本文主要是介绍Redis中的BitMap、HyperLogLog、一致性Hash算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
BitMap数据结构
HyperLogLog数据结构
Redis中的HyperLogLog
HyperLogLog的核心思想
Redis集群一致性Hash算法
使用Hash取模的问题
一致性Hash算法
一致性Hash算法的容错性和可扩展性
Hash环的数据倾斜问题
BitMap数据结构
操作的最小单元是比特位(bit)
位图,由比特位(bit)组成的数组。底层的数据类型实际上是字符串,字符串的本质上是二进制大对象,所以可以将其视为位图。
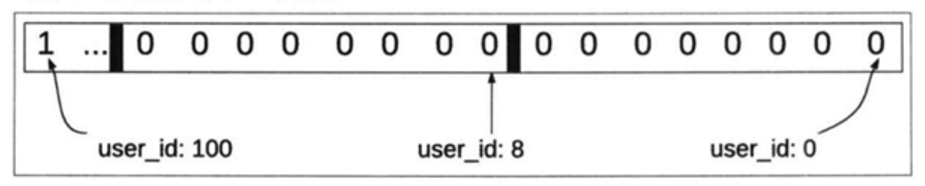
实际生产中可以用bitMap做标志位,0和1
HyperLogLog数据结构
HyperLogLog通常用来做基数计数,即统计一个集合中不重复元素的个数。当一个集合中新来一个元素,如果集合中不包含,则将加入;如果集合中包含,则不加入,计数值就是元素数量,但是有两个问题:
-
- 当统计的数据量变大时,相应的存储内存也会线性增长
- 当集合变大,判断其是否包含新加入元素的成本也会变大
HyperLogLog就可以用来优化使用结合类型时存在的内存和性能问题。
HyperLogLog本身是不存储数据的。
HyperLogLog使用固定数量的内存(12kb)。
HyperLogLog 最大可以计算 2∧64 个不同元素的基数。
HyperLogLog底层使用的是伯努利分布算法,所以返回的基数不是准确的,存在 0.81% 的误差。
Redis中的HyperLogLog
Redi用16384(2∧14)个桶来实现HLL结构,使标准误差达到0.81%
Redis使用的函数具有64位输出,前 14位 来寻址“桶”,剩下的 50位 用来计算左边 0 的数量(连0数)。每个存储子集将存储最大的 “连0数” ,最大可能为50(64位 - 14 位寻址,剩下50位存储“连0数”),每个存储子集需要用6位(2∧6 bit)来存储 “连0数”,16384桶即98304bit,转换为byte即为98304/8 = 12288 byte = 12kb,所以在Redis中每个HyperLogLog占用12kb。
HyperLogLog的核心思想
利用一个元素的HashCode除14为寻址位外最左边的 “连0数” ,来推导元素个数,比如:
扔到目前,我记录的最大左连0个数为3,那么我就有一定的依据推测你扔了23个元素,但是,hyperloglog为了让推算更准确,它采用了一个分桶的机制,我会用很多个桶来分别记录该桶中出现过的最大连零数,然后,利用每个桶的最大连0数倒推基数,并最后将每个桶的倒推基数结果求调和平均值,作为最终推测基数;

先用连0数来推导元素个数,然后对所有桶的元素个数求调和平均值,降低极端值对结果的影响
严格的数学证明,需要用到伯努利分布,多重伯努利实验以及似然估计等数学知识,可参考 :
https://www.cnblogs.com/linguanh/p/10460421.html
https://www.yuque.com/abser/aboutme/nfx0a4
https://zhuanlan.zhihu.com/p/77289303
https://zhuanlan.zhihu.com/p/26614750 一文搞懂极大似然估计
Redis集群一致性Hash算法
Redis集群中使用Hash取模(对master数量取模)的方式对数据的分布位置进行定位,

使用Hash取模的问题
使用HashCode对master取模虽然可以快速定位机器位置,但是当集群增加机器或者机器宕机导致进群master数量发生变化的时候,Hash对master数量取模的值就会发生变化,导致缓存的位置发生变化,Redis缓存雪崩,当应用无法从缓存中读取数据时就会从数据库中读取数据。
假设:我们增加了一台缓存服务器,那么缓存服务器的数量就由4台变成了5台。那么原本hash(a.png) % 4 = 2 的公式就变成了 hash(a.png) % 5 =? 。假设有20个数据需要存储,在有4个redis节点的时候如下图:

当我们添加1个redis节点之后,数据的分布如下图所示:

一致性Hash算法
一致性Hash算法不能完全解决机器增加或者减少带来的缓存失效的问题,只能是降低对Redis缓存带来的影响。
一致性Hash算法也是采用的取模方法,只是之前是对服务器数量进行取模,而一致性Hash算法是对2∧32-1取模。一致性Hash算法是将整个Hash值看做是一个圆环,如假设某哈希函数H的值空间为0~(2∧32-1)
整个哈希环如下:

整个空间按顺时针方向组织,圆环正上方的点代表0,0点右侧的第一个点为1,以此类推,直到2∧32-1 和2∧32-1在零点重合,我们把这个圆环称为Hash环。
然后可以选择各个服务器的IP或者主机名作为关键字进行Hash来确定每台机器在Hash环上的位置,如下:

接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
一致性Hash算法的容错性和可扩展性
现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器,如下图中NodeC与NodeB之间的数据,图中受影响的是ObjectC)之间数据,其它不会受到影响,如下所示:

下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:

此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X !一般的,在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下:

此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:

同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布,通俗点的原理如下图所示:

由于虚拟节点V1、V2映射到了真实节点N1,当数据object1确定到Hash环上的位置并找到虚拟节点V2的时候,其真实位置则是位于真实节点N1上。
这篇关于Redis中的BitMap、HyperLogLog、一致性Hash算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







