本文主要是介绍决策树实现图像分类(JMU-机器学习作业),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
决策树实现图像分类(JMU-机器学习作业)
文章目录
- 决策树实现图像分类(JMU-机器学习作业)
- 决策树
- 先验知识
- 信息熵
- 条件熵
- 信息增益
- 决策树剪枝
- 预剪枝
- 后剪枝
- 离散型数据分类代码
- 运行结果:
- 连续型数据分类代码
- 运行结果:
决策树
决策树算法属于有监督机器学习算法中的一类经典算法,最早的概念由心理学家E.B.Hunt于1962年提出,意在模仿人类做决策的一系列过程。算法的一大特点便是符合直觉且非常直观,可解释性强。决策树算法兴起于上世纪80年代,在这期间诞生了许多有名的决策树算法,其中最著名的便属三种决策树方法,分别是ID3[QuinLan 1986], C4.5[QuinLan 1993]和CART[Breiman et al. 1984]。其中ID3和C4.5主要用于分类任务,CART既可以用于分类任务,也适用于回归任务。
先验知识
信息熵
信息熵指所有可能发生的事件的信息量的期望,公式如下
H ( Y ) = − ∑ i = 1 N P ( y i ) l o g P ( y i ) H(Y)=-\sum ^N_{i=1} P(y_i)logP(y_i) H(Y)=−i=1∑NP(yi)logP(yi)
条件熵
条件熵:表示在X给定条件下,Y的条件概率分布的熵对X的数学期望。其数学推导如下
KaTeX parse error: Expected 'EOF', got '&' at position 9: H(Y|X) &̲= \sum_{x\in X}…
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性
信息增益
信息增益是知道了某个条件后,事件的不确定性下降的程度。写作 g(X,Y)。它的计算方式为熵减去条件熵,公式如下
g i n i ( X , Y ) = H ( Y ) − H ( Y ∣ X ) gini(X,Y)=H(Y)-H(Y|X) gini(X,Y)=H(Y)−H(Y∣X)
决策树剪枝
预剪枝
预剪枝是指在决策树生成决策节点之前,先对每个划分结点进行估计,若当前节点的划分不能带来决策树泛化性能的提升,则停止划分并将当前节点标记为叶节点。
预剪枝的要点就在于“决策树泛化性能的提升”,如何判断一棵决策树增加一一个决策节点后泛化性能是否提升,可以通过将训练集划分为两部分,一部分作为训练集,另一部分作为验证集,这种方法叫”留出法“,通过训练集训练决策树,然后在验证集上评估其泛化性能。
后剪枝
后剪枝则是先依据训练集生成一棵完整的决策树,然后自底向上的对非叶子节点进行考察,若将该节点对于的子树替换为叶节点能带来决策树泛化性能的提升,则将该子树替换为叶子节点,否则保留。
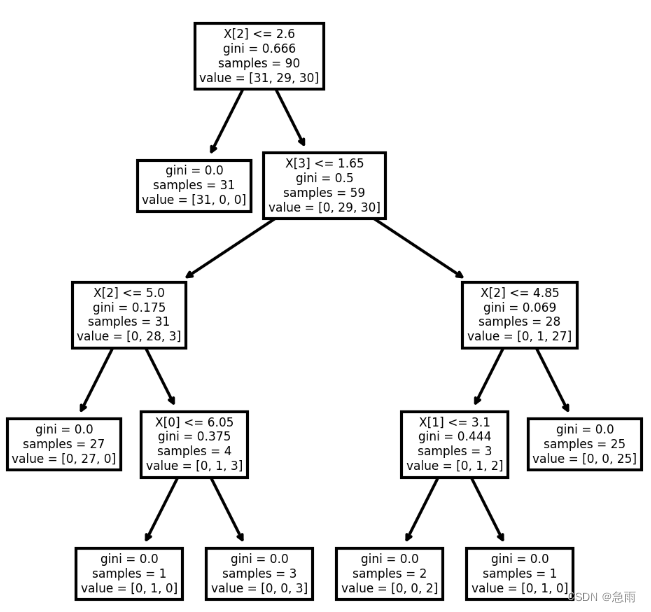
离散型数据分类代码
离散型数据使用iris鸢尾花数据集进行测试
iris = load_iris()X_train, X_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, test_size=0.4, random_state=1)model = tree.DecisionTreeClassifier(criterion='gini',splitter='best',max_depth=7)model.fit(X_train,y_train)score = model.score( X_test,y_test)fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (4,4), dpi=300)tree.plot_tree(model)fig.savefig('imagename.png')print("score:",score)
运行结果:
score:0.9666666666666667
连续型数据分类代码
连续型数据使用上次KNN算法的图像数据集进行分类,连续型数据离散化方法使用等宽法
def main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print(device)data_transform = { # 数据预处理函数# transforms.Compose:将使用的预处理方法打包成一个整体"train": transforms.Compose([transforms.Resize((224, 224)), # 随机裁剪为224*224像素大小transforms.RandomHorizontalFlip(), # 水平方向上随机翻转transforms.ToTensor(),# 将原本的取值范围0-255转化为0.1~1.0# 且将原来的序列(H,W,C)转化为(C,H,W)transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),# 使用均值和标准差对Tensor进行标准化"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}root_path = os.getcwd()data_path = os.path.abspath(os.path.join(root_path, "data_set"))train_path = os.path.abspath(os.path.join(data_path, "train"))val_path = os.path.abspath(os.path.join(data_path, "val"))model_path = os.path.abspath(os.path.join(root_path, "model"))train_dataset = datasets.ImageFolder(root=train_path, transform=data_transform["train"])train_num = len(train_dataset)date_list = train_dataset.class_to_idx # 类名对应的索引cla_dict = dict((val, key) for key, val in date_list.items()) # 遍历字典,将key val值返回json_str = json.dumps(cla_dict, indent=4) # 通过json将cla_dict字典进行编码with open('class.json', 'w') as json_file:json_file.write(json_str) # ‘class_indices.json’, 将字典的key值保存在文件中,方便在之后的预测中读取它的信息batch_size = 1train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=0)validata_dataset = datasets.ImageFolder(root=val_path, transform=data_transform["val"])val_num = len(validata_dataset)validata_loader = torch.utils.data.DataLoader(validata_dataset,batch_size=batch_size, shuffle=False,num_workers=0)data=[]labels=[]K_temp=[] for step, train_data_ in enumerate(train_loader, start=0):train_images, train_labels = train_data_train_images= train_images.reshape(1, 150528)*100data.append(pd.cut(train_images.squeeze().numpy(),5,labels=range(5)))labels.append(train_labels.numpy())X_train, X_test, y_train, y_test = model_selection.train_test_split( data, labels, test_size=0.4, random_state=1model = tree.DecisionTreeClassifier(criterion='gini',splitter='best',max_depth=2)model.fit(X_train,y_train)score = model.score( X_test,y_test)fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (4,4), dpi=300)tree.plot_tree(model)fig.savefig('imagename.png')print("score:",score)
if __name__ == "__main__":main()
运行结果:
score:0.6666667
这篇关于决策树实现图像分类(JMU-机器学习作业)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







