本文主要是介绍EMNLP 2023精选:Text-to-SQL任务的前沿进展(上篇)——正会论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导语
本文记录了今年的自然语言处理国际顶级会议EMNLP 2023中接收的所有与Text-to-SQL相关(通过搜索标题关键词查找得到,可能不全)的论文,共计12篇,包含5篇正会论文和7篇Findings论文,以下是对这些论文的略读,某几篇也有详细的笔记(见链接)。
| 序号 | 类型 | 标题 |
|---|---|---|
| 1 | Main | Benchmarking and Improving Text-to-SQL Generation under Ambiguity |
| 2 | Main | Evaluating Cross-Domain Text-to-SQL Models and Benchmarks |
| 3 | Main | Exploring Chain of Thought Style Prompting for Text-to-SQL |
| 4 | Main | Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations |
| 5 | Main | Non-Programmers Can Label Programs Indirectly via Active Examples: A Case Study with Text-to-SQL |
| 6 | Findings | Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison |
| 7 | Findings | Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies |
| 8 | Findings | Error Detection for Text-to-SQL Semantic Parsing |
| 9 | Findings | ReFSQL: A Retrieval-Augmentation Framework for Text-to-SQL Generation |
| 10 | Findings | Selective Demonstrations for Cross-domain Text-to-SQL |
| 11 | Findings | Semantic Decomposition of Question and SQL for Text-to-SQL Parsing |
| 12 | Findings | SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data |
由于篇数过多,分为两篇博客记录,本篇为第一篇,主要记录正会论文:
正会论文(Main Conference)
中稿的这5篇正会论文来看,主要还是围绕着Text-to-SQL的评测、实际系统交互和LLM在Text-to-SQL任务的应用为主。
Benchmarking and Improving Text-to-SQL Generation under Ambiguity
- 链接:https://arxiv.org/pdf/2310.13659v1.pdf
- 摘要:在文本到SQL转换的研究中,大多数基准测试都是针对每个文本查询对应一个正确的SQL的数据集。然而,现实生活中的数据库上的自然语言查询经常由于模式名称的重叠和多个令人困惑的关系路径,而涉及对预期SQL的显著歧义。为了弥合这一差距,我们开发了一个名为AmbiQT的新基准,其中包含超过3000个示例,每个文本都可以由于词汇和/或结构上的歧义而被解释为两个合理的SQL。 面对歧义时,理想的top-k解码器应该生成所有有效的解释,以便用户可能的消歧(Elgohary等,2021年;Zhong等,2022年)。我们评估了几个文本到SQL系统和解码算法,包括那些使用最先进的大型语言模型(LLMs)的系统,发现它们距离这一理想还很远。主要原因是流行的束搜索算法及其变体将SQL查询视为字符串,并在top-k中产生无益的令牌级别多样性。 我们提出了一种名为LogicalBeam的新解码算法,该算法使用基于计划的模板生成和受限填充的混合方法来导航SQL逻辑空间。逆向生成的计划使模板多样化,而仅在模式名称上分支的束搜索填充提供了值多样性。LogicalBeam在生成top-k排名输出中的所有候选SQL方面,比最先进的模型高出2.5倍的效果。它还提高了SPIDER和Kaggle DBQA上的前5名精确匹配和执行匹配准确率。
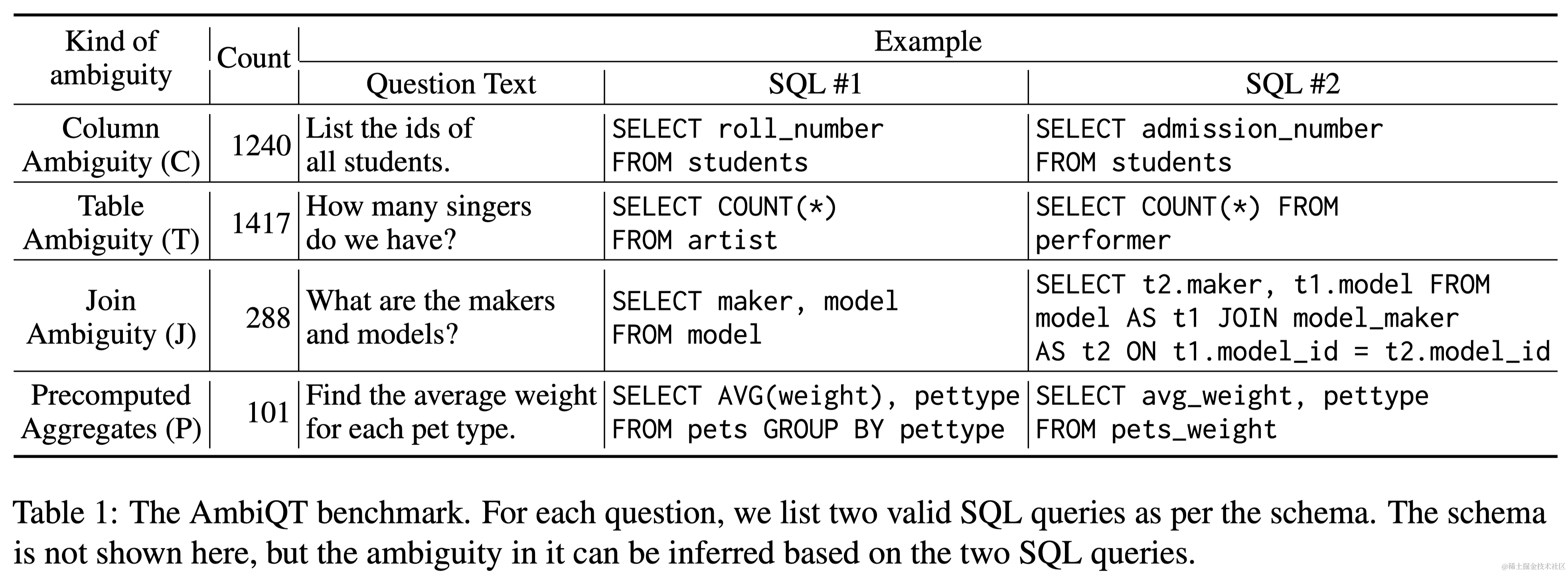
- 要点:主要关注于自然语言到SQL转换时的歧义现象,作者先是自己设计了一个评测基准AmbiQT,然后针对性设计了一种LogicalBeam的新解码算法,改善原有的beam-search带来的token-level的beam差异。
Evaluating Cross-Domain Text-to-SQL Models and Benchmarks
- 链接:https://arxiv.org/pdf/2310.18538v1.pdf
- 摘要:文本到SQL的基准测试在评估该领域的进展和不同模型的排名方面起着关键作用。然而,由于各种原因,比如自然语言查询的不明确、模型生成的查询和参考查询中固有的假设、以及在某些条件下SQL输出的非确定性特性,导致基准测试中模型生成的SQL查询与参考SQL查询的准确匹配失败。在本文中,我们对几个著名的跨领域文本到SQL基准测试进行了广泛的研究,并对这些基准测试中表现最佳的一些模型进行了重新评估,包括手动评估SQL查询和用等效表达式重写它们。我们的评估揭示,由于可以从提供的样本中得出多种解释,所以在这些基准测试中达到完美表现是不可行的。此外,我们发现这些模型的真实性能被低估了,而且在重新评估后它们的相对性能发生了变化。最值得注意的是,我们的评估揭示了一个令人惊讶的发现:在我们的人类评估中,一种基于最新GPT4模型的模型超越了Spider基准测试中的金标准参考查询。这一发现突显了谨慎解读基准测试评估的重要性,同时也认识到进行额外独立评估在推动该领域进步中的关键作用。

- 要点:主要讨论了现有Text-to-SQL评测基准中存在的语言不明确、数据值不明确等导致的评估标准失真的现象,作者对部分存在上述问题的Question-SQL Pair进行重写后对现有的一些SOTA模型进行了再评估。
Exploring Chain of Thought Style Prompting for Text-to-SQL
- 链接:https://arxiv.org/abs/2305.14215
- 摘要:使用大型语言模型(LLMs)进行上下文学习由于在各种任务上的卓越的少样本表现,近来引起了越来越多的关注。然而,其在文本到SQL解析上的表现仍有很大的提升空间。在本文中,我们假设改善LLMs在文本到SQL解析上的一个关键方面是其多步推理能力。因此,我们系统地研究了如何通过思维链(CoT)风格的提示来增强LLMs的推理能力,包括原始的思维链提示(Wei等,2022b)和最少到最多提示(Zhou等,2023)。我们的实验表明,像Zhou等(2023)中的迭代提示可能对文本到SQL解析来说并不必要,而使用详细的推理步骤往往会有更多的错误传播问题。基于这些发现,我们提出了一种新的CoT风格的提示方法,用于文本到SQL解析。与不带推理步骤的标准提示方法相比,它在Spider开发集和Spider真实集上分别带来了5.2和6.5点的绝对提升;与最少到最多提示方法相比,分别带来了2.4和1.5点的绝对提升。
- 要点:本文探索了应用LLM解决Text-to-SQL任务时的Prompt Engineering。作者设计了一种“问题分解”的Prompt格式并结合每个子问题中的表列名进行融合,实现了与RASAT+PICARD模型相当的表现。

- 笔记:Text-to-SQL任务中的思维链(Chain-of-thought)探索
Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations
- 链接:https://arxiv.org/abs/2305.07372
- 摘要:关系数据库在这个大数据时代扮演着重要角色。然而,对于非专家来说,由于他们不熟悉SQL等数据库语言,充分释放关系数据库的分析能力是具有挑战性的。虽然已经提出了许多技术来自动从自然语言生成SQL,但它们存在两个问题:(1)特别是对于复杂查询,它们仍然会犯许多错误,(2)它们没有为非专家用户提供一种灵活的方式来验证和修正错误的查询。为了解决这些问题,我们引入了一种新的交互机制,允许用户直接编辑不正确的SQL的逐步解释来修复SQL错误。在Spider基准测试上的实验表明,我们的方法在执行准确性方面至少比三种最先进的方法高出31.6%。另外,一项包括24名参与者的用户研究进一步表明,我们的方法帮助用户在更少的时间内以更高的信心解决了更多的SQL任务,展示了其拓宽数据库访问,特别是对于非专家的潜力。
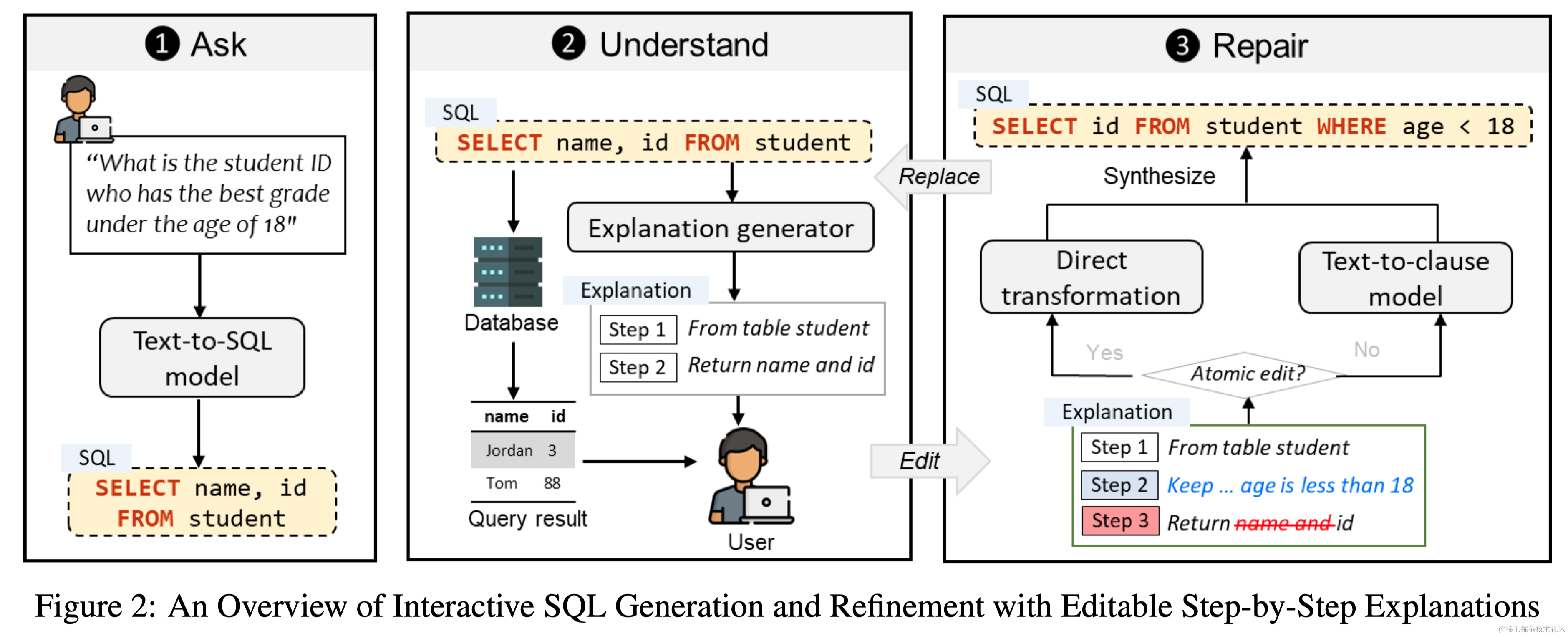
- 要点:提出了一个名为STEPS的交互式文本到SQL系统,允许用户通过直接编辑逐步解释来修正错误的SQL查询。Spider上实验显示,STEPS在提高任务完成速度、准确性和用户自信度方面相比现有方法有显著优势。
Non-Programmers Can Label Programs Indirectly via Active Examples: A Case Study with Text-to-SQL
- 链接:https://arxiv.org/abs/2205.12422
- 摘要:非程序员能否通过自然语言标注来间接地表示其含义的复杂程序?我们介绍了APEL框架,其中非程序员通过选择由种子语义解析器(例如Codex)生成的候选程序来进行标注。由于他们无法理解这些候选程序,我们要求他们通过检查程序的输入输出示例来间接选择。对于每个表达,APEL会主动搜索一个简单的输入,在此输入上候选程序倾向于产生不同的输出。然后,我们仅要求非程序员选择合适的输出,从而推断出哪个程序是正确的,并可以用来微调解析器。作为一个案例研究,我们招募了非程序员人类使用APEL重新标注SPIDER,一个文本到SQL数据集。我们的方法达到了与原始专家标注者相同的标注准确率(75%),并揭露了原始标注中的许多微妙错误。

- 要点:本文提出了APEL框架,使非程序员能通过选择候选程序的示例输出来注释文本到SQL的语义。这一方法在文本到SQL数据集SPIDER上达到了与专家相当的注释准确性,并揭示了原始注释中的一些错误。
这篇关于EMNLP 2023精选:Text-to-SQL任务的前沿进展(上篇)——正会论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








