本文主要是介绍时序数据库Influxdb查询多个字段_field同一时间的值,组成一条数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Influxdb将表格数据多个字段_field从垂直列布局聚合成水平布局行字段。
问题
1、Influxdb 是一种时间序列数据库,在我的项目中主要用来存储换热站的测点数据的。换热站有非常多的测点,我们用Flux 语法去查询测点数据,返回的数据结构是每个测点字段对应的所有时间数据。
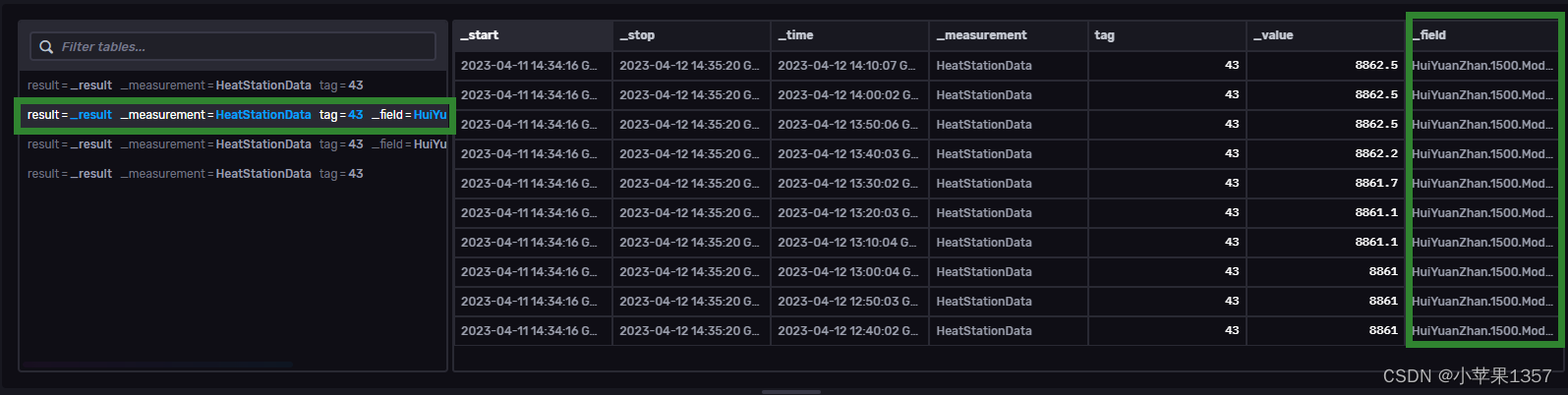
from(bucket: "autodata")|> range(start:2023-04-11T06:34:16.000Z, stop:2023-04-12T06:35:20.000Z)|> filter(fn: (r) => r._measurement == "HeatStationData")|> filter(fn: (r) => r["_field"] == "HuiYuanZhan.1500.TT_17_PV" or r["_field"] == "HuiYuanZhan.1500.Level_1_PV" or r["_field"] == "HuiYuanZhan.1500.Modbus_FLMeter_5_LLLL") |> sort(columns:[ "_time"], desc: true) |> limit(n:10, offset: 1) 2、而我想要的数据格式则是这几个field字段的值作为行字段水平展示,并根据时间聚合在一起,形成一条根据时间的完整数据。也就是我想查询多个字段同一时间的值,组成一条数据。
解决方法
Flux 查询提供了两种方式来解决这个问题:
1、 pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
使用pivot将_field的_value值,作为一个行字段。这样就可以查询同一时间,这三个字段的值了
from(bucket: "autodata")|> range(start:2023-04-11T06:34:16.000Z, stop:2023-04-12T06:35:20.000Z)|> filter(fn: (r) => r._measurement == "HeatStationData")|> filter(fn: (r) => r["_field"] == "HuiYuanZhan.1500.TT_17_PV" or r["_field"] == "HuiYuanZhan.1500.Level_1_PV" or r["_field"] == "HuiYuanZhan.1500.Modbus_FLMeter_5_LLLL") |> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")|> sort(columns:[ "_time"], desc: true) |> limit(n:10, offset: 1) 
2、v1.fieldsAsCols()
这是一个Flux 查询提供的函数,使用时,需要先引入,他的功能跟上边的pivot效果是一样的。
import "influxdata/influxdb/v1"from(bucket: "autodata")|> range(start:2023-04-11T06:34:16.000Z, stop:2023-04-12T06:35:20.000Z)|> filter(fn: (r) => r._measurement == "HeatStationData")|> filter(fn: (r) => r["_field"] == "HuiYuanZhan.1500.Modbus_FLMeter_5_LLLL" or r["_field"] == "HuiYuanZhan.1500.Level_1_PV" or r["_field"] == "HuiYuanZhan.1500.TT_17_PV") |> sort(columns:[ "_time"], desc: true) |> v1.fieldsAsCols()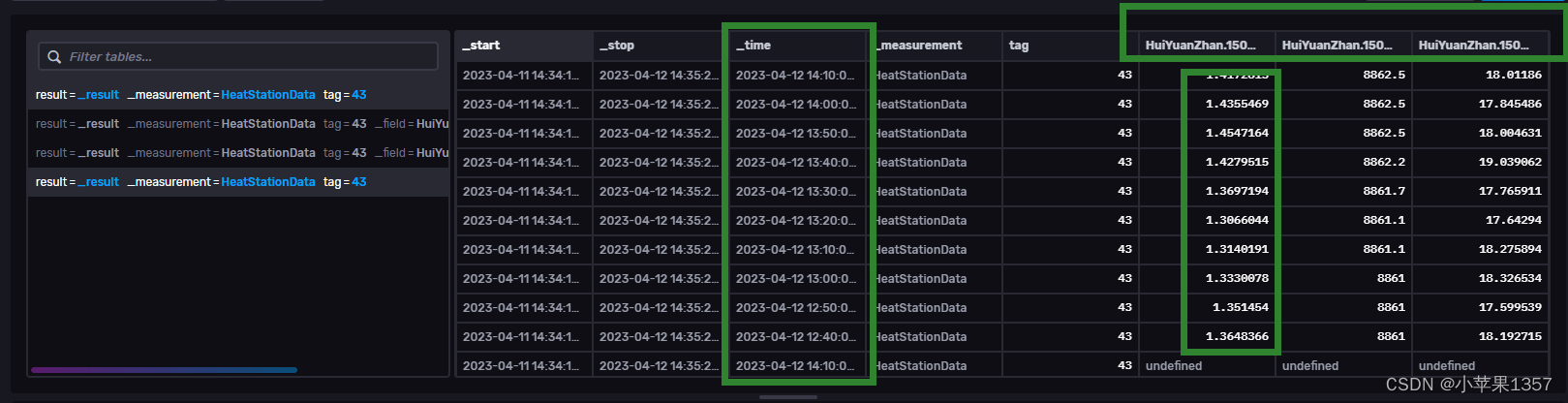
这篇关于时序数据库Influxdb查询多个字段_field同一时间的值,组成一条数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





