本文主要是介绍conda 环境中部署gunicorn+flask项目,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系统环境中安装的是Python3.5,项目中需要的Python为3.6及以上的环境,所以用conda虚拟环境进行隔离。
conda


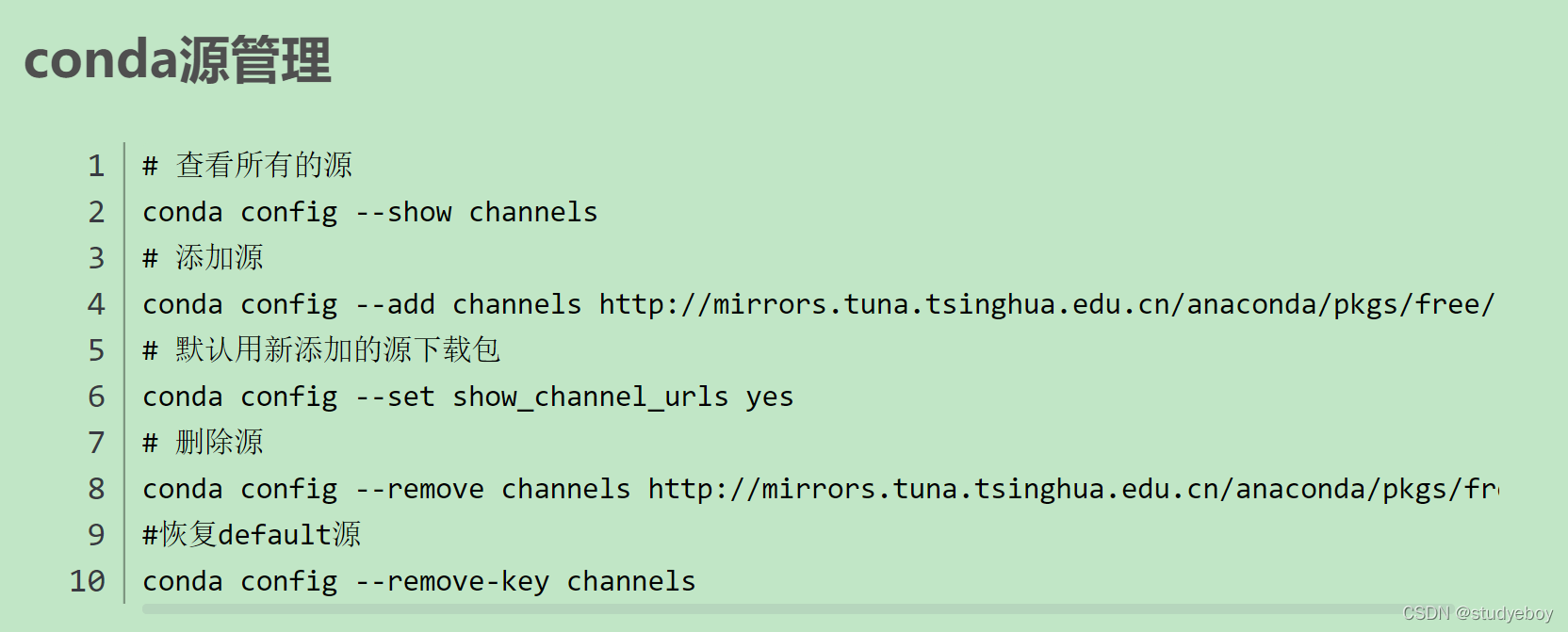

项目搭建
进入虚拟环境,安装所需要的包。
sh Miniconda3-py37_4.11.0-Linux-x86_64.sh
source ~/.bashrc
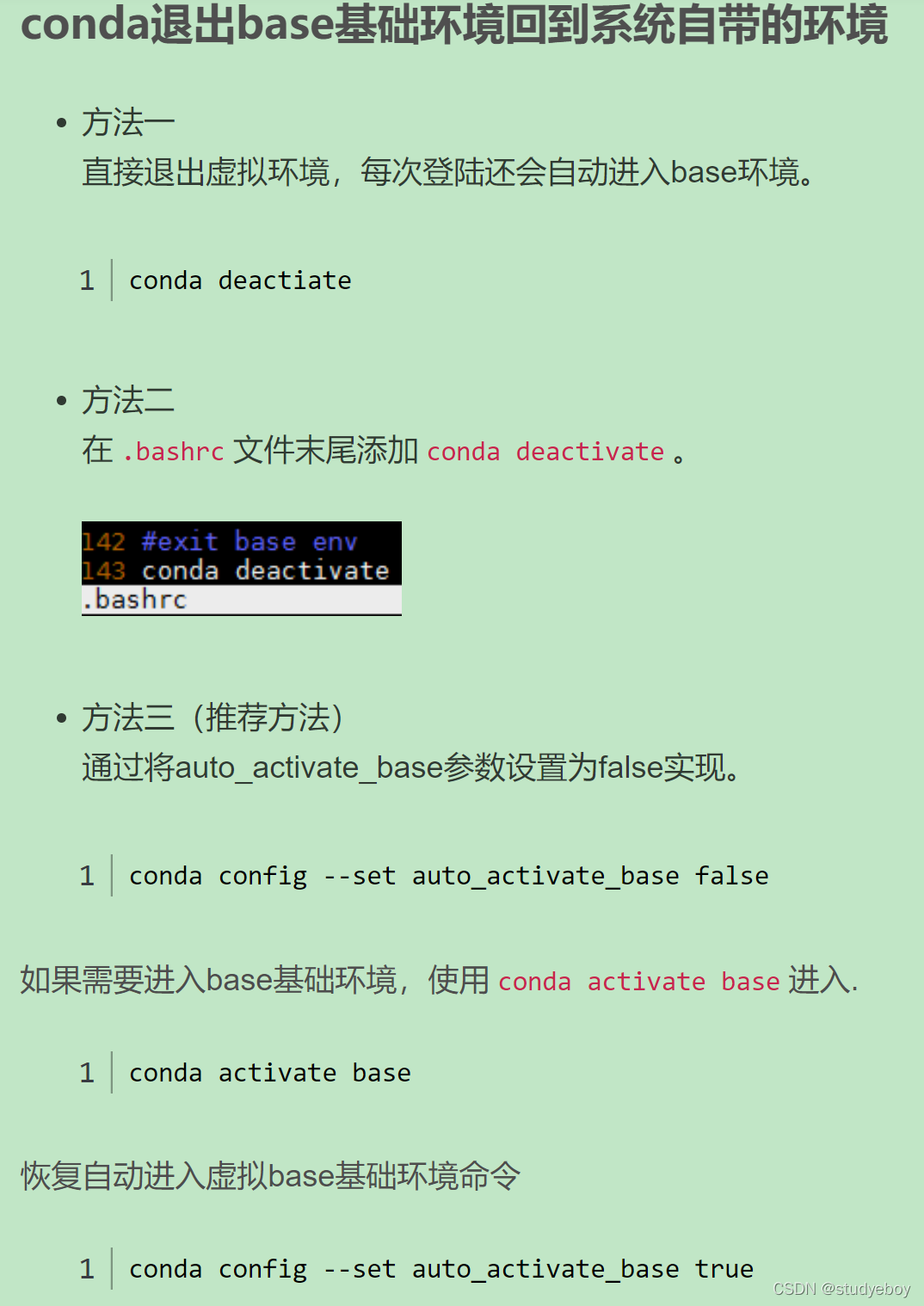
conda config --set auto_activate_base false
#创建虚拟环境
conda create -n pytorch python=3.6
#进入虚拟环境
conda activate pytorch
#从清华源下载安装pytorch
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda install -n pytorch pytorch torchvision cudatoolkit=10.0
#工程需要的库用conda安装会失败,所以用的pip进行安装
#安装insightface,可以用pip安装或者python3.6 -m pip install 来安装
pip install insightface
#安装pymatting
pip install pymatting
#安装onnxruntime,onnxruntime和cuda需要版本对应,cuda10.0对应onnxruntime1.0或1.1
pip install onnxruntime-gpu==1.0
#项目搭建依赖的库用conda就可以
#安装gunicorn
conda install gunicorn
#安装flask
conda install flask
conda install gevent
#gunicorn启动项目
gunicorn -c config.py flask_matting:app
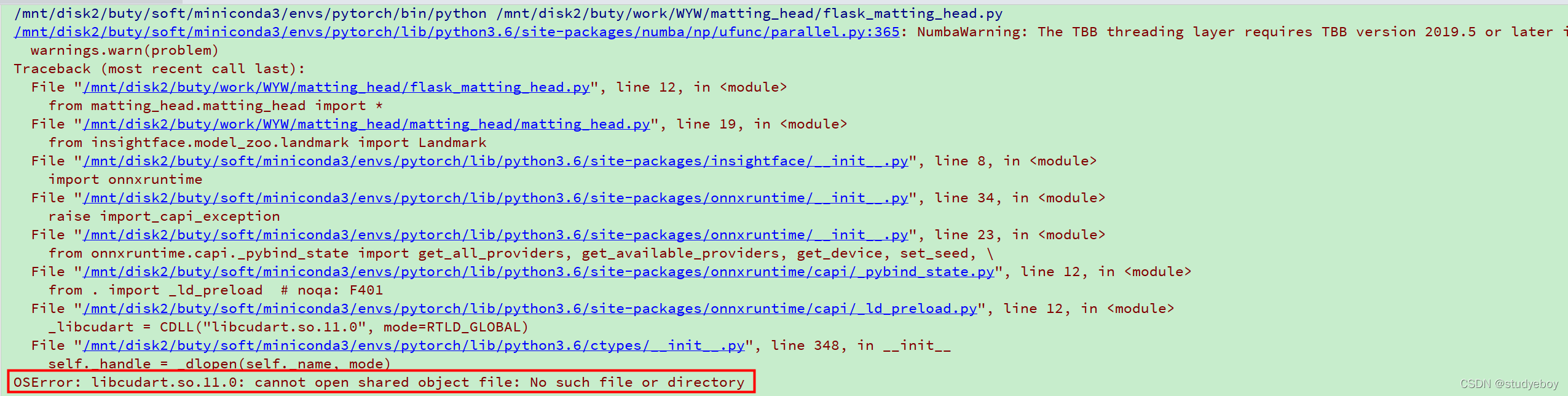
问题
onnxruntime和cuda版本不匹配问题
-
问题
onnxruntime与cuda版本不匹配,可能出现的问题。
-
解决方法
查看cuda版本nvcc -V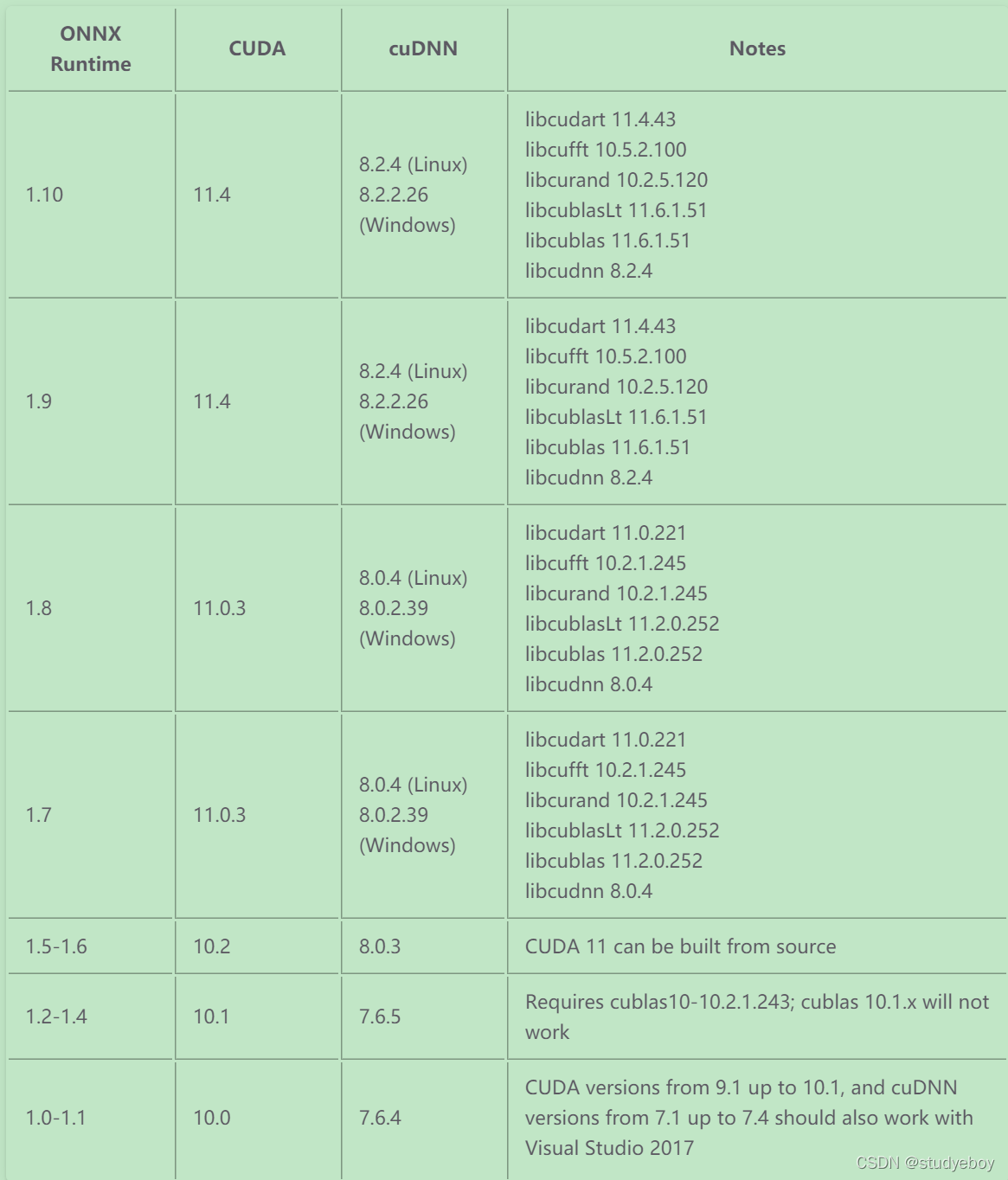
查看conda虚拟环境下pip的安装路径可以用pip -V来查看。
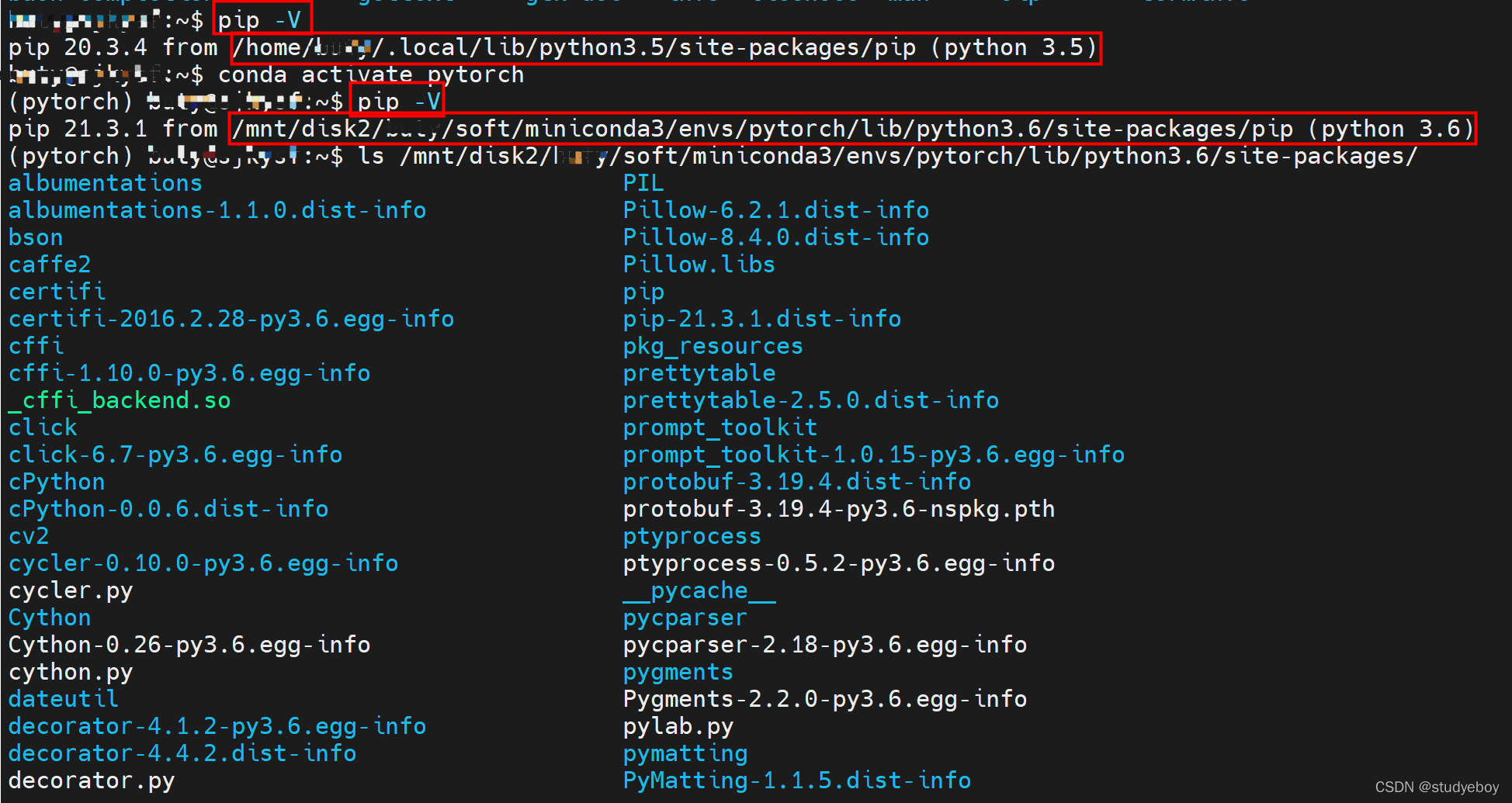
gunicorn在conda虚拟环境下不能通过配置文件启动
该问题需要在gunicorn的配置文件config.py中加入如下代码,只有这样才能在log/error.log中显示问题的内容。不能用字典的形式写输出日志,使用字典的形式输出日志不显示问题的内容。
import os
import gevent.monkey
gevent.monkey.patch_all()import multiprocessing#debug = Truebind = '0.0.0.0:8000'
pidfile = 'log/gunicorn.pid'
accesslog = 'log/access.log'
errorlog = 'log/error.log'
- 问题

- 解决方法
通过测试不是gunicorn版本的问题。主要是因为配置文件中work_class = gevent的问题。将work_class = gevent修改为worker_class = 'gunicorn.workers.ggevent.GeventWorker就可以启动,但是不使用conda虚拟环境下的服务器上work_class = gevent可以直接启动,不需要修改。
import os
import gevent.monkey
gevent.monkey.patch_all()import multiprocessing#debug = Truebind = '0.0.0.0:7788'
pidfile = 'log/gunicorn.pid'
# accesslog = 'log/access.log'
# errorlog = 'log/error.log'logconfig_dict = {'version':1,'disable_existing_loggers': False,'loggers':{"gunicorn.error": {"level": "WARNING",# 打日志的等级可以换的,下面的同理"handlers": ["error_file"], # 对应下面的键"propagate": 1,"qualname": "gunicorn.error"},"gunicorn.access": {"level": "DEBUG","handlers": ["access_file"],"propagate": 0,"qualname": "gunicorn.access"}},'handlers':{"error_file": {"class": "logging.handlers.RotatingFileHandler","maxBytes": 1024*1024*1024,# 打日志的大小,我这种写法是1个G"backupCount": 1,# 备份多少份,经过测试,最少也要写1,不然控制不住大小"formatter": "generic",# 对应下面的键# 'mode': 'w+',"filename": "./log/gunicorn.error.log"# 打日志的路径},"access_file": {"class": "logging.handlers.RotatingFileHandler","maxBytes": 1024*1024*1024,"backupCount": 1,"formatter": "generic","filename": "./log/gunicorn.access.log",}},'formatters':{"generic": {"format": "'[%(process)d] [%(asctime)s] %(levelname)s [%(filename)s:%(lineno)s] %(message)s'", # 打日志的格式"datefmt": "[%Y-%m-%d %H:%M:%S %z]",# 时间显示方法"class": "logging.Formatter"},"access": {"format": "'[%(process)d] [%(asctime)s] %(levelname)s [%(filename)s:%(lineno)s] %(message)s'","class": "logging.Formatter"}}
}capture_output = True
#loglevel = 'warning'
loglevel = 'debug'daemon = True #后台启动
reload = True#workers = multiprocessing.cpu_count()
workers = 1
#worker_class = 'gevent'
worker_class = 'gunicorn.workers.ggevent.GeventWorker'
x_forwarded_for_header = 'X-FORWARDED-FOR'
安装的pytorch是CPU版本
conda环境中python为3.7时,用conda命令安装的pytorch可能时cpu版本,需要用conda list确认安装的是否是GPU版本。
conda install pytorch==1.4.0 torchvision cudatoolkit=10.0
Pillow、Numpy版本造成的错误
-
Pillow
ImportError: cannot import name 'PILLOW_VERSION' from 'PIL'安装pillow==8.4.0版本
-
numpy
安装numpy==1.20.0版本ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
参考资料
conda—学习笔记
在Anaconda虚拟环境中pip安装的包无法使用
CUDA Execution Provider
gunicorn flask启动没有多个worker_Gunicorn常用配置
ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
import torchvision报错ImportError: cannot import name ‘PILLOW_VERSION’ from ‘PIL’
解决torch.cuda.is_available()一直返回False的玄学方法之一
这篇关于conda 环境中部署gunicorn+flask项目的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








