本文主要是介绍基于Hive的河北新冠确诊人数分析系统的设计与实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目描述
临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问题,今天给大家介绍一篇基于Hive的河北新冠确诊人数分析系统的设计与实现。
功能需求
首先要采集数据,采用脚本定时采集的那种,用java程序,先转化为用tab键分割的文本数据,然后导入hive中;
其次是在hive中对导进来的数据进行处理过滤,再建几个表,把处理结果存到新建的表里,然后把hive处理结果的数据表导入mysql中;这样做完一次后,开始写脚本,每隔一天采集一次数据,hive处理数据一次,mysql统计数据一次;
接着就是编程,用ssm框架连接到mysql,对数据用javaBean进行封装,用mvc模式将部分数据显示到前台页面;
最后用echarts对封装的数据进行数据可视化,可以做成条形图,折线图,饼图,气泡图,地图等可视化图标。
数据清理流程:
- 首先执行GetData.jar写好的程序获取数据,会自动生成txt数据文件在/home/kt/devHive/data文件夹里面
- 然后执行导入数据到建好的hive表里面的脚本
- 接着执行sql,sql会执行clean.sql里面的加工数据的hql语句,会将清理好的数据导入Ed的清洁hive表中
- 接着执行hiveToMySql.sh,将Ed表里面的清洁数据用sqoop导入对应的MySQL表中(会清空 *Ed 的所有数据)
- 最后可以用远程连接获取MySQL里的数据
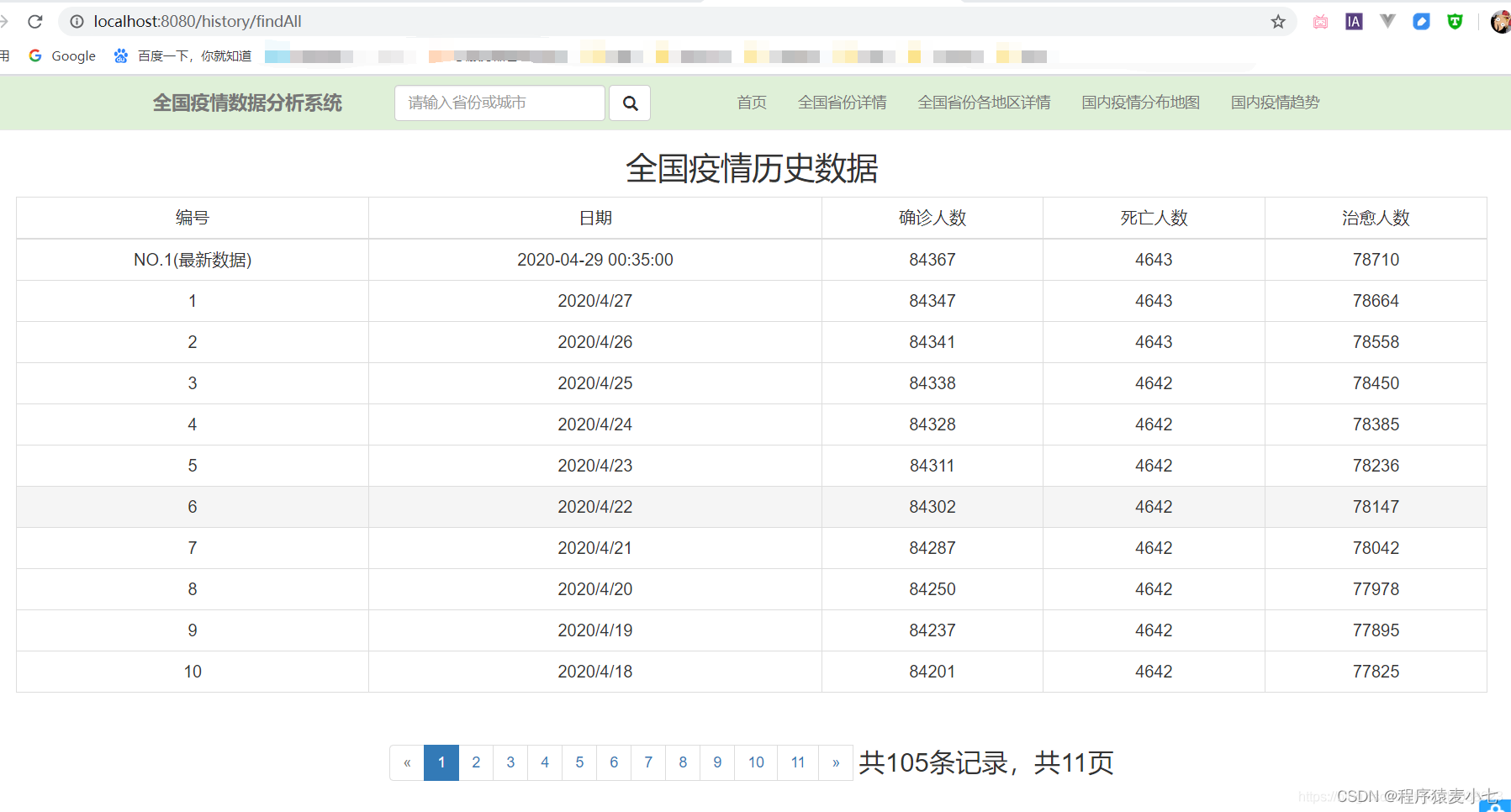
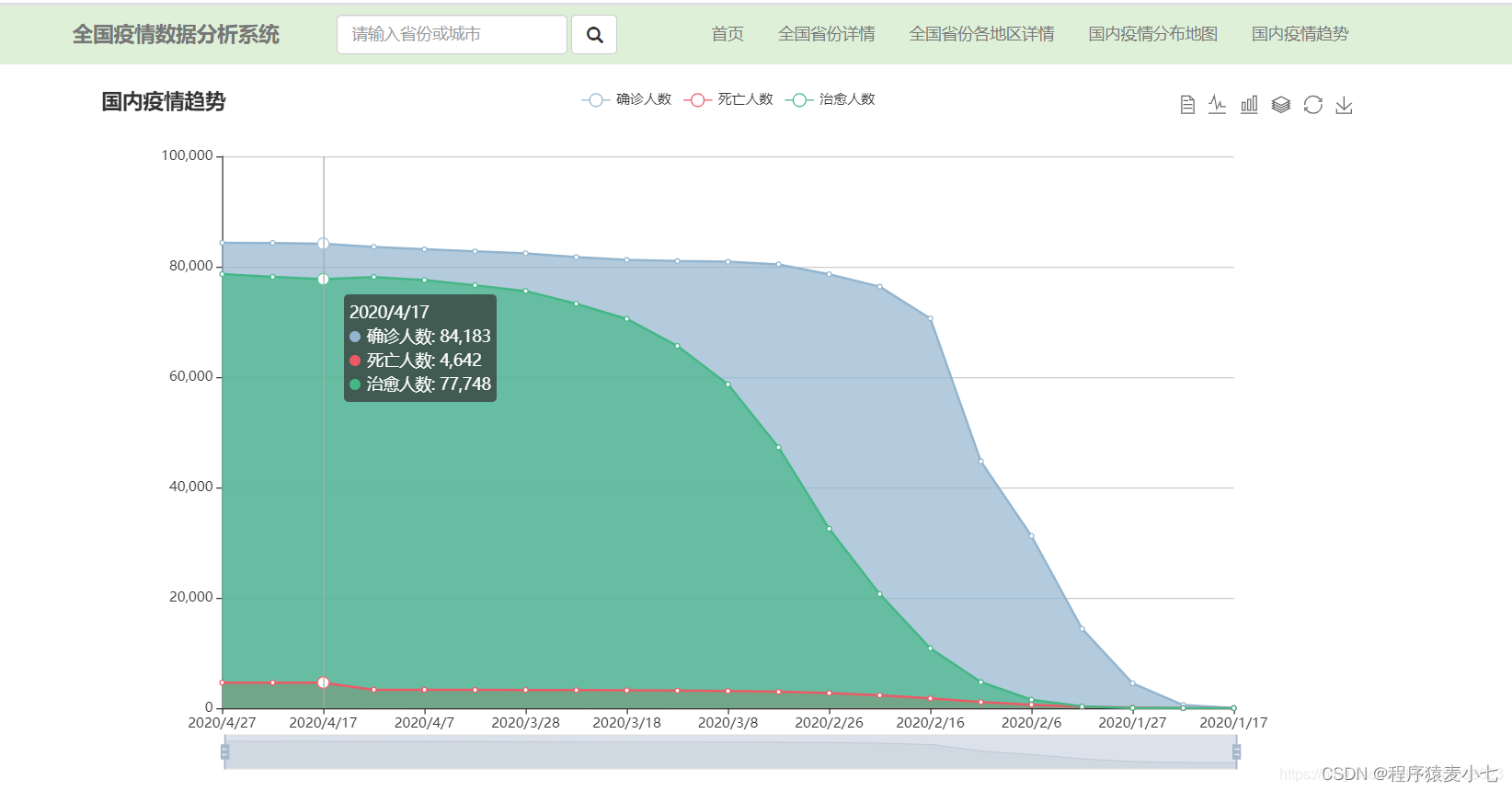
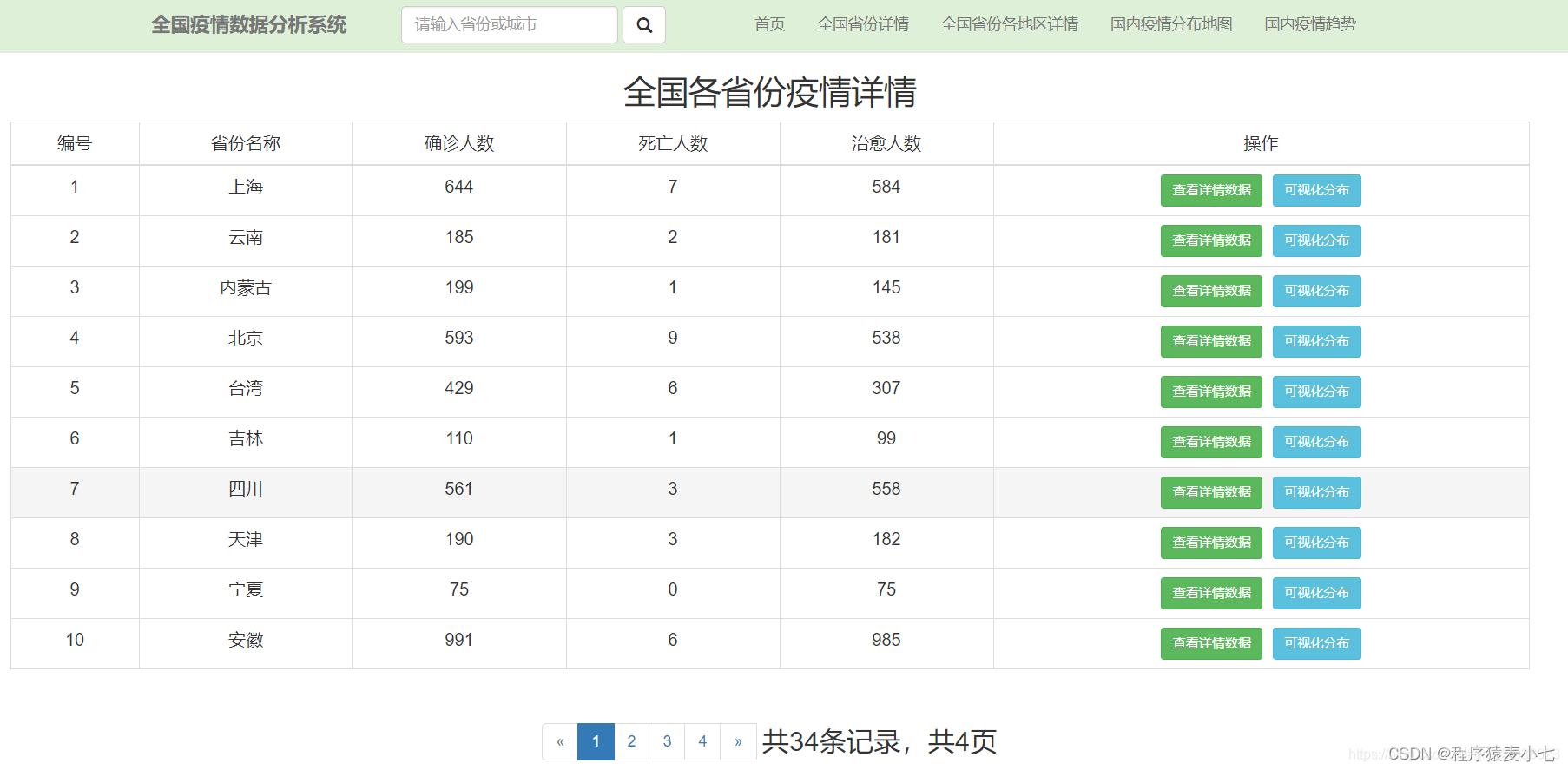
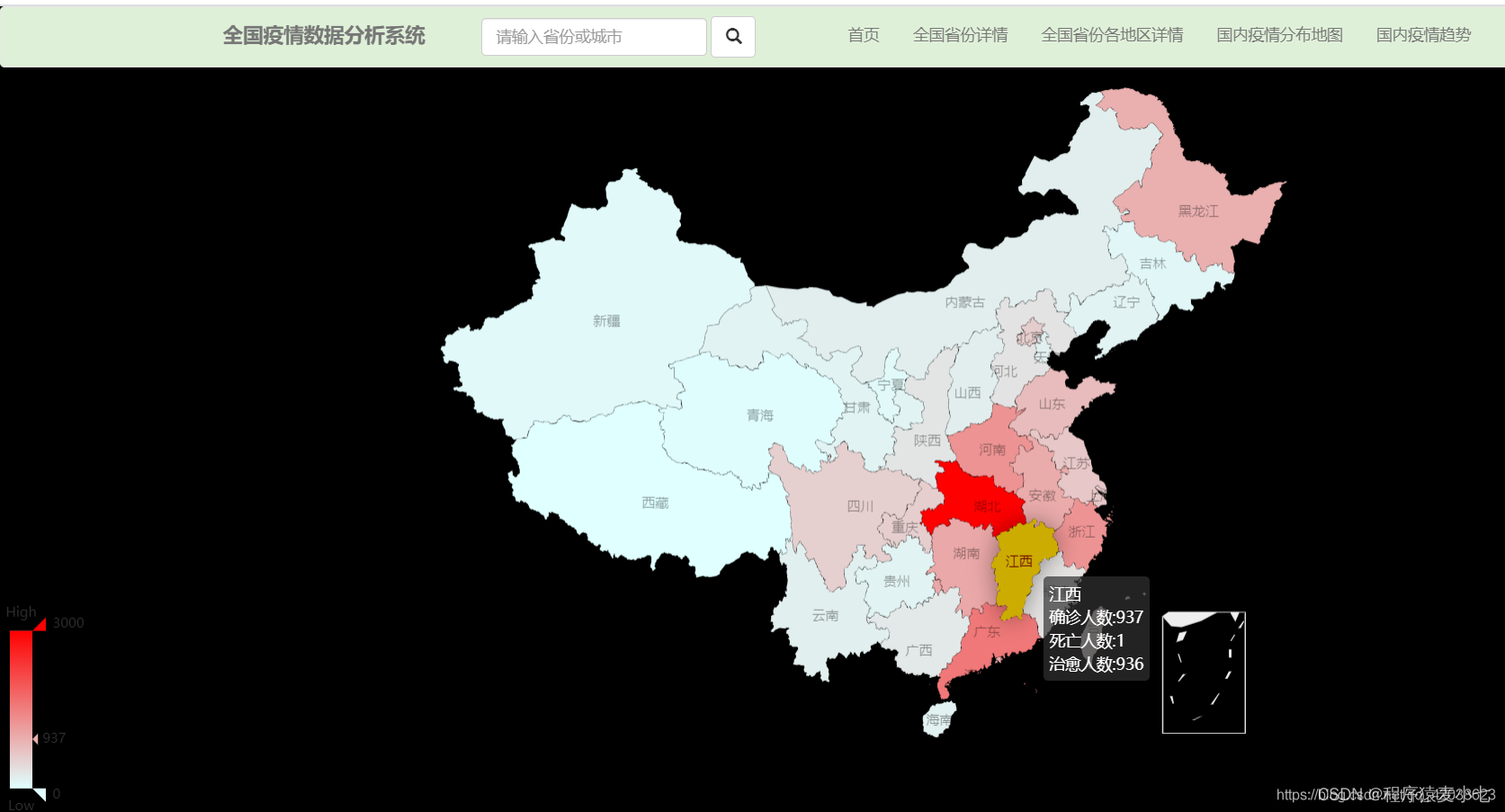
部分效果图
数据库设计
hive对数据处理筛选,导入MySQL
1. 河北疫情分布地图
确诊病例
死亡病例
治愈病例
create table provinceEd(
provinceName string,
confirmedNum int,
deathsNum int,
curesNum int
)
row format delimited fields terminated by ‘\t’;
2. 各个地区的疫情分布地图
确诊病例
死亡病例
治愈病例
create table areaEd(
provinceName string,
cityName string,
confirmedCount int,
deadCount int,
curedCount int
)
row format delimited fields terminated by ‘\t’;
3. 国内疫情趋势
确诊病例
死亡病例
治愈病例
create table historyEd(
date string,
confirmedNum int,
deathsNum int,
curesNum int
)
row format delimited fields terminated by ‘\t’;
4. 各市地区疫情的表格
(用historyEd,带有全国数据的最新数据totlaed)
#建表语句
CREATE TABLE totalEd(
date string,
diagnosed int,
death int,
cured int
)
row format delimited fields terminated by ‘\t’;
5. 一个新闻的专栏
pubData 具体时间
title 新闻标题
summary 新闻详情
infoSource 新闻来源
sourceUrl 新闻正文链接传送
CREATE TABLE newsEd(
pubDate string,
title string,
summary string,
infoSource string,
sourceUrl string,
provinceName string
)
row format delimited fields terminated by ‘\t’;
脚本
1. 导入数据的hql语句(load.sql)
set hive.exec.mode.local.auto=true;
set hive.support.sql11.reserved.keywords=false;
use kongtao;
load data local inpath ‘/home/kt/devHive/data/history.txt’ overwrite into table history;
load data local inpath ‘/home/kt/devHive/data/total.txt’ overwrite into table total;
load data local inpath ‘/home/kt/devHive/data/province.txt’ overwrite into table province;
load data local inpath ‘/home/kt/devHive/data/area.txt’ overwrite into table area;
load data local inpath ‘/home/kt/devHive/data/news.txt’ overwrite into table news;
2. 获取数据的脚本 getData.sh
#!/bin/bash
. /etc/profile
HIVE_HOME=/app/hive/
yesterday=date -d -0days '+%Y%m%d'
hour=date -d -0hour '+%H'
echo $yesterday
H I V E H O M E / b i n / h i v e − − h i v e c o n f d a i l y p a r a m = {HIVE_HOME}/bin/hive --hiveconf daily_param= HIVEHOME/bin/hive−−hiveconfdailyparam={yesterday}
–hiveconf hour_param=${hour}
-f /home/kt/devHive/0425/loa.sql
date >> /var/log/httpd/hivetToMysql.log
echo y e s t e r d a y {yesterday} yesterday{hour} >> /home/kt/devHive/log/hivetToMysql.log
3. clean.sql语句脚本
set hive.exec.mode.local.auto=true;
set hive.support.sql11.reserved.keywords=false;
insert into table kongtao.provinceEd
select provinceName,confirmedNum,deathsNum,curesNum from province;
insert into table kongtao.areaEd
select provinceName, cityName, confirmedCount,deadCount,curedCount from area;
insert into table kongtao.historyEd
select date, confirmedNum, deathsNum,curesNum from history;
insert into table kongtao.totalEd
select date, diagnosed, death,cured from total;
insert into table kongtao.newsEd
select pubDate, title, summary,infoSource,sourceUrl,provinceName from news;
4. 定时执行clean.sql的语句 sql.sh
#!/bin/bash
. /etc/profile
HIVE_HOME=/app/hive/
yesterday=`date -d -0days '+%Y%m%d'`
hour=`date -d -0hour '+%H'`
echo $yesterday
${HIVE_HOME}/bin/hive --hiveconf daily_param=${yesterday} \
--hiveconf hour_param=${hour} \-f /home/kt/devHive/0425/clean.sql
date >> /var/log/httpd/hivetToMysql.log
echo ${yesterday}${hour} >> /home/kt/devHive/log/hivetToMysql.log
hive -e "use ${kongtao};select * from province;"
chmod +x sql.sh
- 定时执行hive导入MySQL的语句
注意:MySQL建表的时候要设置字符编码,否则会字符不匹配导不进去
ENGINE=InnoDB DEFAULT CHARSET=utf8
sqoop导入hive数据到MySql碰到hive表中列的值如果为null的情况,hive中为null的是以\N代替的,所以你在导入到MySql时,需要加上两个参数:–input-null-string ‘\N’ --input-null-non-string ‘\N’,多加一个’',是为转义
#!/bin/bash
. /etc/profile
先清楚表中的所有数据
host="kt01"
port="3306"
userName="root"
password="123456"
dbname="kongtao"
dbset="--default-character-set=utf8 -A"
先清空所有的表,保证数据不重复
cmd="
truncate table areaEd;
truncate table historyEd;
truncate table totalEd;
truncate table provinceEd;
"mysql -h${host} -u${userName} -p${password} ${dbname} -P${port} -e "${cmd}"
导入areaed表
sqoop export
–connect “jdbc:mysql://kt01:3306/kongtao?useUnicode=true&characterEncoding=utf-8”
–username root
–password 123456
–table areaEd
–num-mappers 1
–input-fields-terminated-by “\t”
–export-dir /user/hive/warehouse/kongtao.db/areaed
导入historyed表
sqoop export
–connect “jdbc:mysql://kt01:3306/kongtao?useUnicode=true&characterEncoding=utf-8”
–username root
–password 123456
–table historyEd
–num-mappers 1
–input-fields-terminated-by “\t”
–export-dir /user/hive/warehouse/kongtao.db/historyed
#导入totaled表
sqoop export
–connect “jdbc:mysql://kt01:3306/kongtao?useUnicode=true&characterEncoding=utf-8”
–username root
–password 123456
–table totalEd
–num-mappers 1
–input-fields-terminated-by “\t”
–export-dir /user/hive/warehouse/kongtao.db/totaled
导入provinceed表
sqoop export \
--connect "jdbc:mysql://kt01:3306/kongtao?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--table provinceEd \
--num-mappers 1 \
--input-fields-terminated-by "\t" \
--export-dir /user/hive/warehouse/kongtao.db/provinceed/app/hadoop/bin/hdfs dfs -rm -r /user/hive/warehouse/kongtao.db/*eddate >> /home/kt/devHive/log/hivetToMysql.log
chmod +x hiveToMySql.sh
数据清理流程
首先执行GetData.jar写好的程序获取数据,会自动生成txt数据文件在/home/kt/devHive/data文件夹里面
然后执行导入数据到建好的hive表里面的脚本
接着执行sql,sql会执行clean.sql里面的加工数据的hql语句,会将清理好的数据导入*Ed的清洁hive表中
接着执行hiveToMySql.sh,将Ed表里面的清洁数据用sqoop导入对应的MySQL表中(会清空 Ed 的所有数据)
最后可以用远程连接获取MySQL里的数据
给脚本设置定时器
crontab -e
30 8 * * * /home/kt/devHive/0425/getData.sh
32 8 * * * /home/kt/devHive/0425/sql.sh
34 8 * * * /home/kt/devHive/0425/hiveToMySql.sh
这篇关于基于Hive的河北新冠确诊人数分析系统的设计与实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



