本文主要是介绍HiveSQL——条件判断语句嵌套windows子句的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注:参考文章:
SQL条件判断语句嵌套window子句的应用【易错点】--HiveSql面试题25_sql剁成嵌套判断-CSDN博客文章浏览阅读920次,点赞4次,收藏4次。0 需求分析需求:表如下user_idgood_namegoods_typerk1hadoop1011hive1221sqoop2631hbase1041spark1351flink2661kafka1471oozie108以上数据._sql剁成嵌套判断https://blog.csdn.net/godlovedaniel/article/details/118220935
0 需求
基于下表的表结构及数据,求出每个用户每次搜索非广告类型的商品位置排序。假设字段goods_type为26代表该商品类型是广告。
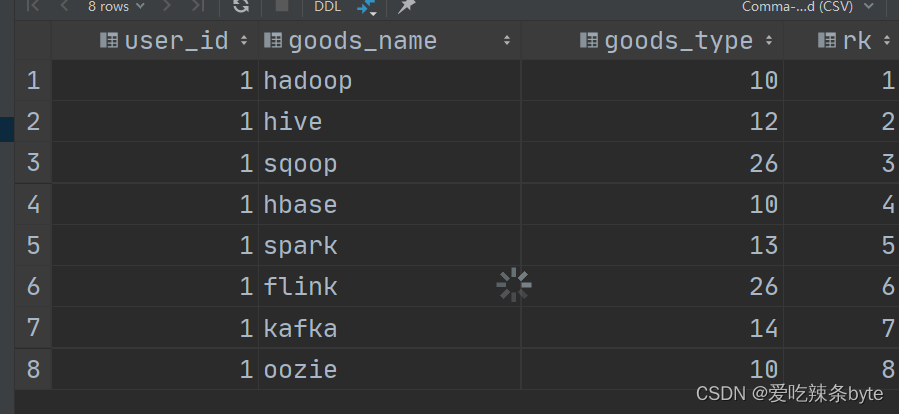
想达到的效果:
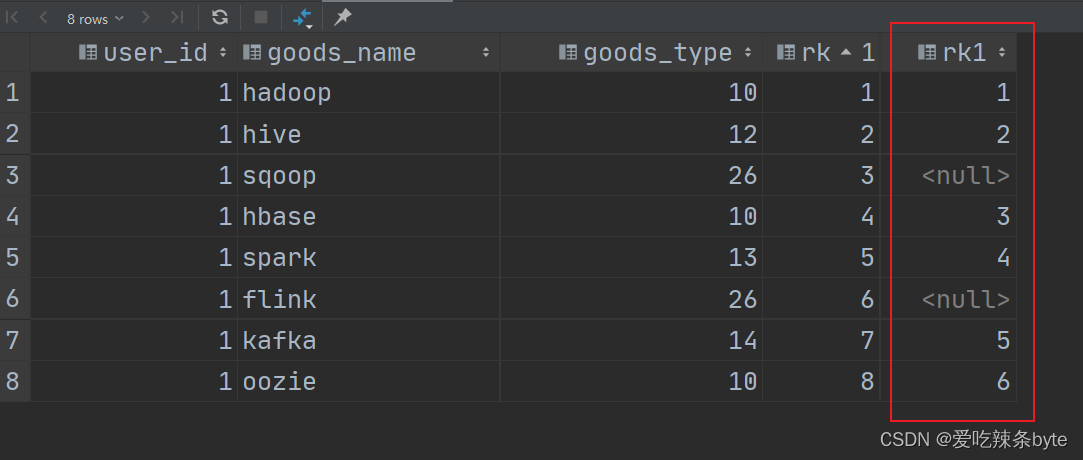
1 数据加载
--建表
create table window_goods_test (
user_id int, --用户id
goods_name string, --商品名称
goods_type int, --标识每个商品的类型,比如广告,非广告
rk int --这次搜索下商品的位置,比如第一个广告商品就是1,后面的依次2,3,4...
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';-- 加载数据
load data local inpath '/opt/module/hive_data/window_goods_test.txt' into table window_goods_test ;vim window_goods_test.txt
1 hadoop 10 1
1 hive 12 2
1 sqoop 26 3
1 hbase 10 4
1 spark 13 5
1 flink 26 6
1 kafka 14 7
1 oozie 10 8
2 数据分析
代码分析:最开始的思路:先过滤掉非广告的商品,再重新排序
select user_id,goods_name,goods_type,rk,if(goods_type != 26,row_number() over (partition by user_id order by rk),null) as rk1
from window_goods_test;
输出结果如下:显然没有达到预期的结果。
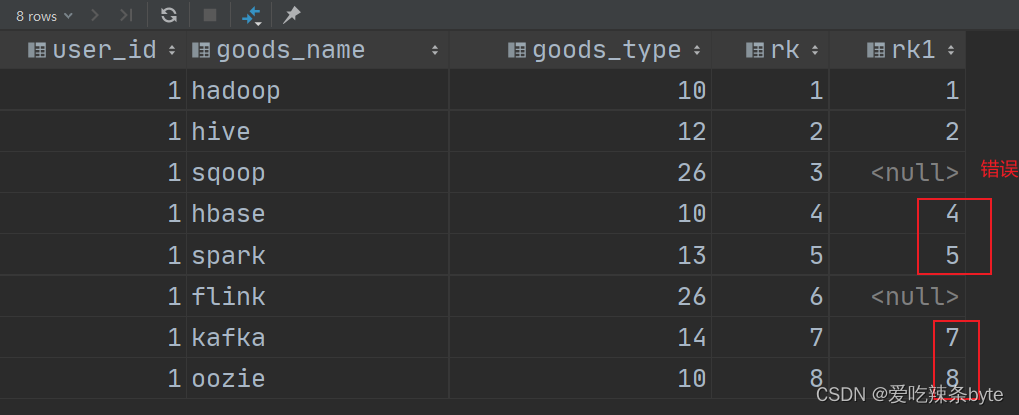
出错原因在于对窗口函数的执行原理及顺序不了解,可以通过执行计划来判断SQL执行顺序。
explain
select user_id,goods_name,goods_type,rk,if(goods_type != 26,row_number() over (partition by user_id order by rk),null) as rk1
from window_goods_test;具体执行步骤如下:
(1)扫描表
(2)按照user_id分组
(3)按照user_id和rk进行升序排序
(4)执行row_number()函数进行分析
(5)使用if进行判断
由执行计划可以得出 if函数是在row_number()函数之后执行的
上述sql可以拆解为三部分进行执行:
step1:扫描表,获取select的结果集
select user_id,goods_name,goods_type,rk
from window_goods_test;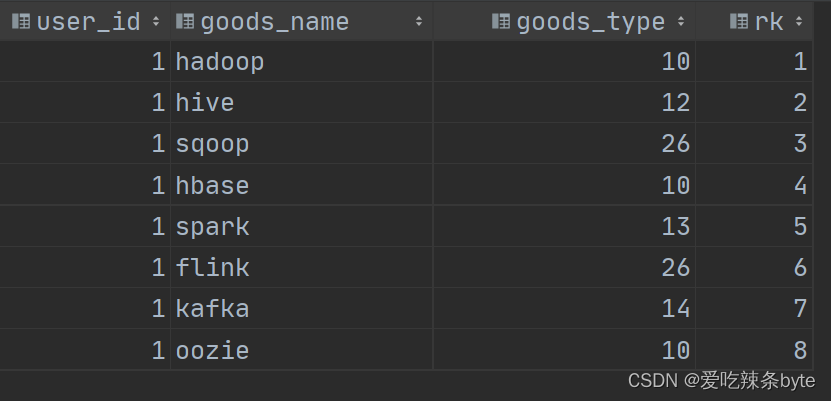
step2:执行窗口函数
select user_id,goods_name,goods_type,rk,row_number() over (partition by user_id order by rk) as rk1
from window_goods_test;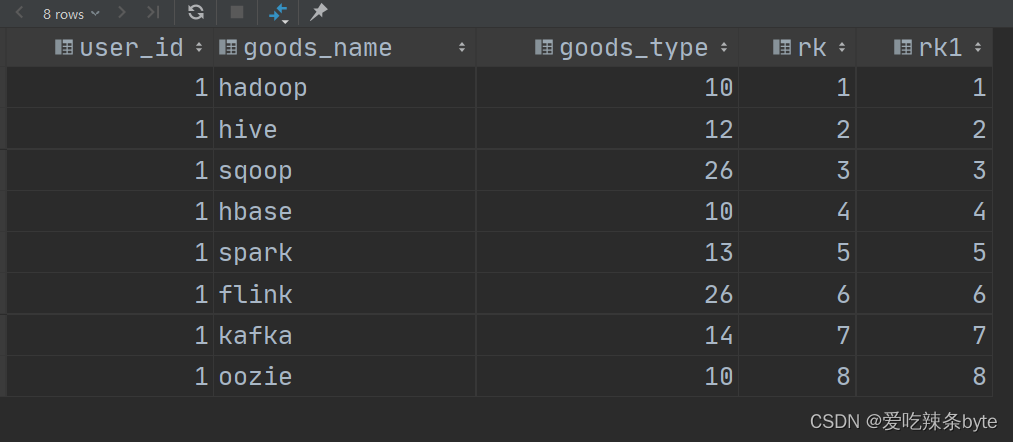
step3:基于step2结果集执行 if判断
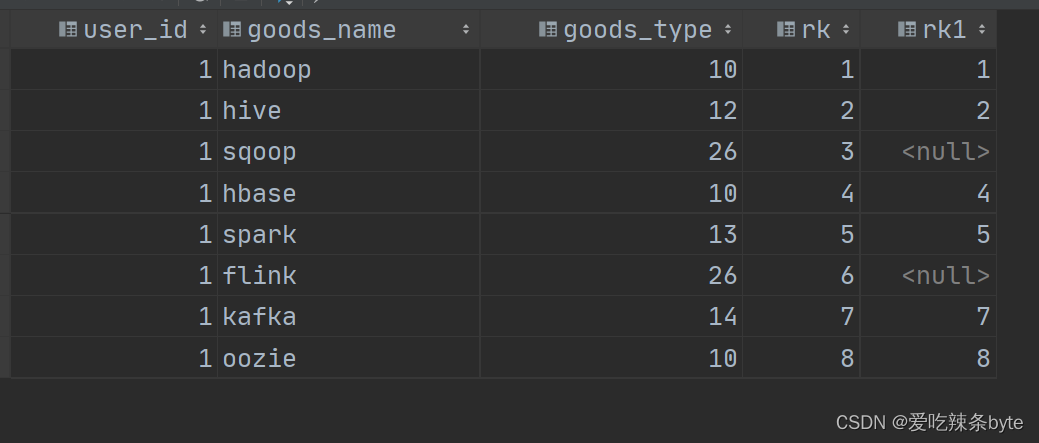
因此正确代码如下:
方式一:union all 拆解成两段逻辑
-- 第一段逻辑:先限制goods_type != 26,再排序
selectuser_id,goods_name,goods_type,rk,row_number() over (partition by user_id order by rk) as rk1
from window_goods_test
where goods_type != 26
union all
-- 第二段逻辑:将goods_type = 26的记录的rk1 直接记为null
selectuser_id,goods_name,goods_type,rk,null as rk1
from window_goods_test
where goods_type = 26
order by rk;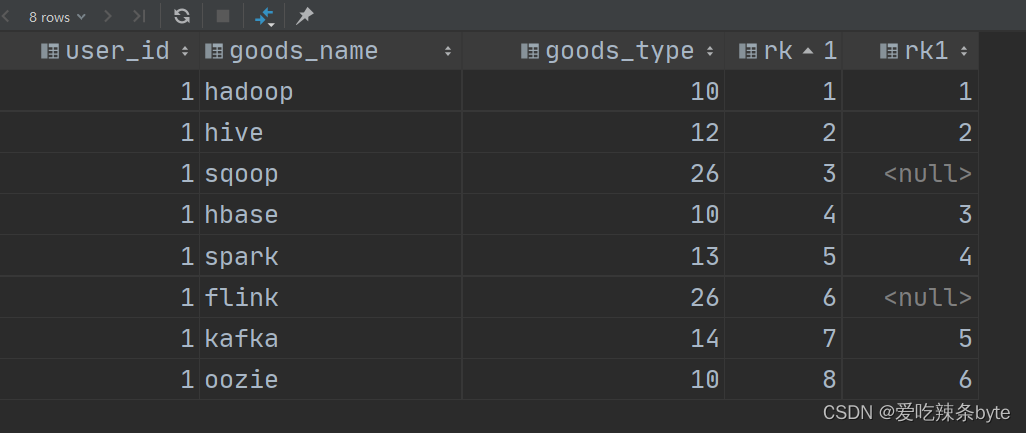
上述代码的缺点:window_goods_test表需要扫描两次,显然不是最优解。
优化的解题思路为:
方式二:
step1: partition by分组中先进行 if 语句过滤,如果goods_type!=26则取对应的user_id 进行分组,如果goods_type=26 则置为随机数rand(), 再按照随机数分组
ps: 这里采用随机数是考虑到万一 goods_type=26的记录数很多,通过rand()随机分组可以将key值打散,避免数据倾斜
selectuser_id,goods_name,goods_type,rk,row_number() over (partition byif(goods_type != 26, user_id, rand())order by rk) rk1
from window_goods_test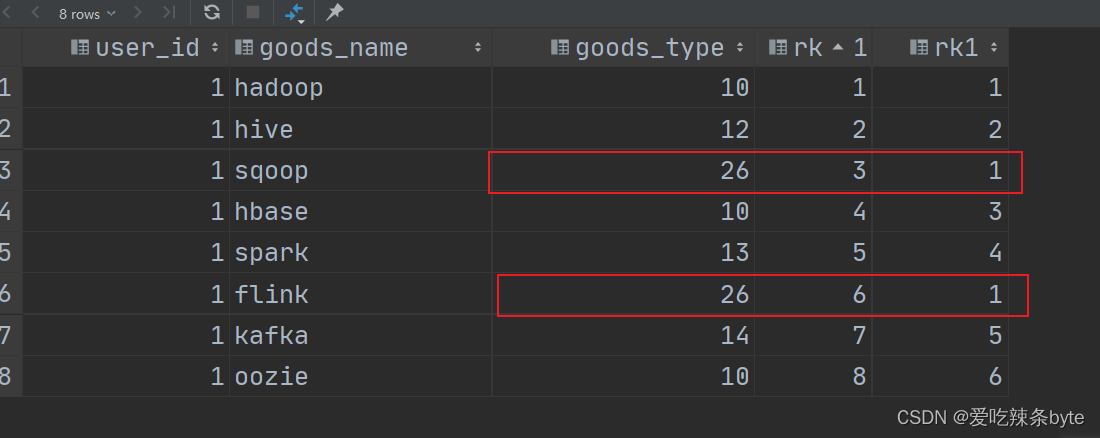
step2:在step1的外侧利用 if函数进一步判断
selectuser_id,goods_name,goods_type,rk,if(goods_type != 26,row_number() over (partition by if(goods_type != 26, user_id, rand()) order by rk),null) rk1
from window_goods_test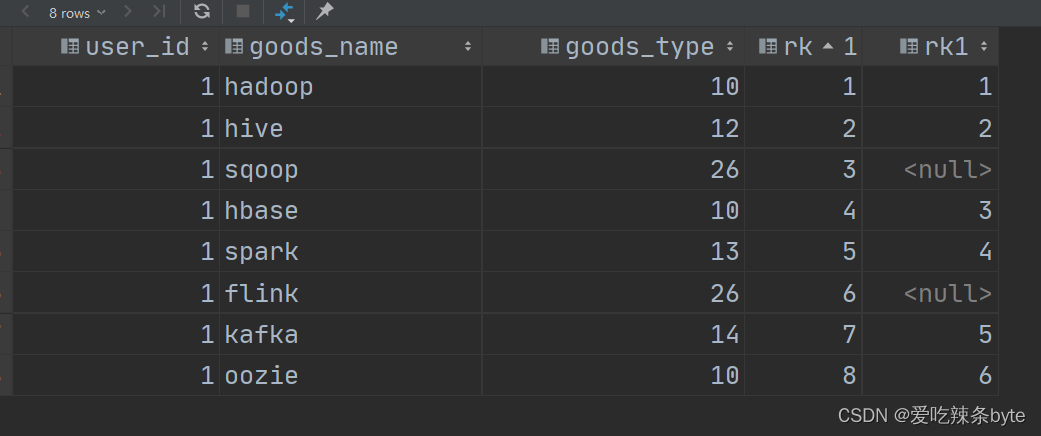
3 小结
通过本案例得出的结论:
- case when或if语句中嵌套窗口函数时,条件判断语句的执行顺序是在窗口函数之后的;
- 窗口函数partition by 子句中是允许嵌套条件判断语句的;
这篇关于HiveSQL——条件判断语句嵌套windows子句的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






