore_dirs)File "f:\anaconda\lib\site-packages\pipreqs\pipreqs.py", line 75, in get_all_importscontents = f.read()File "f:\anaconda\lib\codecs.py", line 321, in decode(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb2 in position 33: invalid start byte
那么这种情况就别再试了,应该是项目本身有问题,而不是pipreqs模块有bug,所以我就直接拷贝进了Linux环境中,同样输入上述命令,然后发现是其中一个文件有问题,于是我删除了该文件,再次运行生成了相应的包:
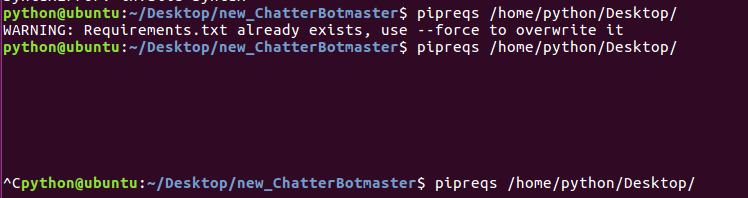
当然这里我是已经生成好了再运行了一遍,然后它说要用–force强制执行,然后我删除了requirements文件继续运行,但我的项目有点大,可能它搜索相应的模块需要时间,然后只要最后提示如下信息,那么就是成功了:
INFO: Successfully saved requirements file in /home/python/Desktop/requirements.txt
然后可以打开相应的存储位置,我们就会发现多了一个requirements文件。
这篇关于利用pip和pipreqs导出当前python环境下所依赖的包总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






