本文主要是介绍Pandas数据清洗手册:从缺失值到多层索引,掌握完整数据处理技巧【第70篇—python:Pandas数据清洗】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Pandas数据清洗手册:从缺失值到多层索引,掌握完整数据处理技巧
- 1. 判断缺失值
- 2. 删除空值
- 3. 填补空值
- 4. 替换元素
- 5. 分割元素
- 6. 字符串操作
- 7. 数据类型转换
- 8. 去重
- 9. 自定义函数
- 10. 处理日期数据
- 11. 缺失值插值
- 12. 透视表
- 13. 数据合并
- 14. 数据采样
- 15. 处理异常值
- 16. 分组统计
- 17. 自定义缺失值处理函数
- 18. 处理多层索引
- 19. 数据滑动窗口
- 20. 数据重塑
- 总结:
Pandas数据清洗手册:从缺失值到多层索引,掌握完整数据处理技巧
在数据分析和机器学习的过程中,数据清洗是一个不可忽视的重要步骤。Pandas是Python中用于数据处理和分析的强大库,提供了丰富的数据清洗函数。本文将介绍一些常用的Pandas数据清洗函数,包括判断缺失值、删除空值、填补空值、替换元素和分割元素等操作。

1. 判断缺失值
在数据中,经常会遇到缺失值的情况。Pandas提供了一些函数来判断数据中是否存在缺失值。
import pandas as pd# 创建一个包含缺失值的DataFrame
data = {'A': [1, 2, None, 4], 'B': [5, None, 7, 8]}
df = pd.DataFrame(data)# 判断每个元素是否是缺失值
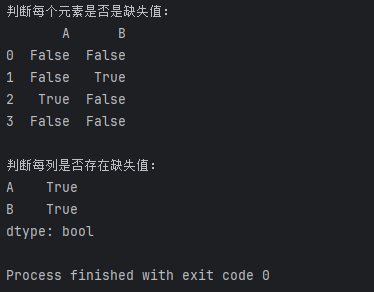
print("判断每个元素是否是缺失值:")
print(df.isnull())# 判断每列是否存在缺失值
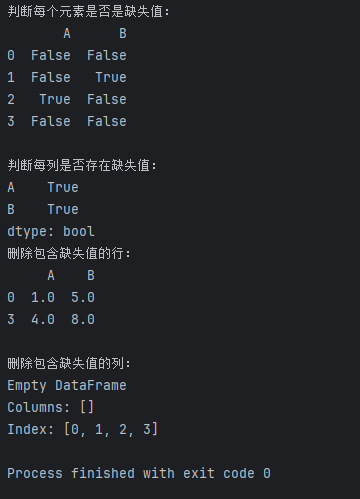
print("\n判断每列是否存在缺失值:")
print(df.isnull().any())
2. 删除空值
处理缺失值的一种方法是删除包含缺失值的行或列。
# 删除包含缺失值的行
df_dropped_rows = df.dropna()# 删除包含缺失值的列
df_dropped_columns = df.dropna(axis=1)print("删除包含缺失值的行:")
print(df_dropped_rows)print("\n删除包含缺失值的列:")
print(df_dropped_columns)
3. 填补空值
除了删除,还可以使用不同的填充方法来处理缺失值。
# 用指定值填充缺失值
df_filled_value = df.fillna(value=0)# 使用前一个非缺失值填充缺失值(向前填充)
df_forward_filled = df.ffill()print("用指定值填充缺失值:")
print(df_filled_value)print("\n向前填充缺失值:")
print(df_forward_filled)
4. 替换元素
替换元素是另一种数据清洗的常见操作,可以用一个值替换另一个值。
# 替换指定值
df_replace = df.replace({None: -1, 7: 77})print("替换指定值:")
print(df_replace)
5. 分割元素
有时,我们需要根据某个条件将元素分割成不同的组。
# 根据条件分割元素
df_split = df[df['A'] < 3]print("根据条件分割元素:")
print(df_split)
以上只是Pandas数据清洗的一小部分功能,Pandas库提供了丰富的功能来满足各种数据清洗的需求。这些函数是数据分析和预处理中的利器,能够让数据变得更加整洁和易于分析。
6. 字符串操作
在数据清洗中,处理字符串数据也是一个常见的任务。Pandas提供了丰富的字符串操作函数,可以方便地对字符串进行处理。
# 创建一个包含字符串的DataFrame
data_str = {'Text': ['apple', 'banana', 'orange', 'grape']}
df_str = pd.DataFrame(data_str)# 判断是否包含特定字符串
contains_apple = df_str['Text'].str.contains('apple')# 提取字符串中的数字
df_str['Number'] = df_str['Text'].str.extract('(\d+)')print("判断是否包含特定字符串:")
print(contains_apple)print("\n提取字符串中的数字:")
print(df_str)
7. 数据类型转换
有时候,数据的类型可能不符合我们的需求,需要进行类型转换。
# 转换列的数据类型
df['A'] = df['A'].astype(float)print("转换列的数据类型:")
print(df.dtypes)
8. 去重
去重是清洗数据时的一项重要任务,可以使用drop_duplicates方法实现。
# 去重
df_duplicates_removed = df.drop_duplicates()print("去重后的DataFrame:")
print(df_duplicates_removed)
9. 自定义函数
在数据清洗过程中,有时需要根据特定的需求编写自定义的清洗函数。
# 自定义清洗函数:将所有元素加倍
def double_elements(x):return x * 2df_custom_clean = df.applymap(double_elements)print("自定义清洗函数后的DataFrame:")
print(df_custom_clean)
通过这些Pandas数据清洗函数,你可以更加灵活地处理各种数据清洗任务。在实际应用中,根据数据的不同特点,选择合适的清洗方法非常关键。
10. 处理日期数据
在实际数据中,经常会遇到日期数据,Pandas提供了强大的日期处理功能。
# 创建包含日期的DataFrame
data_date = {'Date': ['2022-01-01', '2022-02-01', '2022-03-01']}
df_date = pd.DataFrame(data_date)# 将字符串转换为日期类型
df_date['Date'] = pd.to_datetime(df_date['Date'])# 提取日期中的年、月、日
df_date['Year'] = df_date['Date'].dt.year
df_date['Month'] = df_date['Date'].dt.month
df_date['Day'] = df_date['Date'].dt.dayprint("处理日期数据:")
print(df_date)
11. 缺失值插值
在某些情况下,我们希望通过已知数据的信息来推断缺失值,可以使用插值方法。
# 使用线性插值填充缺失值
df_interpolated = df.interpolate()print("使用线性插值填充缺失值:")
print(df_interpolated)
12. 透视表
透视表是一种数据汇总的方式,可以通过透视表更方便地进行数据分析。
# 创建一个包含透视表数据的DataFrame
data_pivot = {'Category': ['A', 'B', 'A', 'B'],'Value': [10, 20, 30, 40]}
df_pivot = pd.DataFrame(data_pivot)# 利用透视表进行数据汇总
pivot_table = pd.pivot_table(df_pivot, values='Value', index='Category', aggfunc='sum')print("透视表数据汇总:")
print(pivot_table)
13. 数据合并
在实际分析中,数据可能分布在多个表中,需要进行合并。
# 创建两个DataFrame用于合并
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Charlie']})
df2 = pd.DataFrame({'ID': [1, 2, 4], 'Age': [25, 30, 35]})# 根据ID列合并两个DataFrame
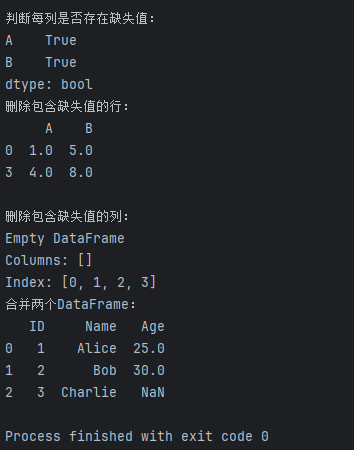
merged_df = pd.merge(df1, df2, on='ID', how='left')print("合并两个DataFrame:")
print(merged_df)
通过这些进阶的Pandas数据清洗技巧,你可以更好地处理各种复杂的数据情况。
14. 数据采样
在处理大规模数据集时,有时需要对数据进行采样,以便更快速地进行分析和测试。
# 针对大数据集进行随机采样
df_sampled = df.sample(frac=0.5, random_state=42)print("随机采样后的DataFrame:")
print(df_sampled)
15. 处理异常值
异常值可能对数据分析和建模产生不良影响,因此需要检测和处理异常值。
# 创建包含异常值的DataFrame
data_outliers = {'Value': [100, 200, 300, 1000]}
df_outliers = pd.DataFrame(data_outliers)# 定义异常值上下限
lower_limit = df_outliers['Value'].mean() - 2 * df_outliers['Value'].std()
upper_limit = df_outliers['Value'].mean() + 2 * df_outliers['Value'].std()# 根据异常值上下限进行过滤
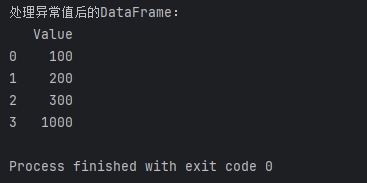
df_no_outliers = df_outliers[(df_outliers['Value'] > lower_limit) & (df_outliers['Value'] < upper_limit)]print("处理异常值后的DataFrame:")
print(df_no_outliers)
16. 分组统计
分组统计是数据清洗中的常见操作,可以对数据进行分组后进行各类统计分析。
# 创建包含分组数据的DataFrame
data_grouped = {'Category': ['A', 'B', 'A', 'B'],'Value': [10, 20, 30, 40]}
df_grouped = pd.DataFrame(data_grouped)# 按Category分组并计算平均值
grouped_mean = df_grouped.groupby('Category')['Value'].mean()print("分组统计的平均值:")
print(grouped_mean)
17. 自定义缺失值处理函数
有时,数据集中的缺失值需要根据特定规则进行处理,可以编写自定义函数进行处理。
# 自定义缺失值处理函数:用均值填充缺失值
def fill_na_with_mean(column):mean_value = column.mean()return column.fillna(mean_value)# 应用自定义函数进行缺失值填充
df_custom_fillna = df.apply(fill_na_with_mean)print("自定义缺失值处理后的DataFrame:")
print(df_custom_fillna)
通过这些进一步的Pandas技巧,你可以更全面地处理数据清洗任务,应对更多复杂的数据情况。这些技能将帮助你在数据分析和建模过程中更灵活地操作数据,从而取得更好的分析结果。希望这些代码示例和解析对你的数据清洗工作有所帮助。
18. 处理多层索引
有时候,数据集可能包含多层索引,这时我们需要使用多层索引的相关函数进行操作。
# 创建包含多层索引的DataFrame
data_multiindex = {'Value': [10, 20, 30, 40],'Category': ['A', 'B', 'A', 'B']}
df_multiindex = pd.DataFrame(data_multiindex)
df_multiindex.set_index(['Category', df_multiindex.index], inplace=True)print("含有多层索引的DataFrame:")
print(df_multiindex)# 根据多层索引进行筛选
result = df_multiindex.loc['A']print("\n根据多层索引筛选后的DataFrame:")
print(result)
19. 数据滑动窗口
在时间序列数据或其他有序数据中,使用滑动窗口进行统计分析是一种常见的处理方法。
# 创建时间序列数据
date_rng = pd.date_range(start='2022-01-01', end='2022-01-10', freq='D')
df_time_series = pd.DataFrame(date_rng, columns=['date'])
df_time_series['value'] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# 使用滑动窗口计算均值
df_time_series['rolling_mean'] = df_time_series['value'].rolling(window=3).mean()print("使用滑动窗口计算均值:")
print(df_time_series)
20. 数据重塑
数据重塑是将数据从一种形式变换为另一种形式的过程,Pandas提供了多个函数用于数据重塑。
# 创建包含堆叠数据的DataFrame
data_stacked = {'A': [1, 2, 3],'B': [4, 5, 6]}
df_stacked = pd.DataFrame(data_stacked)# 将数据从宽格式变为长格式
df_long = pd.melt(df_stacked, var_name='Category', value_name='Value')print("将数据从宽格式变为长格式:")
print(df_long)
通过这些高级的Pandas技巧,你可以更加灵活地处理复杂数据结构和特殊数据形式。这些技能对于处理实际工作中的各种数据情况非常有帮助。希望这些代码示例和解析能够增强你在数据清洗和处理中的技能,提高对数据的深入理解。
总结:
数据清洗在数据分析和机器学习中是一个至关重要的环节,而Pandas作为Python中优秀的数据处理库,提供了丰富的功能来帮助进行数据清洗。在本文中,我们介绍了一系列常用的Pandas数据清洗函数,涵盖了多个方面的操作,包括缺失值处理、删除空值、填充空值、替换元素、分割元素等。
以下是本文涉及的主要内容和技术要点:
-
判断缺失值: 使用
isnull()函数可以判断数据中的缺失值,any()函数可以判断每列是否存在缺失值。 -
删除空值:
dropna()函数可以删除包含缺失值的行或列。 -
填补空值: 使用
fillna()函数可以用指定值或其他方法填充缺失值,而ffill()函数则可以用前一个非缺失值进行填充。 -
替换元素: 使用
replace()函数可以替换DataFrame中的特定值。 -
分割元素: 通过条件进行数据的分割,例如使用布尔索引。
-
字符串操作: 利用
str属性可以对字符串列进行各种操作,如判断是否包含特定字符串、提取数字等。 -
数据类型转换: 使用
astype()函数可以对列进行数据类型转换。 -
去重: 使用
drop_duplicates()函数可以去除DataFrame中的重复行。 -
自定义函数: 可以编写自定义函数应用于DataFrame中,适应特定的清洗需求。
-
处理日期数据: 利用
to_datetime()函数和dt属性,可以方便地处理日期数据。 -
缺失值插值: 使用
interpolate()函数进行缺失值插值。 -
透视表: 利用
pivot_table()函数可以进行透视表的操作,方便数据汇总。 -
数据合并: 使用
merge()函数可以合并两个DataFrame。 -
数据采样: 使用
sample()函数可以对大数据集进行随机采样。 -
处理异常值: 使用统计方法或特定规则进行异常值的检测和处理。
-
分组统计: 利用
groupby()函数可以对数据进行分组并进行统计分析。 -
自定义缺失值处理函数: 根据具体需求编写自定义函数处理缺失值。
-
处理多层索引: 使用多层索引相关函数进行多层索引数据的操作。
-
数据滑动窗口: 利用
rolling()函数进行滑动窗口的统计分析。 -
数据重塑: 使用
melt()等函数进行数据的重塑,从一种形式变为另一种形式。
这些技术和函数覆盖了Pandas库中丰富的功能,为数据科学家、分析师和工程师提供了强大的工具来清洗和准备数据,为后续的建模和分析工作打下坚实基础。熟练掌握这些技术,将帮助你更高效地处理各类数据清洗任务。
这篇关于Pandas数据清洗手册:从缺失值到多层索引,掌握完整数据处理技巧【第70篇—python:Pandas数据清洗】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





