本文主要是介绍性能实测:分布式存储 ZBS 与集中式存储 HDS 在 Oracle 数据库场景表现如何,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:深耕行业的 SmartX 金融团队 金鑫
在金融客户的基础架构环境中,HDS 是一种被广泛使用的存储解决方案。作为集中式存储的代表之一,HDS 拥有高性能、高可用性和可扩展性的企业级存储特点,适用于实时数据处理、虚拟化和灾难备份等场景。
在《分布式存储支持数据仓库业务系统性能验证》文章中,我们对比了 SmartX 分布式存储 ZBS 与全闪集中式存储(EMC PowerStore)执行数仓跑批任务的效率。为了帮助用户了解更多应用场景下 ZBS 与传统集中式存储的性能表现,我们对 ZBS 和 HDS(Hitachi Virtual Storage Platform E590)展开了性能评测,包括基准性能测试和支持 Oracle 数据库的性能测试。结果显示,ZBS(开启 RDMA)在大部分基准测试和 Oracle 场景中,性能和稳定性均优于 HDS 集中式存储。
测试环境
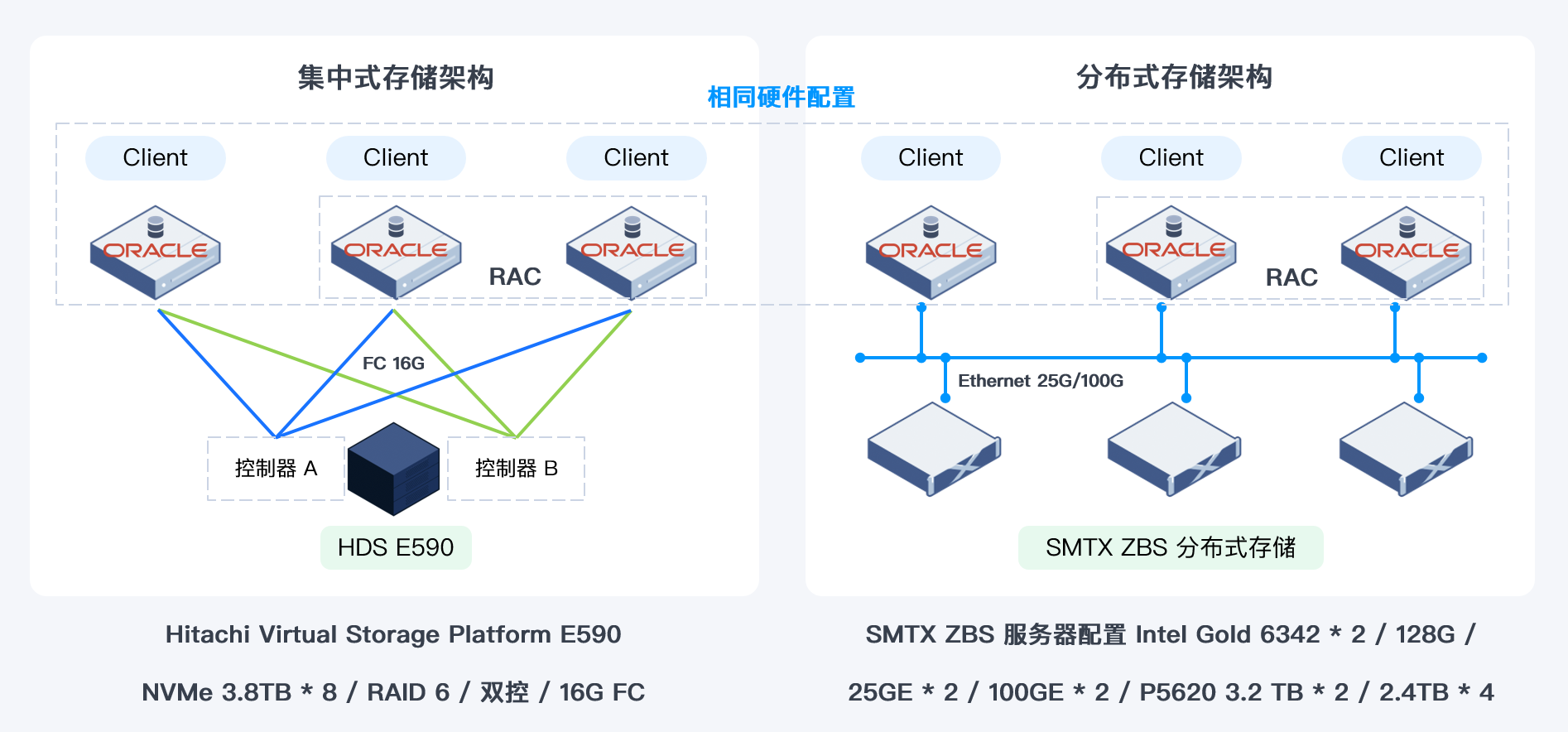
- 准备三台计算节点,一台部署单机 Oracle,另外两台部署 Oracle RAC,采用 Oracle 19c 软件版本。
- 集中存储测试对象 Hitachi Virtual Storage Platform E590
- 利用三台 x86 服务器构建 ZBS 分布式存储
测试过程与结果
存储基准性能测试
基准性能测试利用 FIO 工具,分别测试两个环境在存储基准性能、读写延时控制 500us、长时间(12 小时)运行、快照等条件下的性能表现。其中,在存储基准性能测试用例中,分别测试单计算节点(1P1V 和 1P3V)和三计算节点(3P1V 和 3P3V)的性能表现,延时控制和长时间运行场景均基于 3P1V 进行测试,快照场景基于 1P1V 进行测试*。
* P 表示物理机,V 表示卷。1P1V 表示一个物理机挂载一个卷,1P3V 表示一个物理机挂载三个卷,3P1V 表示三个物理机各挂载一个卷,3P3V 表示三个物理机各挂载三个卷。
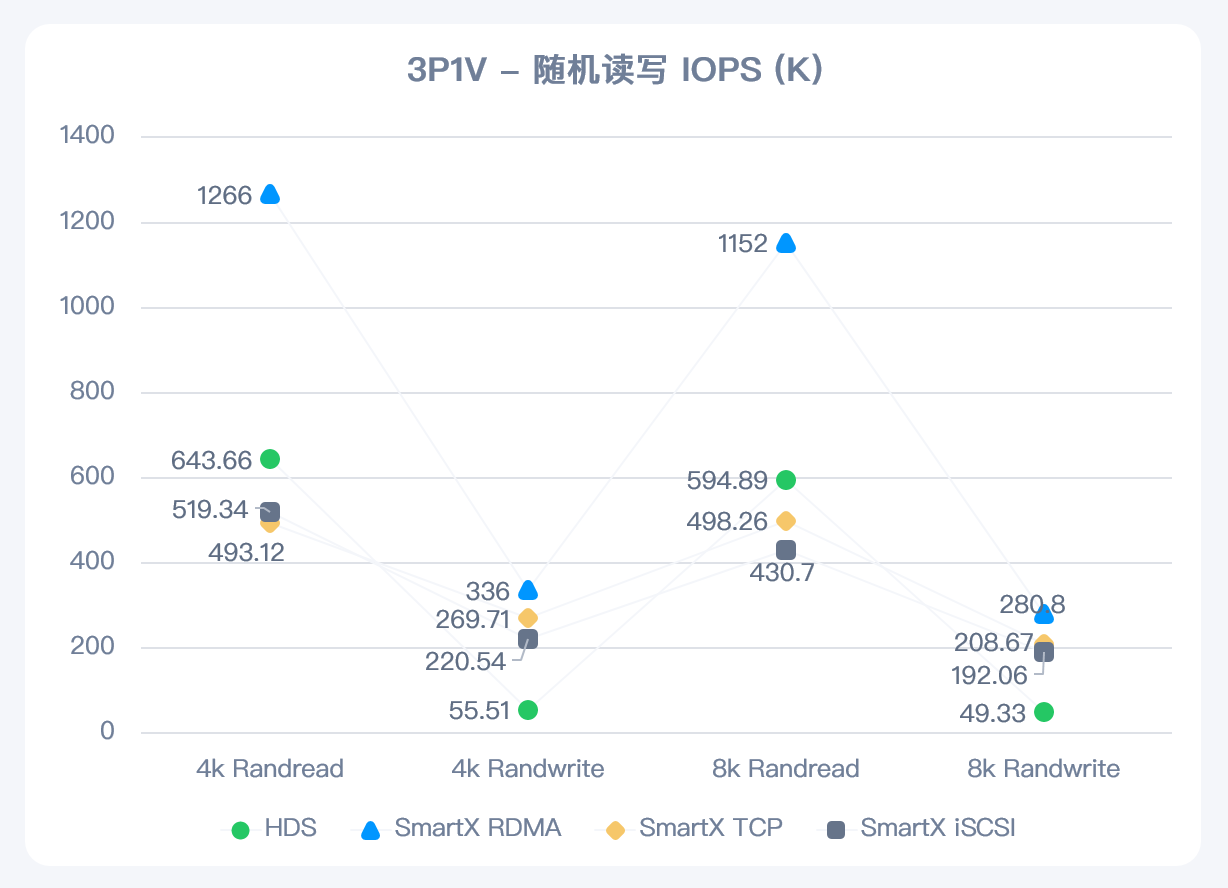
存储基准-单计算节点测试结果



由于 ZBS 在接入网络层面支持 iSCSI、NVMe over TCP 和 NVMe over RDMA(RoCE v2)三种协议,我们分别开启三种协议进行了测试。可以看到,除了 1P3V – 随机读场景下 HDS 的性能和延迟情况要优于 ZBS,其他场景下 ZBS 开启 RDMA 后的性能均优于 HDS,基于 TCP 和 iSCSI 协议的 ZBS 性能与 HDS 性能水平相当。
存储基准-三计算节点测试结果

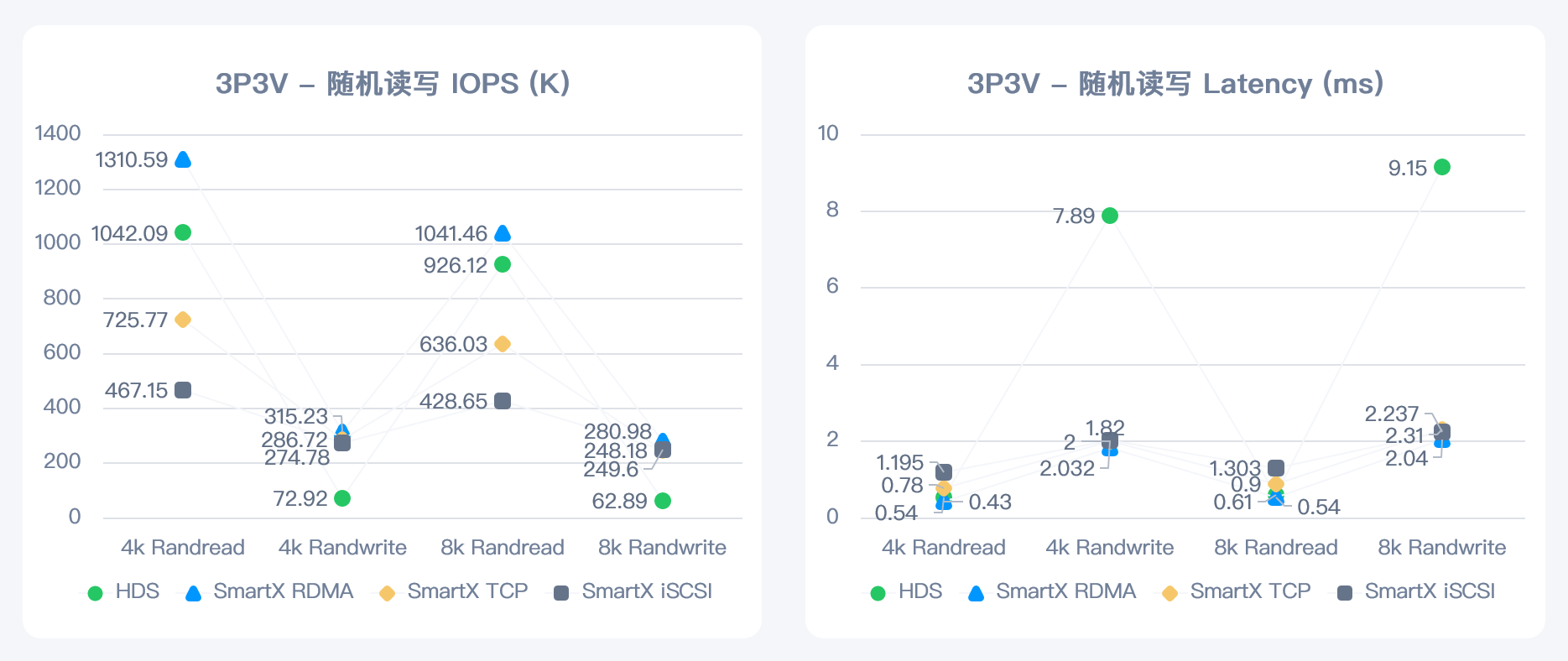

在三计算节点配置下,ZBS 开启 RDMA 后性能均优于同一场景下的 HDS 存储。
读写延时控制 500us 测试结果
读写延时分别控制在 500us 时,ZBS 开启 RDMA 后性能远超 HDS (几乎翻倍)。
12 小时长时间测试结果
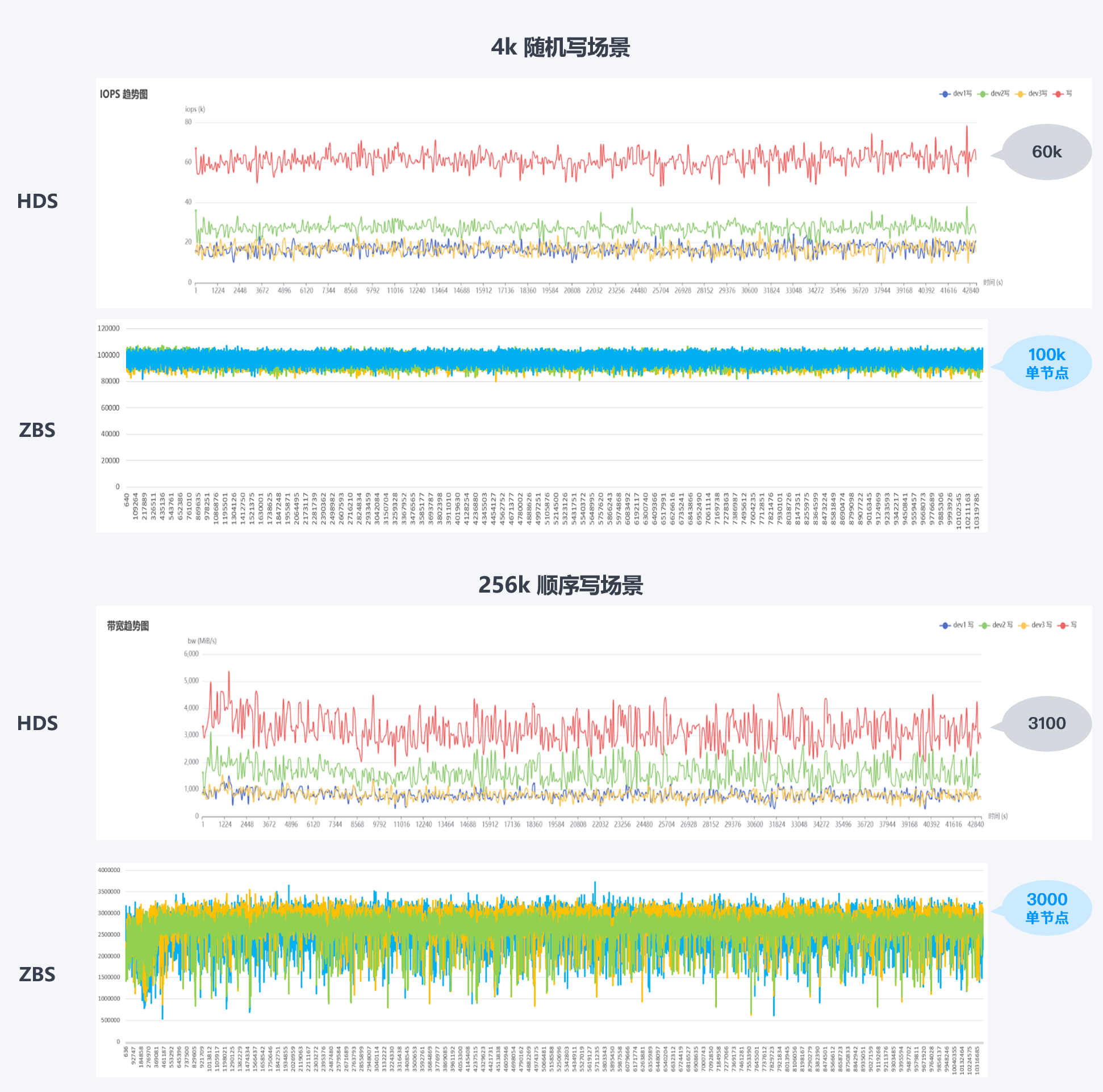
通过 12 小时长时间的性能压测(IODepth 2 *32),观察存储性能抖动,从测试结果中的性能曲线和抖动幅度,可以明显观察到,ZBS 性能表现均优于 HDS,表现出更好的性能稳定性。
卷快照后性能测试结果
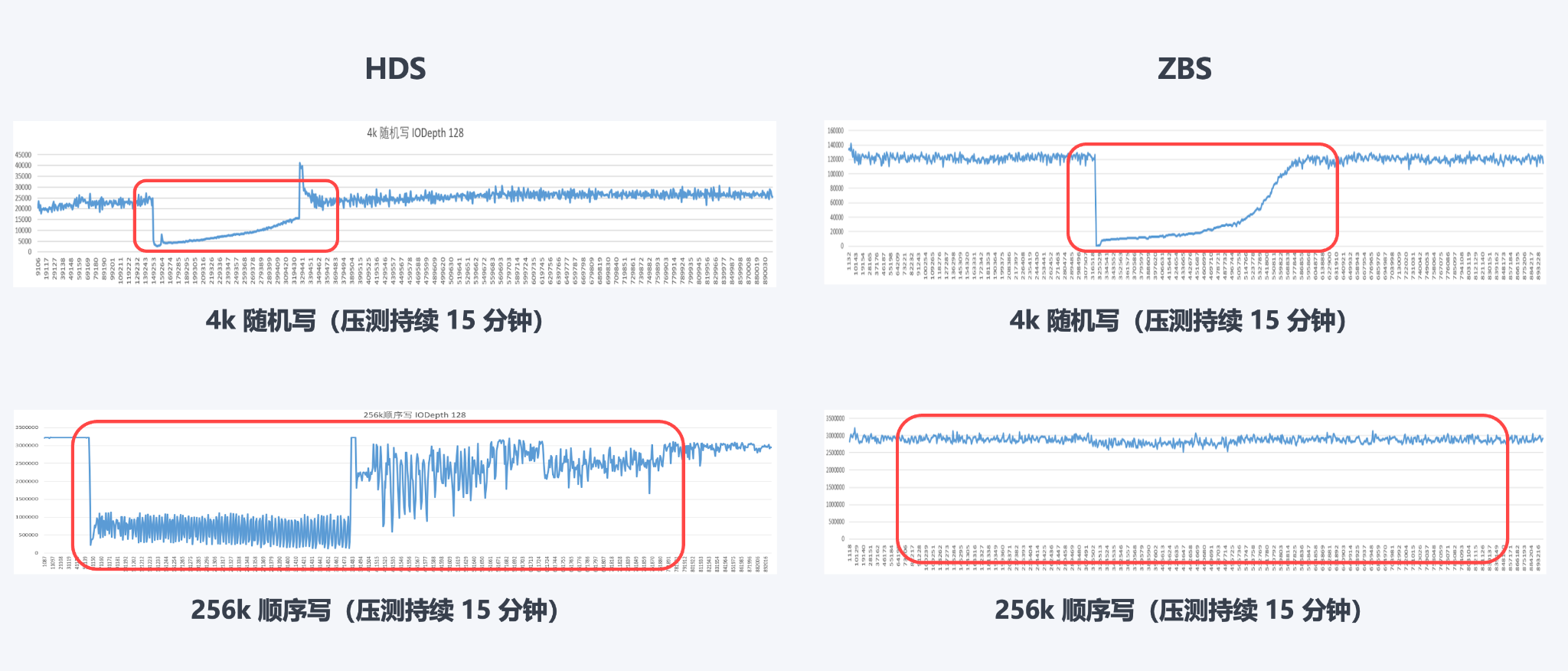
在快照测试中,4k 小块随机写场景下 HDS 与 ZBS 都有一定幅度的性能下降,几分种后恢复到初始性能;256k 大块顺序写场景下,ZBS 性能稳定未受快照事件影响,而 HDS 性能波动较明显。
支持 Oracle 业务性能测试
除了基准性能测试,我们还针对两个环境下 Oracle 数据库性能展开了对比测试,包括单库读写测试、单库 TPCC 测试、RAC 读写测试和 RAC TPCC 测试。
写性能测试
测试场景:
- 基于券商委托插入脚本模拟压力
- 50 并发
- 单并发 150w 数据写入
- 每 1000 笔提交一次
测试结果:
单库:

度量单位:每秒插入数据行数
RAC:
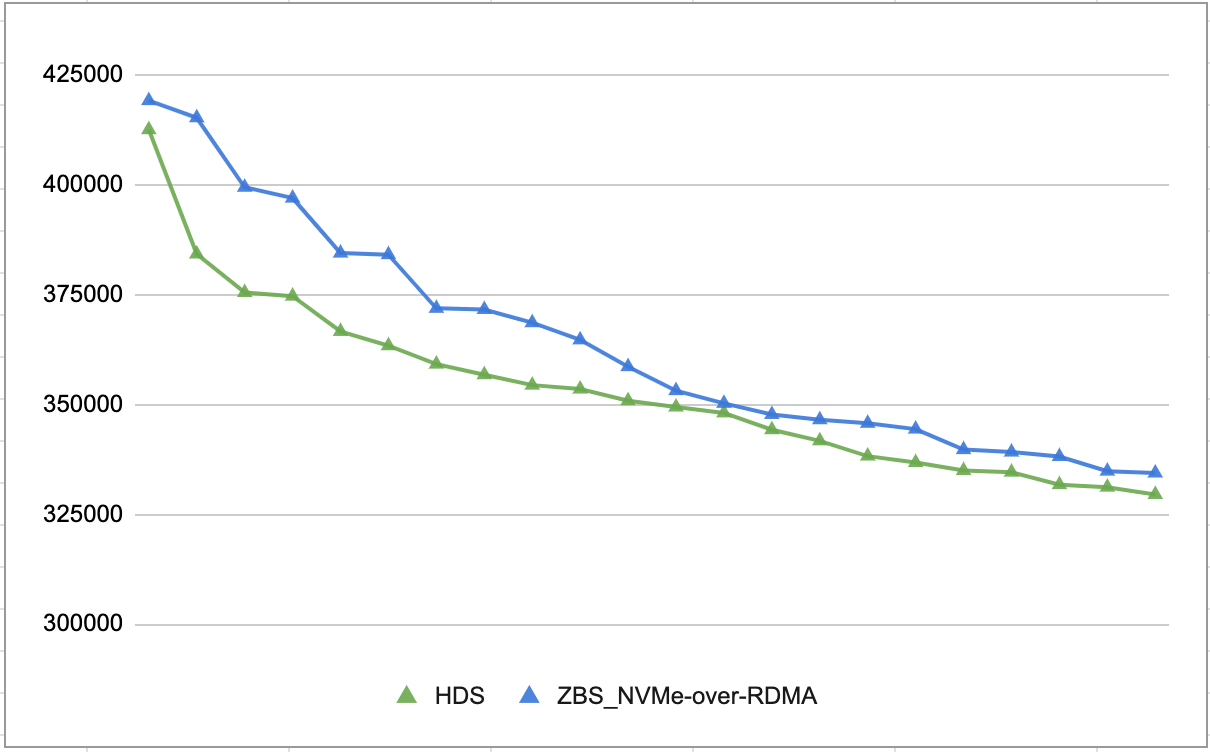
度量单位:每秒插入数据行数
读性能测试
测试场景:
- 使用 CALIBRATE_IO 测试存储过程
- 1T Datafile
- 100G Redofile
测试结果:
单库:

RAC:

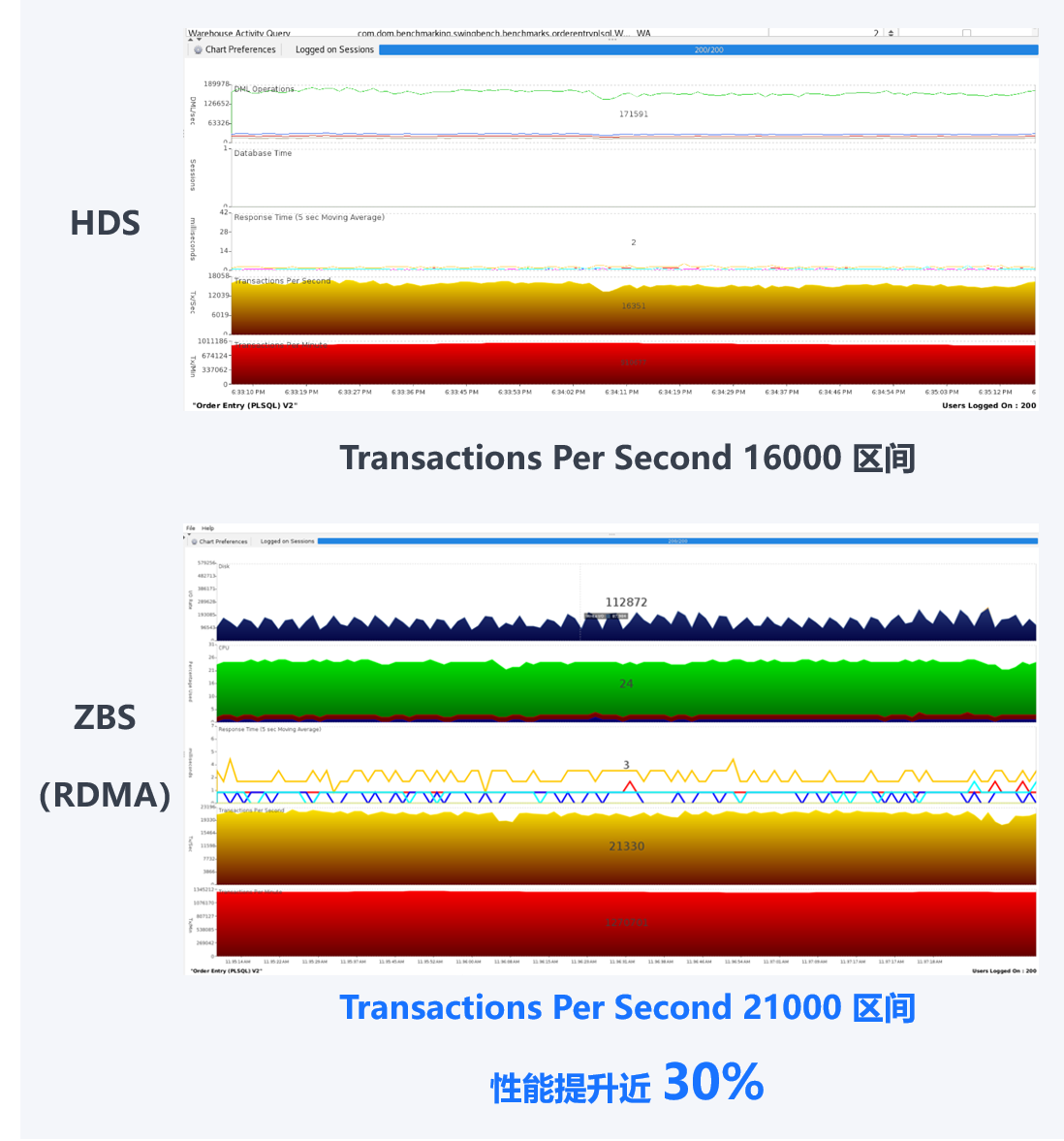
TPCC 测试
测试场景:
- 使用 Swingbench 进行测试
- 200 并发
测试结果:
单库:
RAC:
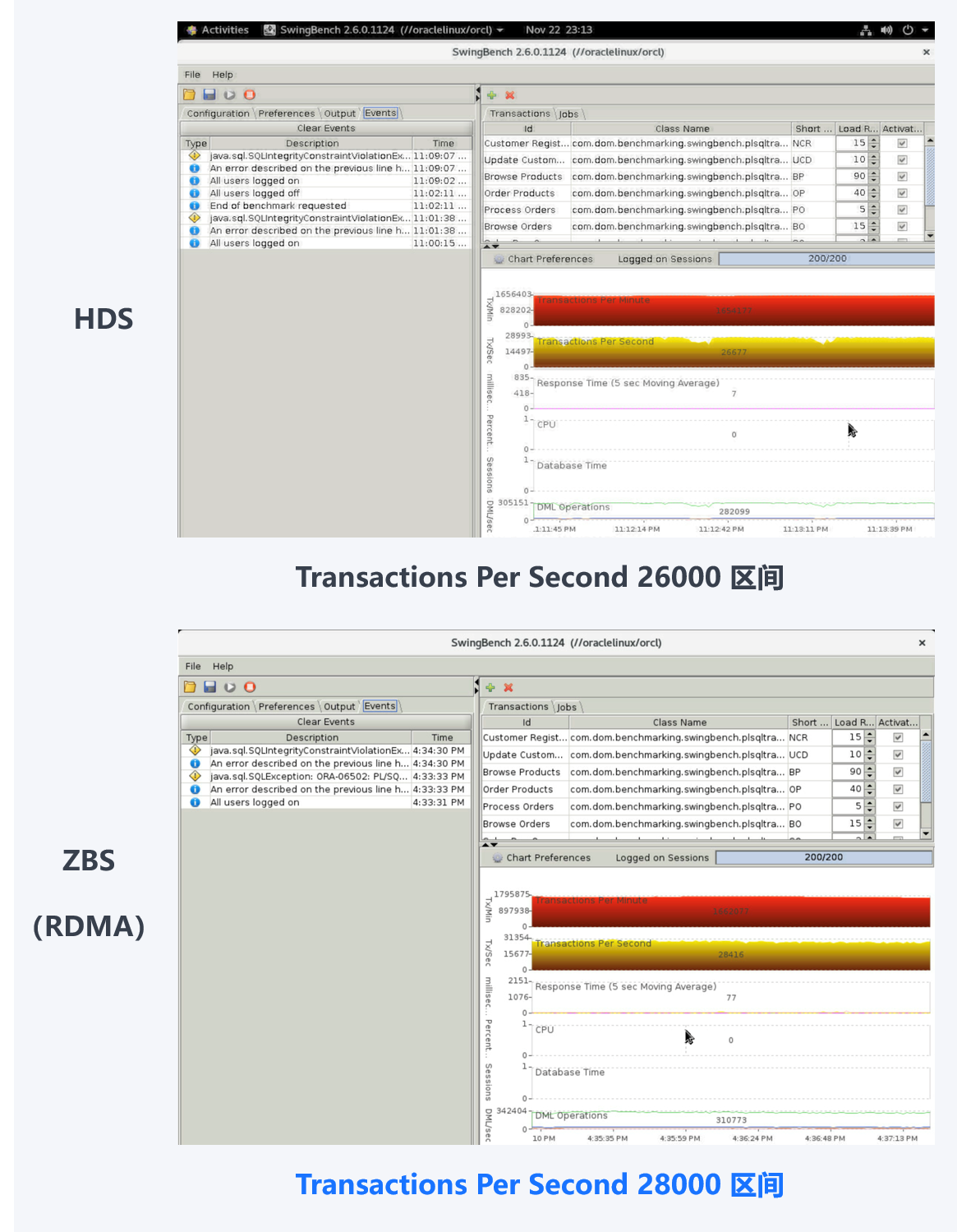
RAC(存储混合负载):
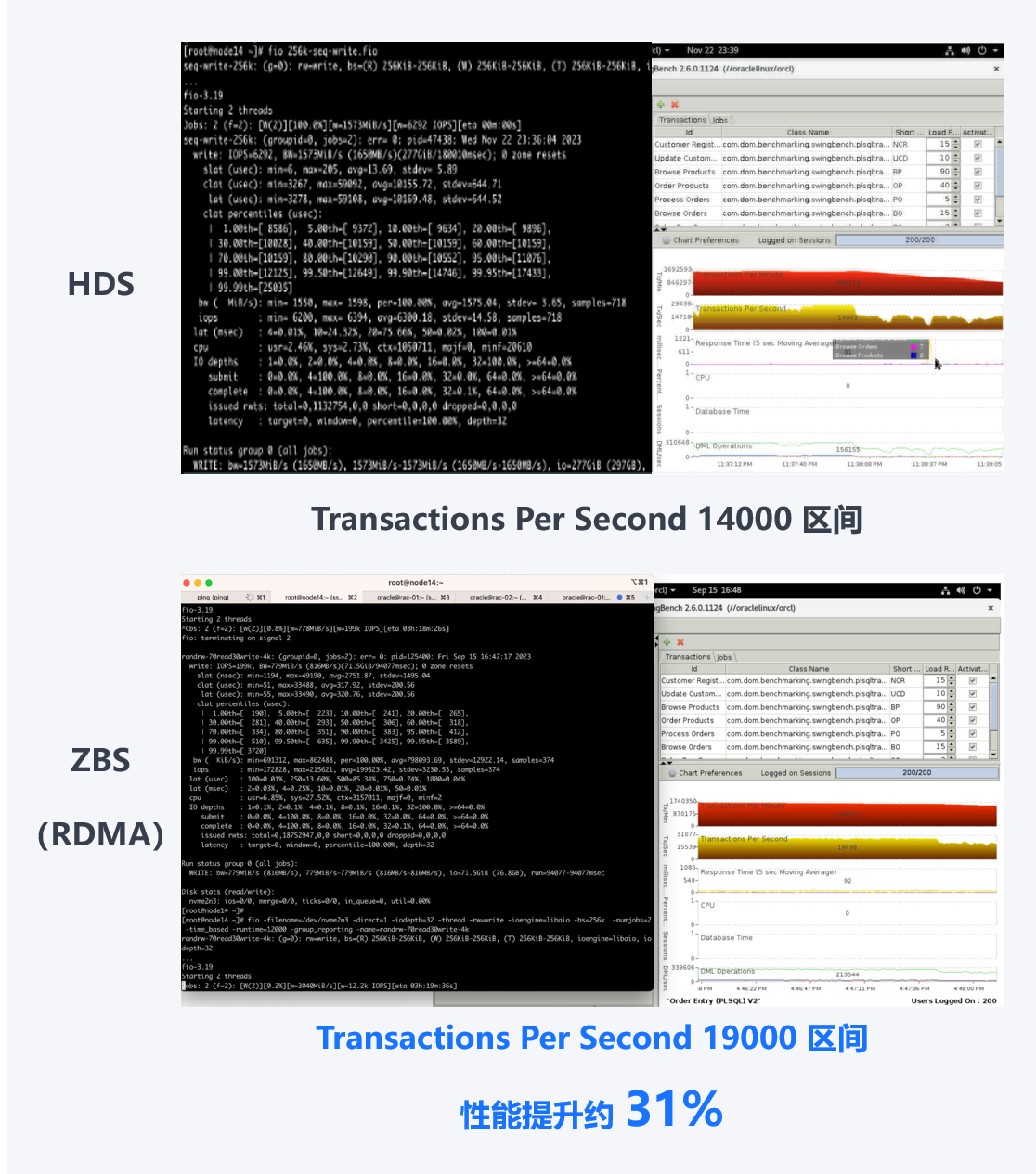
总体而言,ZBS(开启 RDMA)环境下 Oracle 数据库性能表现均优于 HDS 集中式存储环境,尤其是在 TPCC 测试中,相比 HDS,ZBS 可提升数据库性能约 30%,充分满足业务性能需求。
总结
整体而言,在存储基准场景和 Oracle 数据库场景下,ZBS 开启 RDMA 的性能和稳定性表现要优于 HDS 集中式存储,ZBS 优化的快照机制也可降低快照创建对性能带来的影响。
欲深入了解 ZBS 架构设计与技术创新,请阅读电子书《分布式存储 ZBS 的自主研发之旅》。
阅读原文:分布式存储与集中式存储(HDS)的性能对比
这篇关于性能实测:分布式存储 ZBS 与集中式存储 HDS 在 Oracle 数据库场景表现如何的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





