本文主要是介绍excel统计分析——成组数据秩和检验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考资料:生物统计学
https://real-statistics.com/statistics-tables/mann-whitney-table/
非配对资料的秩和检验是对计量资料或等级资料的两个样本所属总体分布进行检验。这种检验比配对资料的秩和检验应用更为普遍。非配对资料秩和检验的方法包括Wilcoxon秩和检验和Mann-Whitney U检验。两者检验过程相似,结果等价,只是使用的统计量有所不同,因此合称Wilcoxon-Mann-Whitney检验,目前统计软件以Mann-Whitney U检验为主。
Wilcoxon-Mann-Whitney秩和检验的基本思想如下:设有两个连续分布的总体,其累计概率函数分别为Fx和Fy。建立的假设:H0为。如果H0成立,两个样本中的任何观察值取秩1~N(总样本容量)的概率相等。因此,每个观察值所对应的秩的理论值(平均秩)都为(N+1)/2,样本中n1个观察值对应的秩和T的理论值为
;T统计量的抽样分布以n1(N+1)/2为中心,呈对称性分布;当n1、n2都较大时,T统计量复存均为n1(N+1)/2,方差为n1n2(N+1)/12的正态分布。如果H0不成立,T统计量偏离n1(N=1)/2,呈偏态分布。
如果成组计量资料不能满足参数检验(t检验)的条件,可应用Wilcoxon-Mann-Whitney检验进行分析,该检验是可替代t检验的非参数检验,统计检验效能强大,有时甚至高于t检验。基本步骤如下:
(1)提出假设。
零假设H0:两样本所在总体的中位数相等。
备择假设HA:两样本所在总体的中位数不想等。
(2)编秩次。
设两样本的样本容量分别为n1和n2;先将两样本数据混合,从小到大编秩次,最小值为1,最大值的秩次为“n1+n2”;遇到相同数值,取平均秩次。
(3)求秩和及统计量U。
分别统计两个样本各自的秩和T1和T2;按下式计算样本U值:
并以其中较小的值作为U检验的统计量,即
(4)统计推断。
如果n≤20,可根据n1、n2查Mann-Whitney U检验临界值表,得临界值Uα。U与临界值Uα比较,如果U>Uα,则P>α,表明两组数据在α水平上差异不显著;反之则差异显著。当n1>20或n2>20时,可用正态近似法进行u检验。统计量u的计算公式为:
其中:T为T1和T2中的较小者;n1、n2分别为两样本的样本容量,nx为T对应组的样本容量。如果多个观察值同秩,则需要对u值进行矫正:
其中,j表示某个同秩的个数。计算u值后,可根据α=0.05(或α=0.01)时的临界值进行统计推断。
excel案例操作如下:
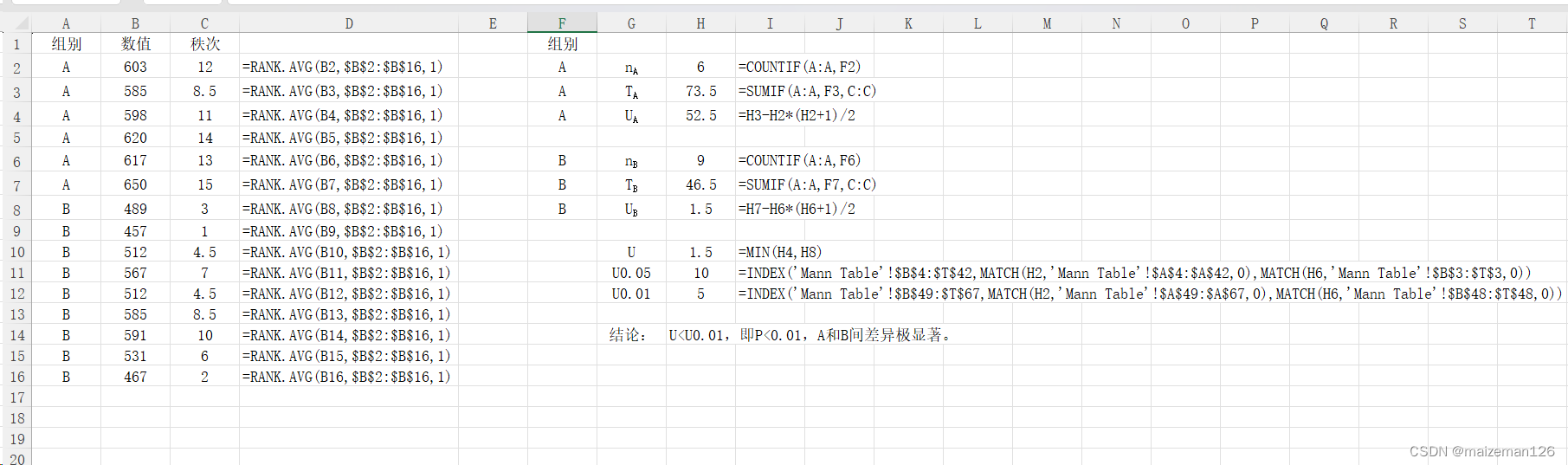
这篇关于excel统计分析——成组数据秩和检验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





