本文主要是介绍编译原理本科课程 专题5 基于 SLR(1)分析的语义分析及中间代码生成程序设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、程序功能描述
本程序由C/C++编写,实现了赋值语句语法制导生成四元式,并完成了语法分析和语义分析过程。
以专题 1 词法分析程序的输出为语法分析的输入,完成以下描述赋值语句 SLR(1)文法的语义分析及中间代码四元式的过程,实现编译器前端。
G[S]: S→V=E
E→E+T∣E-T∣T
T→T*F∣T/F∣F
F→(E)∣i
V→i
二、主要数据结构描述
关于本程序的数据结构,首先用map存储了非终结符及终结符的编码映射,而后用string存储文件读入和写入的信息等,最重要的是利用vector二维数组实现了SLR分析表,用于存储分析动作;此外定义了四元组和栈的相应结构体。由于本人习惯,字符串处理总体上采用了C风格和C++方式并存的写法。
、程序结构描述
除main函数外,本程序共定义了4个函数:
getIndex用于返回输入字符在deCode 映射中的对应索引,若非法字符则返回-1。
dispQuad用于显示解析过程中生成的四元组,并展示输入表达式的中间代码表示;SLR_display则显示分析栈的当前状态、剩余的输入字符串以及解析过程中的当前动作。这两个函数都用于实现编译前端的可视化。
在SLR_analysis真正实现了SLR(1)文法的分析过程,使用栈 (anstk) 跟踪解析过程中的状态、符号和输入字符串位置,并根据 SLR 解析表执行移入、规约和接受等动作,最后在解析过程中生成四元组,表示中间代码。
四、程序测试
测试案例展示如下:
测试用例1:a=((b)+c*d)/f+e*g

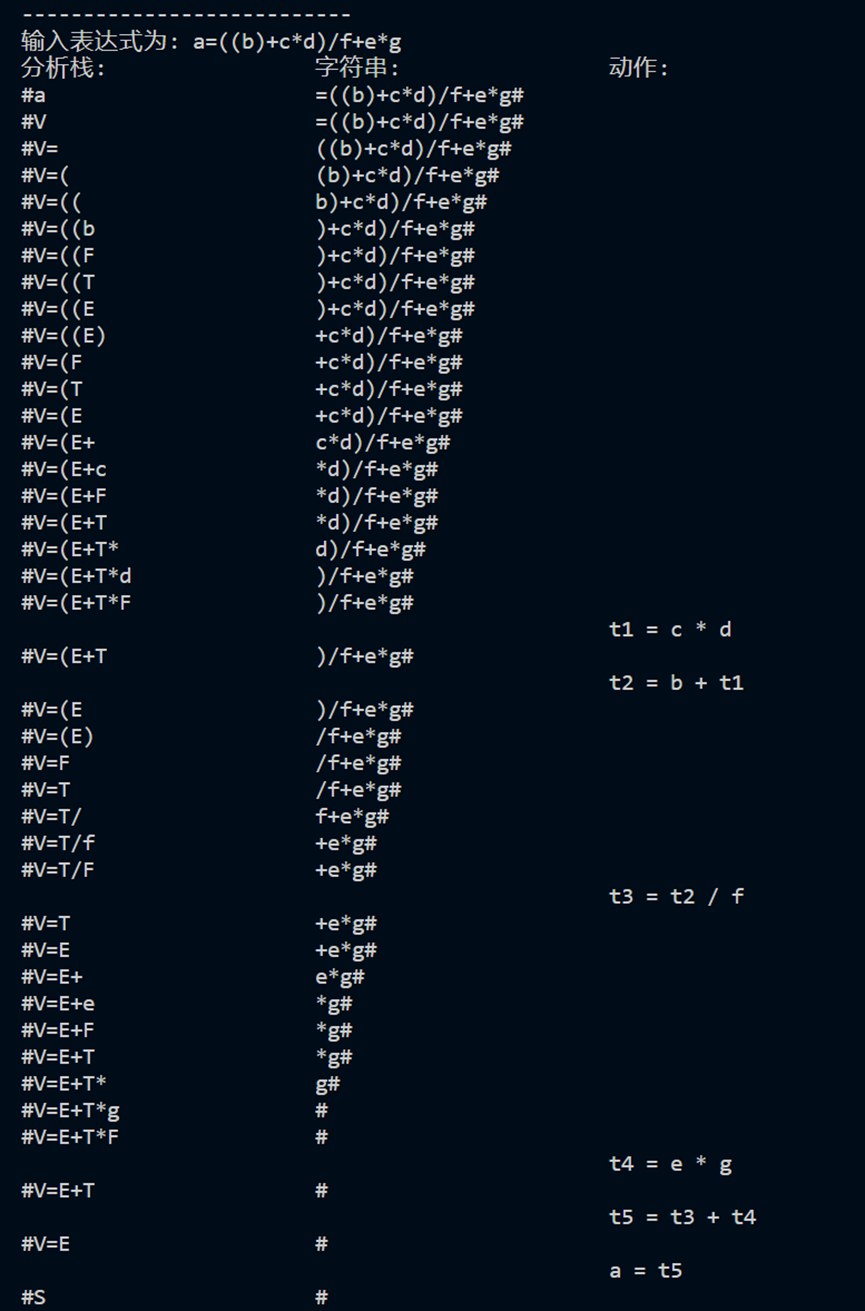

#include<iostream>
#include<cstring>
#include<string>
#include<vector>
#include<map>
using namespace std;
const int N=1024;
string testFileName = "test4.txt";
string info[3] = {"---------------------------", "SLR(1)分析", "---------------------------"};
map<char, int> deCode =
{{'i', 0},{'=', 1},{'+', 2},{'-', 3},{'*', 4},{'/', 5},{'(', 6},{')', 7},{'#', 8},{'S', 9},{'E', 10},{'T', 11},{'F', 12},{'V', 13},
};
vector<vector<int>>table = {{ 3, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 2},{ 0, 0, 0, 0, 0, 0, 0, 0,-11,0,0, 0, 0, 0},{ 0, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0},{-10,-10,-10,-10,-10,-10,-10,-10,-10, 0, 0, 0, 0, 0},{ 9, 0, 0, 0, 0, 0, 8, 0, 0, 0, 5, 6, 7, 0},{-1,-1,10,11,-1,-1,-1,-1,-1, 0, 0, 0, 0, 0},{-4,-4,-4,-4,12,13,-4,-4,-4, 0, 0, 0, 0, 0},{-7,-7,-7,-7,-7,-7,-7,-7,-7, 0, 0, 0, 0, 0},{ 9, 0, 0, 0, 0, 0, 8, 0, 0, 0,14, 6, 7, 0},{-9,-9,-9,-9,-9,-9,-9,-9,-9, 0, 0, 0, 0, 0},{ 9, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0,15, 7, 0},{ 9, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0,16, 7, 0},{ 9, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0,17, 0},{ 9, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0,18, 0},{ 0, 0,10,11, 0, 0, 0,19, 0, 0, 0, 0, 0, 0},{-2,-2,-2,-2,12,13,-2,-2,-2, 0, 0, 0, 0, 0},{-3,-3,-3,-3,12,13,-3,-3,-3, 0, 0, 0, 0, 0},{-5,-5,-5,-5,-5,-5,-5,-5,-5, 0, 0, 0, 0, 0},{-6,-6,-6,-6,-6,-6,-6,-6,-6, 0, 0, 0, 0, 0},{-8,-8,-8,-8,-8,-8,-8,-8,-8, 0, 0, 0, 0, 0}};struct quadruple {char op[N];char arg1[N];char arg2[N];char res[N];
};
struct quadruple quad[N];
int topOfQuad = 0; struct Stack {char s[N];int i[N];int space[N];int top;
}; int getIndex(char ch);
int SLR_analysis(char *str, struct Stack *anstk);
void SLR_display(char *str, struct Stack *anstk, int cur);
void dispQuad();int main() {for (int i = 0; i < 3; i++)cout << info[i] << endl;FILE *fp = fopen(testFileName.c_str(), "r");char buf[N] = "";char input[N] = "";fgets(buf, N, fp);int j = 0;for(int k = 0; k < strlen(buf); k++) { if(buf[k] == '1' && buf[k+1] == ',') {k += 3;while(1) {if(buf[k] == ')' && buf[k+1] == ' ')break;input[j++] = buf[k++];}continue;}if(buf[k] == ',' && buf[k+1] == ' ') {k += 2;while(1) {if(buf[k] == ')' && buf[k+1] == ' ')break;input[j++] = buf[k++];}}}printf("输入表达式为: %s\n", input); input[j] = '#'; fclose(fp);struct Stack *anstk;anstk = (struct Stack *)malloc(sizeof(struct Stack));anstk->s[0] = '#';anstk->i[0] = 0;anstk->space[0] = -1;anstk->top = 0; if(!SLR_analysis(input, anstk)) {cout << "语法错误!" << endl;}else {cout << "分析成功!" << endl;dispQuad(); }return 0;
}int getIndex(char ch) {if (deCode.find(ch) != deCode.end())return deCode[ch];elsereturn -1;
}void SLR_display(char *str, struct Stack *anstk, int cur) { for(int i = 0; i <= anstk->top; i++) {cout << anstk->s[i];}for(int i = 0; i < 3-(anstk->top+1)/8; i++) {cout<< "\t";}for(int i = cur; i < strlen(str); i++) {cout << str[i];}printf("\n");
}void dispQuad() { printf("四元式:\n");for(int i = 1; i <= topOfQuad; i++) {printf("(%s, %s, %s, %s)\n", quad[i].op, quad[i].arg1, quad[i].arg2, quad[i].res);}
}int SLR_analysis(char *str, struct Stack *anstk) { topOfQuad = 0;int i = 0;int next;printf("分析栈:\t\t\t字符串:\t\t\t动作:\n");while(i < strlen(str)) {if(anstk->top < 0) return 0; int y; if (str[i] >= 'a' && str[i] <= 'z') y = getIndex('i'); else y = getIndex(str[i]);if(y == -1 || table[anstk->i[anstk->top]][y] == 0) { return 0;}if(table[anstk->i[anstk->top]][y] > 0) { next = table[anstk->i[anstk->top]][y];anstk->top++;anstk->s[anstk->top] = str[i];anstk->i[anstk->top] = next;anstk->space[anstk->top] = i;i++;SLR_display(str, anstk, i);}else if(table[anstk->i[anstk->top]][y] < 0) { int tmp = -table[anstk->i[anstk->top]][y]; if(tmp == 4 || tmp == 7 || tmp == 9 || tmp == 10) {anstk->top--; }else if(tmp == 2 || tmp == 3 || tmp == 5 || tmp == 6){topOfQuad++;if(tmp == 2) strcpy(quad[topOfQuad].op, "+");else if(tmp == 3) strcpy(quad[topOfQuad].op, "-");else if(tmp == 5) strcpy(quad[topOfQuad].op, "*");else strcpy(quad[topOfQuad].op, "/");if(anstk->space[anstk->top - 2] < 0) sprintf(quad[topOfQuad].arg1, "t%d", -anstk->space[anstk->top - 2]);else {char arg1[2] = {str[anstk->space[anstk->top - 2]], '\0'};strcpy(quad[topOfQuad].arg1, arg1);}if(anstk->space[anstk->top] < 0) sprintf(quad[topOfQuad].arg2, "t%d", -anstk->space[anstk->top]);else {char arg2[2] = {str[anstk->space[anstk->top]], '\0'};strcpy(quad[topOfQuad].arg2, arg2);}cout << "\t\t\t\t\t\t";printf("t%d = %s %s %s\n", topOfQuad, quad[topOfQuad].arg1, quad[topOfQuad].op, quad[topOfQuad].arg2); sprintf(quad[topOfQuad].res, "t%d", topOfQuad);anstk->top -= 3; anstk->space[anstk->top + 1] = -topOfQuad; }else if(tmp == 8) {anstk->top -= 3; anstk->space[anstk->top + 1] = anstk->space[anstk->top + 2]; }else if(tmp == 1){topOfQuad++;strcpy(quad[topOfQuad].op, "=");if(anstk->space[anstk->top] < 0) sprintf(quad[topOfQuad].arg1, "t%d", abs(anstk->space[anstk->top]));else {char arg1[2] = {str[anstk->space[anstk->top]], '\0'};strcpy(quad[topOfQuad].arg1, arg1);}sprintf(quad[topOfQuad].arg2, " ");char res[2] = {str[anstk->space[anstk->top - 2]], '\0'};strcpy(quad[topOfQuad].res, res);cout << "\t\t\t\t\t\t";printf("%s = %s\n", quad[topOfQuad].res, quad[topOfQuad].arg1);anstk->top -= 3; }else anstk->top -= 3;if(tmp == 1) { y = getIndex('S');next = table[anstk->i[anstk->top]][y]; anstk->top++;anstk->s[anstk->top] = 'S';anstk->i[anstk->top] = next; }else if(tmp == 2 || tmp ==3 || tmp == 4) {y = getIndex('E');next = table[anstk->i[anstk->top]][y]; anstk->top++;anstk->s[anstk->top] = 'E';anstk->i[anstk->top] = next;}else if(tmp == 5 || tmp == 6 || tmp == 7) {y = getIndex('T');next = table[anstk->i[anstk->top]][y];anstk->top++;anstk->s[anstk->top] = 'T';anstk->i[anstk->top] = next;}else if(tmp == 8 || tmp == 9) {y = getIndex('F');next = table[anstk->i[anstk->top]][y];anstk->top++;anstk->s[anstk->top] = 'F';anstk->i[anstk->top] = next;}else if(tmp == 10) {y = getIndex('V');next = table[anstk->i[anstk->top]][y];anstk->top++;anstk->s[anstk->top] = 'V';anstk->i[anstk->top] = next;}else if(tmp == 11) {return 1; }SLR_display(str, anstk, i);}}return 0;
}这篇关于编译原理本科课程 专题5 基于 SLR(1)分析的语义分析及中间代码生成程序设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









