本文主要是介绍Python3 爬虫实战 — 前程无忧招聘信息爬取 + 数据可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 爬取时间:2020-07-11(2020年10月测试,增加了反爬,此代码已失效!!!)
- 实现目标:根据用户输入的关键字爬取相关职位信息存入 MongoDB,读取数据进行可视化展示。
- 涉及知识:请求库 requests、Xpath 语法、数据库 MongoDB、数据处理 Numpy、Pandas、数据可视化 Matplotlib。
- 完整代码:https://github.com/TRHX/Python3-Spider-Practice/tree/master/SpiderDataVisualization/51job
- 其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
- 爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
文章目录
- 【1x00】获取数据 get_51job_data.py
- 【01x01】构建请求地址
- 【01x02】获取总页数
- 【01x03】提取详情页 URL
- 【01x04】提取职位信息
- 【01x05】保存数据到 MongoDB
- 【2x00】数据可视化 draw_bar_chart.py
- 【02x01】数据初处理
- 【02x02】数据清洗
- 【02x03】绘制经验与平均薪资关系图
- 【02x04】绘制学历与平均薪资关系图
- 【3x00】数据截图
- 【4x00】完整代码
【1x00】获取数据 get_51job_data.py
【01x01】构建请求地址
以 Python 职位为例,请求地址如下:
第一页:https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html
第二页:https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,2.html
第三页:https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,3.html
初始化函数:
def __init__(self):self.base_url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,%s,2,%s.html'self.headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.13 Safari/537.36'}self.keyword = input('请输入关键字:')
【01x02】获取总页数
在页面的下方给出了该职位一共有多少页,使用 Xpath 和正则表达式提取里面的数字,方便后面翻页爬取使用,注意页面编码为 gbk。
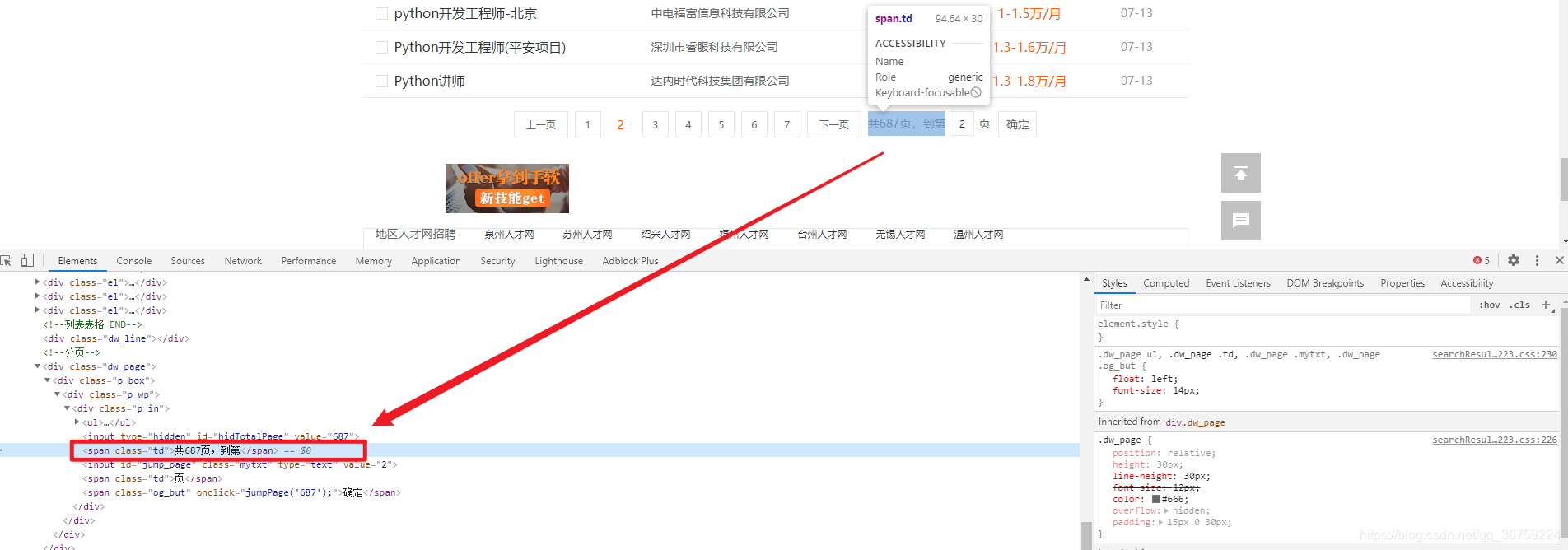
def tatal_url(self):url = self.base_url % (self.keyword, str(1))response = requests.get(url=url, headers=self.headers)tree = etree.HTML(response.content.decode('gbk'))# 提取一共有多少页text = tree.xpath("//div[@class='p_in']/span[1]/text()")[0]number = re.findall('[0-9]', text)number = int(''.join(number))print('%s职位共有%d页' % (self.keyword, number))return number
【01x03】提取详情页 URL
定义一个 detail_url() 方法,传入总页数,循环提取每一页职位详情页的 URL,将每一个详情页 URL 传递给 parse_data() 方法,用于解析详情页内的具体职位信息。
提取详情页时有以下几种特殊情况:
特殊情况一:如果有前程无忧自己公司的职位招聘信息掺杂在里面,他的详情页结构和普通的不一样,页面编码也有差别。
页面示例:https://51rz.51job.com/job.html?jobid=115980776
页面真实数据请求地址类似于:https://coapi.51job.com/job_detail.php?jsoncallback=&key=&sign=params={“jobid”:""}
请求地址中的各参数值通过 js 加密:https://js.51jobcdn.com/in/js/2018/coapi/coapi.min.js

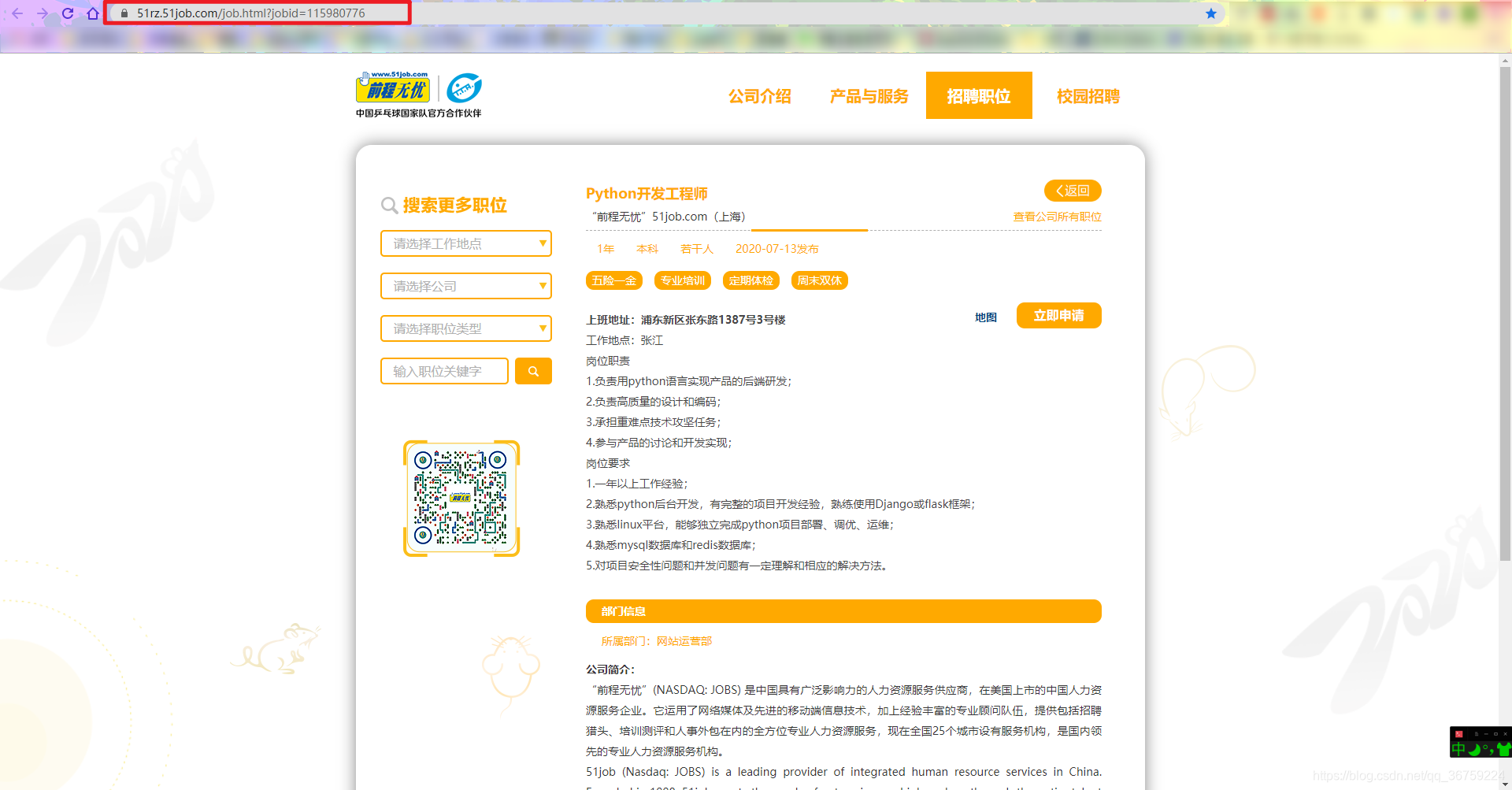
特殊情况二:部分公司有自己的专属页面,此类页面的结构也不同于普通页面
页面示例:http://dali.51ideal.com/jobdetail.html?jobid=121746338


为了规范化,本次爬取将去掉这部分特殊页面,仅爬取 URL 带有 jobs.51job.com 的数据
def detail_url(self, number):for num in range(1, number+1):url = self.base_url % (self.keyword, str(num))response = requests.get(url=url, headers=self.headers)tree = etree.HTML(response.content.decode('gbk'))detail_url1 = tree.xpath("//div[@class='dw_table']/div[@class='el']/p/span/a/@href")"""深拷贝一个 url 列表,如果有连续的不满足要求的链接,若直接在原列表里面删除,则会漏掉一些链接,因为每次删除后的索引已改变,因此在原列表中提取不符合元素后,在深拷贝的列表里面进行删除。最后深拷贝的列表里面的元素均符合要求。"""detail_url2 = copy.deepcopy(detail_url1)for url in detail_url1:if 'jobs.51job.com' not in url:detail_url2.remove(url)self.parse_data(detail_url2)print('第%d页数据爬取完毕!' % num)time.sleep(2)print('所有数据爬取完毕!')
【01x04】提取职位信息
解析详情页时页面编码是 gbk,但是某些页面在解析时仍然会报编码错误,因此使用 try-except 语句捕捉编码错误(UnicodeDecodeError),如果该页面有编码错误则直接 return 结束函数。
def parse_data(self, urls):"""position: 职位wages: 工资region: 地区experience: 经验education: 学历need_people: 招聘人数publish_date: 发布时间english: 英语要求welfare_tags: 福利标签job_information: 职位信息work_address: 上班地址company_name: 公司名称company_nature: 公司性质company_scale: 公司规模company_industry: 公司行业company_information: 公司信息"""for url in urls:response = requests.get(url=url, headers=self.headers)try:text = response.content.decode('gbk')except UnicodeDecodeError:returntree = etree.HTML(text)"""提取内容时使用 join 方法将列表转为字符串,而不是直接使用索引取值,这样做的好处是遇到某些没有的信息直接留空而不会报错"""position = ''.join(tree.xpath("//div[@class='cn']/h1/text()"))wages = ''.join(tree.xpath("//div[@class='cn']/strong/text()"))# 经验、学历、招聘人数、发布时间等信息都在一个标签里面,逐一使用列表解析式提取content = tree.xpath("//div[@class='cn']/p[2]/text()")content = [i.strip() for i in content]if content:region = content[0]else:region = ''experience = ''.join([i for i in content if '经验' in i])education = ''.join([i for i in content if i in '本科大专应届生在校生硕士'])need_people = ''.join([i for i in content if '招' in i])publish_date = ''.join([i for i in content if '发布' in i])english = ''.join([i for i in content if '英语' in i])welfare_tags = ','.join(tree.xpath("//div[@class='jtag']/div//text()")[1:-2])job_information = ''.join(tree.xpath("//div[@class='bmsg job_msg inbox']/p//text()")).replace(' ', '')work_address = ''.join(tree.xpath("//div[@class='bmsg inbox']/p//text()"))company_name = ''.join(tree.xpath("//div[@class='tCompany_sidebar']/div[1]/div[1]/a/p/text()"))company_nature = ''.join(tree.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[1]//text()"))company_scale = ''.join(tree.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[2]//text()"))company_industry = ''.join(tree.xpath("//div[@class='tCompany_sidebar']/div[1]/div[2]/p[3]/@title"))company_information = ''.join(tree.xpath("//div[@class='tmsg inbox']/text()"))job_data = [position, wages, region, experience, education, need_people, publish_date,english, welfare_tags, job_information, work_address, company_name,company_nature, company_scale, company_industry, company_information]save_mongodb(job_data)
【01x05】保存数据到 MongoDB
指定一个名为 job51_spider 的数据库和一个名为 data 的集合,依次将信息保存至 MongoDB。
def save_mongodb(data):client = pymongo.MongoClient(host='localhost', port=27017)db = client.job51_spidercollection = db.datasave_data = {'职位': data[0],'工资': data[1],'地区': data[2],'经验': data[3],'学历': data[4],'招聘人数': data[5],'发布时间': data[6],'英语要求': data[7],'福利标签': data[8],'职位信息': data[9],'上班地址': data[10],'公司名称': data[11],'公司性质': data[12],'公司规模': data[13],'公司行业': data[14],'公司信息': data[15]}collection.insert_one(save_data)
【2x00】数据可视化 draw_bar_chart.py
【02x01】数据初处理
从 MongoDB 里面读取数据为 DataFrame 对象,本次可视化只分析工资与经验、学历的关系,所以只取这三项,由于获取的数据有些是空白值,因此使用 replace 方法将空白值替换成缺失值(NaN),然后使用 DataFrame 对象的 dropna() 方法删除带有缺失值(NaN)的行。将工资使用 apply 方法,将每个值应用于 wish_data 方法,即对每个值进行清洗。
def processing_data():# 连接数据库,从数据库读取数据(也可以导出后从文件中读取)client = pymongo.MongoClient(host='localhost', port=27017)db = client.job51_spidercollection = db.data# 读取数据并转换为 DataFrame 对象data = pd.DataFrame(list(collection.find()))data = data[['工资', '经验', '学历']]# 使用正则表达式选择空白的字段并填充为缺失值,然后删除带有缺失值的所有行data.replace(to_replace=r'^\s*$', value=np.nan, regex=True, inplace=True)data = data.dropna()# 对工资数据进行清洗,处理后的工作单位:元/月data['工资'] = data['工资'].apply(wish_data)return data
【02x02】数据清洗
def wish_data(wages_old):"""数据清洗规则:分为元/天,千(以上/下)/月,万(以上/下)/月,万(以上/下)/年若数据是一个区间的,则求其平均值,最后的值统一单位为元/月"""if '元/天' in wages_old:if '-' in wages_old.split('元')[0]:wages1 = wages_old.split('元')[0].split('-')[0]wages2 = wages_old.split('元')[0].split('-')[1]wages_new = (float(wages2) + float(wages1)) / 2 * 30else:wages_new = float(wages_old.split('元')[0]) * 30return wages_newelif '千/月' in wages_old or '千以下/月' in wages_old or '千以上/月' in wages_old:if '-' in wages_old.split('千')[0]:wages1 = wages_old.split('千')[0].split('-')[0]wages2 = wages_old.split('千')[0].split('-')[1]wages_new = (float(wages2) + float(wages1)) / 2 * 1000else:wages_new = float(wages_old.split('千')[0]) * 1000return wages_newelif '万/月' in wages_old or '万以下/月' in wages_old or '万以上/月' in wages_old:if '-' in wages_old.split('万')[0]:wages1 = wages_old.split('万')[0].split('-')[0]wages2 = wages_old.split('万')[0].split('-')[1]wages_new = (float(wages2) + float(wages1)) / 2 * 10000else:wages_new = float(wages_old.split('万')[0]) * 10000return wages_newelif '万/年' in wages_old or '万以下/年' in wages_old or '万以上/年' in wages_old:if '-' in wages_old.split('万')[0]:wages1 = wages_old.split('万')[0].split('-')[0]wages2 = wages_old.split('万')[0].split('-')[1]wages_new = (float(wages2) + float(wages1)) / 2 * 10000 / 12else:wages_new = float(wages_old.split('万')[0]) * 10000 / 12return wages_new
【02x03】绘制经验与平均薪资关系图
def wages_experience_chart(data):# 根据经验分类,求不同经验对应的平均薪资wages_experience = data.groupby('经验').mean()# 获取经验和薪资的值,将其作为画图的 x 和 y 数据w = wages_experience['工资'].index.valuese = wages_experience['工资'].values# 按照经验对数据重新进行排序,薪资转为 int 类型(也可以直接在前面对 DataFrame 按照薪资大小排序)wages = [w[6], w[1], w[2], w[3], w[4], w[5], w[0]]experience = [int(e[6]), int(e[1]), int(e[2]), int(e[3]), int(e[4]), int(e[5]), int(e[0])]# 绘制柱状图plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.figure(figsize=(9, 6))x = wagesy = experiencecolor = ['#E41A1C', '#377EB8', '#4DAF4A', '#984EA3', '#FF7F00', '#FFFF33', '#A65628']plt.bar(x, y, color=color)for a, b in zip(x, y):plt.text(a, b, b, ha='center', va='bottom')plt.title('Python 相关职位经验与平均薪资关系', fontsize=13)plt.xlabel('经验', fontsize=13)plt.ylabel('平均薪资(元 / 月)', fontsize=13)plt.savefig('wages_experience_chart.png')plt.show()

【02x04】绘制学历与平均薪资关系图
def wages_education_chart(data):# 根据学历分类,求不同学历对应的平均薪资wages_education = data.groupby('学历').mean()# 获取学历和薪资的值,将其作为画图的 x 和 y 数据wages = wages_education['工资'].index.valueseducation = [int(i) for i in wages_education['工资'].values]# 绘制柱状图plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.figure(figsize=(9, 6))x = wagesy = educationcolor = ['#E41A1C', '#377EB8', '#4DAF4A']plt.bar(x, y, color=color)for a, b in zip(x, y):plt.text(a, b, b, ha='center', va='bottom')plt.title('Python 相关职位学历与平均薪资关系', fontsize=13)plt.xlabel('学历', fontsize=13)plt.ylabel('平均薪资(元 / 月)', fontsize=13)plt.savefig('wages_education_chart.png')plt.show()

【3x00】数据截图
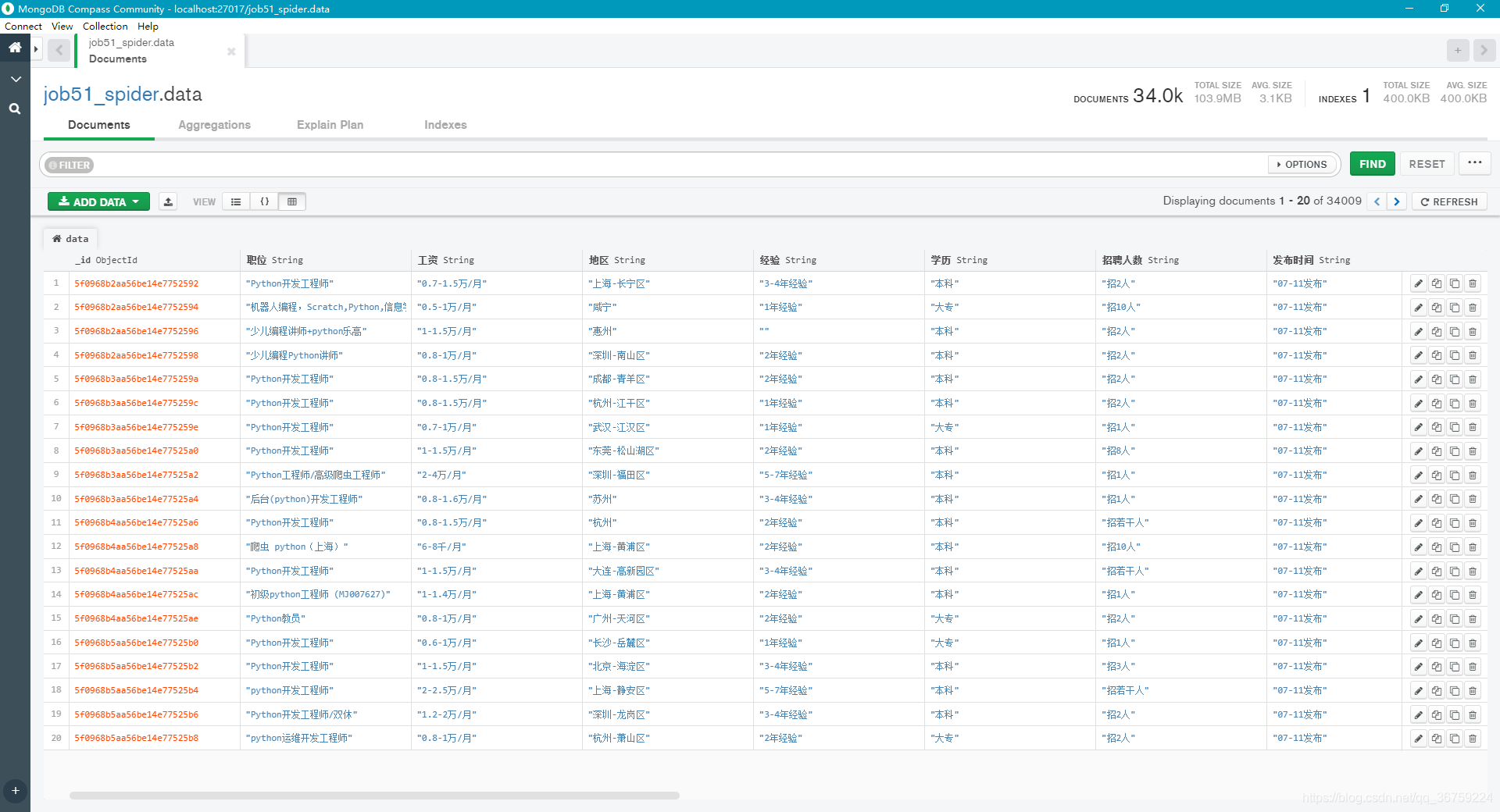
一共有 34009 条数据,完整数据已放在 github,可自行下载。
MongoDB:
CSV 文件:

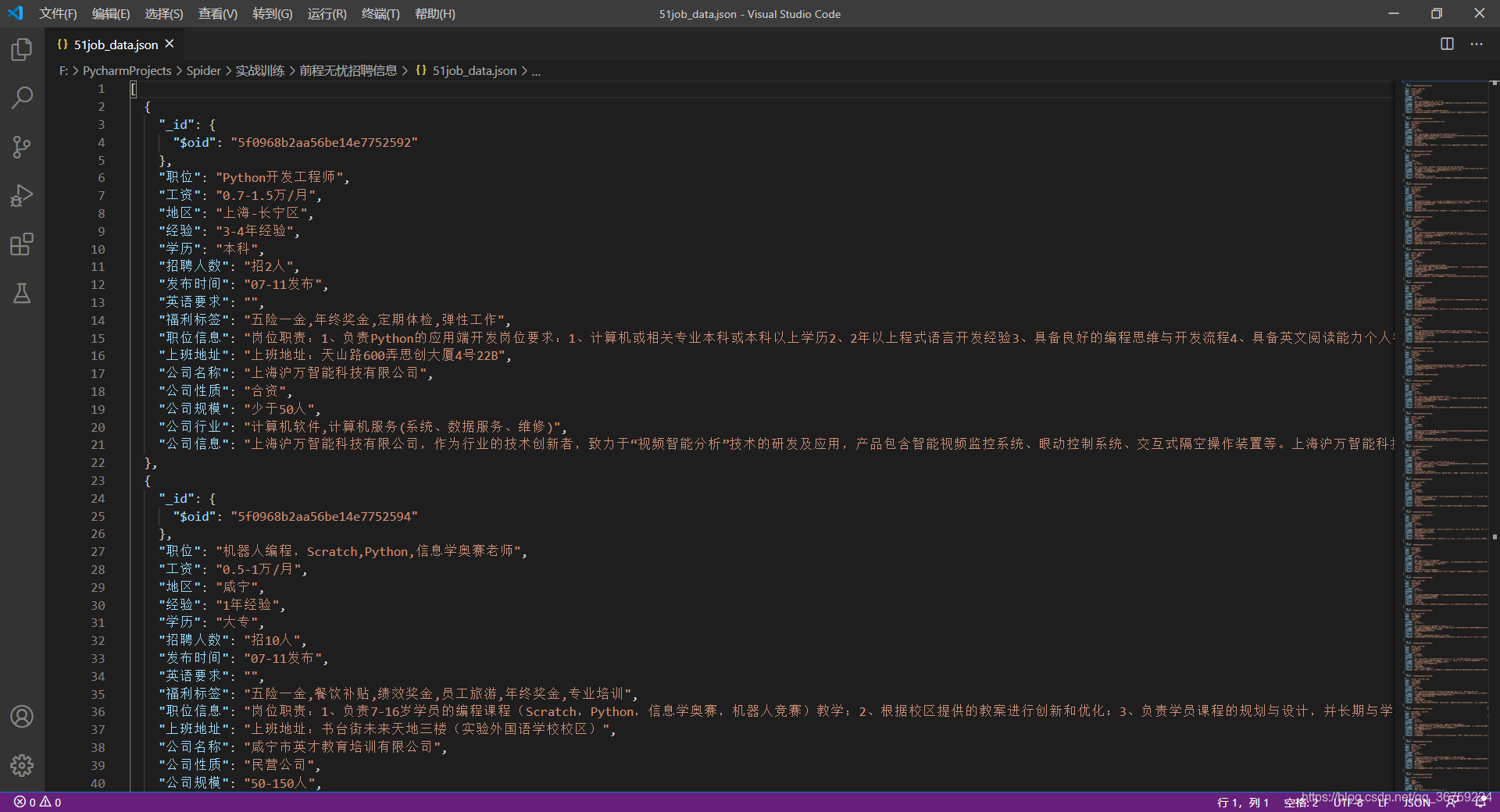
JSON 文件:
【4x00】完整代码
完整代码地址(点亮 star 有 buff 加成):https://github.com/TRHX/Python3-Spider-Practice/tree/master/SpiderDataVisualization/51job
其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
这篇关于Python3 爬虫实战 — 前程无忧招聘信息爬取 + 数据可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





