本文主要是介绍Elasticsearch:使用 Inference API 进行语义搜索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在我之前的文章 “Elastic Search 8.12:让 Lucene 更快,让开发人员更快”,我有提到 Inference API。这些功能的核心部分始终是灵活的第三方模型管理,使客户能够利用当今市场上下载最多的向量数据库及其选择的转换器模型。在今天的文章中,我们将使用一个例子来展示如何使用 Inference API 来进行语义搜索。
前提条件
- 你需要安装 Elastic Stack 8.12 及以上版本。你可以是自托管的 Elasticsearch 集群或者是在 Elastic Cloud 上的部署
- 由于 OpenAI 免费试用 API 的使用受到限制,因此需要付费 OpenAI 帐户才能将推理 API 与 OpenAI 服务结合使用。
在今天的展示中,我将使用自己在电脑上搭建的 Elasticsearch 集群来进行展示。安装版本是 Elastic Stack 8.12。
安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,我们可以选择 Elastic Stack 8.x 的安装指南来进行安装。在本博文中,我将使用最新的 Elastic Stack 8.10 来进行展示。
在安装 Elasticsearch 的过程中,我们需要记下如下的信息:

拷贝证书到当前工作目录
在客户端连接到 Elasticsearch 时,我们需要 Elasticsearch 的安装证书:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt安装需要的 Python 包
pip3 install elasticsearch load_dotenv$ pip3 install elasticsearch
Looking in indexes: http://mirrors.aliyun.com/pypi/simple/
Requirement already satisfied: elasticsearch in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (8.12.0)
Requirement already satisfied: elastic-transport<9,>=8 in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elasticsearch) (8.10.0)
Requirement already satisfied: urllib3<3,>=1.26.2 in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elastic-transport<9,>=8->elasticsearch) (2.1.0)
Requirement already satisfied: certifi in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elastic-transport<9,>=8->elasticsearch) (2023.11.17)[notice] A new release of pip is available: 23.3.2 -> 24.0
[notice] To update, run: pip3 install --upgrade pip
$ pip3 list | grep elasticsearch
elasticsearch 8.12.0
rag-elasticsearch 0.0.1 /Users/liuxg/python/rag-elasticsearch/my-app/packages/rag-elasticsearch设置环境变量
我们在 termnial 中打入如下的命令来设置环境变量:
export ES_USER=elastic
export ES_PASSWORD=xnLj56lTrH98Lf_6n76y
export OPENAI_API_KEY=YourOpenAIkey你需要根据自己的 Elasticsearch 配置及 OpenAI key 进行上面的修改。你需要在启动下面的 jupyter 之前运行上面的命令。
创建数据集
我们在当前的目录下创建如下的一个数据集:
movies.json
[{"title": "Pulp Fiction","runtime": "154","plot": "The lives of two mob hitmen, a boxer, a gangster and his wife, and a pair of diner bandits intertwine in four tales of violence and redemption.","keyScene": "John Travolta is forced to inject adrenaline directly into Uma Thurman's heart after she overdoses on heroin.","genre": "Crime, Drama","released": "1994"},{"title": "The Dark Knight","runtime": "152","plot": "When the menace known as the Joker wreaks havoc and chaos on the people of Gotham, Batman must accept one of the greatest psychological and physical tests of his ability to fight injustice.","keyScene": "Batman angrily responds 'I’m Batman' when asked who he is by Falcone.","genre": "Action, Crime, Drama, Thriller","released": "2008"},{"title": "Fight Club","runtime": "139","plot": "An insomniac office worker and a devil-may-care soapmaker form an underground fight club that evolves into something much, much more.","keyScene": "Brad Pitt explains the rules of Fight Club to Edward Norton. The first rule of Fight Club is: You do not talk about Fight Club. The second rule of Fight Club is: You do not talk about Fight Club.","genre": "Drama","released": "1999"},{"title": "Inception","runtime": "148","plot": "A thief who steals corporate secrets through the use of dream-sharing technology is given the inverse task of planting an idea into thed of a C.E.O.","keyScene": "Leonardo DiCaprio explains the concept of inception to Ellen Page by using a child's spinning top.","genre": "Action, Adventure, Sci-Fi, Thriller","released": "2010"},{"title": "The Matrix","runtime": "136","plot": "A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.","keyScene": "Red pill or blue pill? Morpheus offers Neo a choice between the red pill, which will allow him to learn the truth about the Matrix, or the blue pill, which will return him to his former life.","genre": "Action, Sci-Fi","released": "1999"},{"title": "The Shawshank Redemption","runtime": "142","plot": "Two imprisoned men bond over a number of years, finding solace and eventual redemption through acts of common decency.","keyScene": "Andy Dufresne escapes from Shawshank prison by crawling through a sewer pipe.","genre": "Drama","released": "1994"},{"title": "Goodfellas","runtime": "146","plot": "The story of Henry Hill and his life in the mob, covering his relationship with his wife Karen Hill and his mob partners Jimmy Conway and Tommy DeVito in the Italian-American crime syndicate.","keyScene": "Joe Pesci's character Tommy DeVito shoots young Spider in the foot for not getting him a drink.","genre": "Biography, Crime, Drama","released": "1990"},{"title": "Se7en","runtime": "127","plot": "Two detectives, a rookie and a veteran, hunt a serial killer who uses the seven deadly sins as his motives.","keyScene": "Brad Pitt's character David Mills shoots John Doe after he reveals that he murdered Mills' wife.","genre": "Crime, Drama, Mystery, Thriller","released": "1995"},{"title": "The Silence of the Lambs","runtime": "118","plot": "A young F.B.I. cadet must receive the help of an incarcerated and manipulative cannibal killer to help catch another serial killer, a madman who skins his victims.","keyScene": "Hannibal Lecter explains to Clarice Starling that he ate a census taker's liver with some fava beans and a nice Chianti.","genre": "Crime, Drama, Thriller","released": "1991"},{"title": "The Godfather","runtime": "175","plot": "An organized crime dynasty's aging patriarch transfers control of his clandestine empire to his reluctant son.","keyScene": "James Caan's character Sonny Corleone is shot to death at a toll booth by a number of machine gun toting enemies.","genre": "Crime, Drama","released": "1972"},{"title": "The Departed","runtime": "151","plot": "An undercover cop and a mole in the police attempt to identify each other while infiltrating an Irish gang in South Boston.","keyScene": "Leonardo DiCaprio's character Billy Costigan is shot to death by Matt Damon's character Colin Sullivan.","genre": "Crime, Drama, Thriller","released": "2006"},{"title": "The Usual Suspects","runtime": "106","plot": "A sole survivor tells of the twisty events leading up to a horrific gun battle on a boat, which began when five criminals met at a seemingly random police lineup.","keyScene": "Kevin Spacey's character Verbal Kint is revealed to be the mastermind behind the crime, when his limp disappears as he walks away from the police station.","genre": "Crime, Mystery, Thriller","released": "1995"}
]$ pwd
/Users/liuxg/python/elser
$ ls movies.json
movies.json应用设计
我们在当前的目录下打入如下的命令来启动 jupyter:
jupyter notebook导入所需要的包
from elasticsearch import Elasticsearch, helpers, exceptions
import json
import time,os
from dotenv import load_dotenvload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')url = f"https://{elastic_user}:{elastic_password}@localhost:9200"
client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)print(client.info())
从上面的输出中,我们可以看出来我们的 client 连接是成功的。更多关于如何连接到 Elasticsearch 的方法,请详细阅读文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。
创建 inference 任务
让我们使用 create inference API 创建推理任务。
为此,你i需要一个 OpenAI API 密钥,你可以在 OpenAI 帐户的 API 密钥部分下找到该密钥。 由于 OpenAI 免费试用 API 的使用受到限制,因此需要付费会员才能完成本笔记本中的步骤。
client.inference.put_model(task_type="text_embedding",model_id="my_openai_embedding_model",body={"service": "openai","service_settings": {"api_key": openai_api_key},"task_settings": {"model": "text-embedding-ada-002"}}
)
使用推理处理器创建摄取管道
使用 put_pipeline 方法创建带有推理处理器的摄取管道。 参考上面创建的 OpenAI 模型来推断管道中正在摄取的数据。
client.ingest.put_pipeline(id="openai_embeddings_pipeline", description="Ingest pipeline for OpenAI inference.",processors=[{"inference": {"model_id": "my_openai_embedding_model","input_output": {"input_field": "plot","output_field": "plot_embedding"}}}]
)
让我们记下该 API 调用中的一些重要参数:
- inference:使用机器学习模型执行推理的处理器。
- model_id:指定要使用的机器学习模型的ID。 在此示例中,模型 ID 设置为 my_openai_embedding_model。 使用你在创建推理任务时定义的模型 ID。
- input_output:指定输入和输出字段。
- input_field:创建密集向量表示的字段名称。
- output_field:包含推理结果的字段名称。
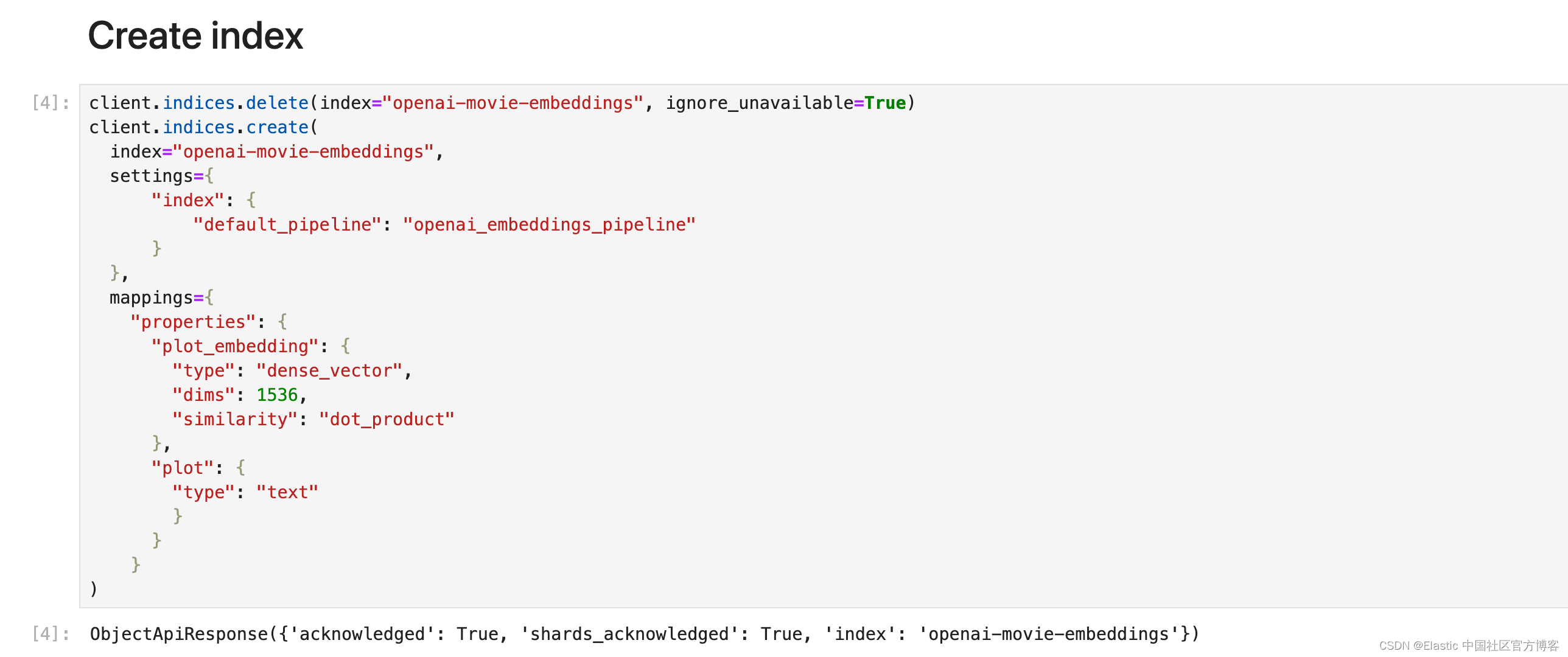
创建索引
必须创建目标索引的映射(包含模型将根据你的输入文本创建的嵌入的索引)。 目标索引必须具有 dense_vector 字段类型的字段,以索引 OpenAI 模型的输出。
让我们使用我们需要的映射创建一个名为 openai-movie-embeddings 的索引。
client.indices.delete(index="openai-movie-embeddings", ignore_unavailable=True)
client.indices.create(index="openai-movie-embeddings",settings={"index": {"default_pipeline": "openai_embeddings_pipeline"}},mappings={"properties": {"plot_embedding": { "type": "dense_vector", "dims": 1536, "similarity": "dot_product" },"plot": {"type": "text"}}}
)
插入文档
让我们插入 12 部电影的示例数据集。 你需要一个付费的 OpenAI 帐户才能完成此步骤,否则文档提取将由于 API 请求速率限制而超时。
from elasticsearch import helperswith open('movies.json') as f:data_json = json.load(f)# Prepare the documents to be indexed
documents = []
for doc in data_json:documents.append({"_index": "openai-movie-embeddings","_source": doc,})# Use helpers.bulk to index
helpers.bulk(client, documents)print("Done indexing documents into `openai-movie-embeddings` index!")
time.sleep(3)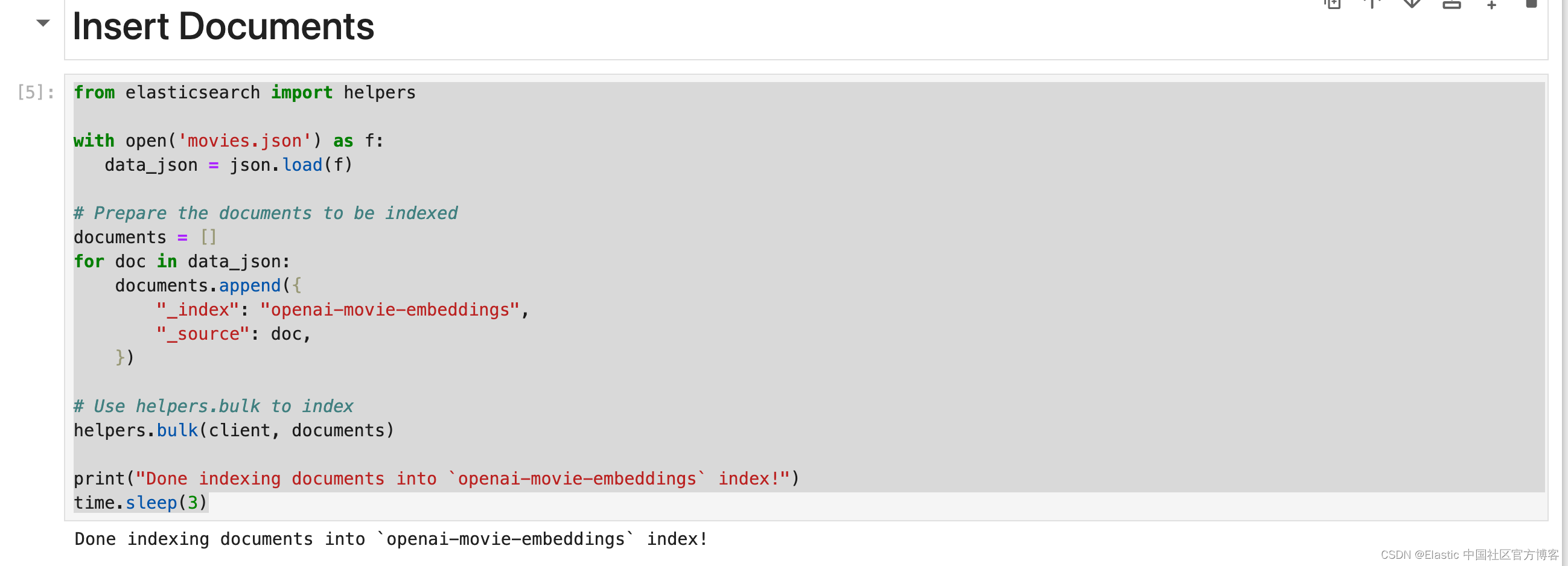
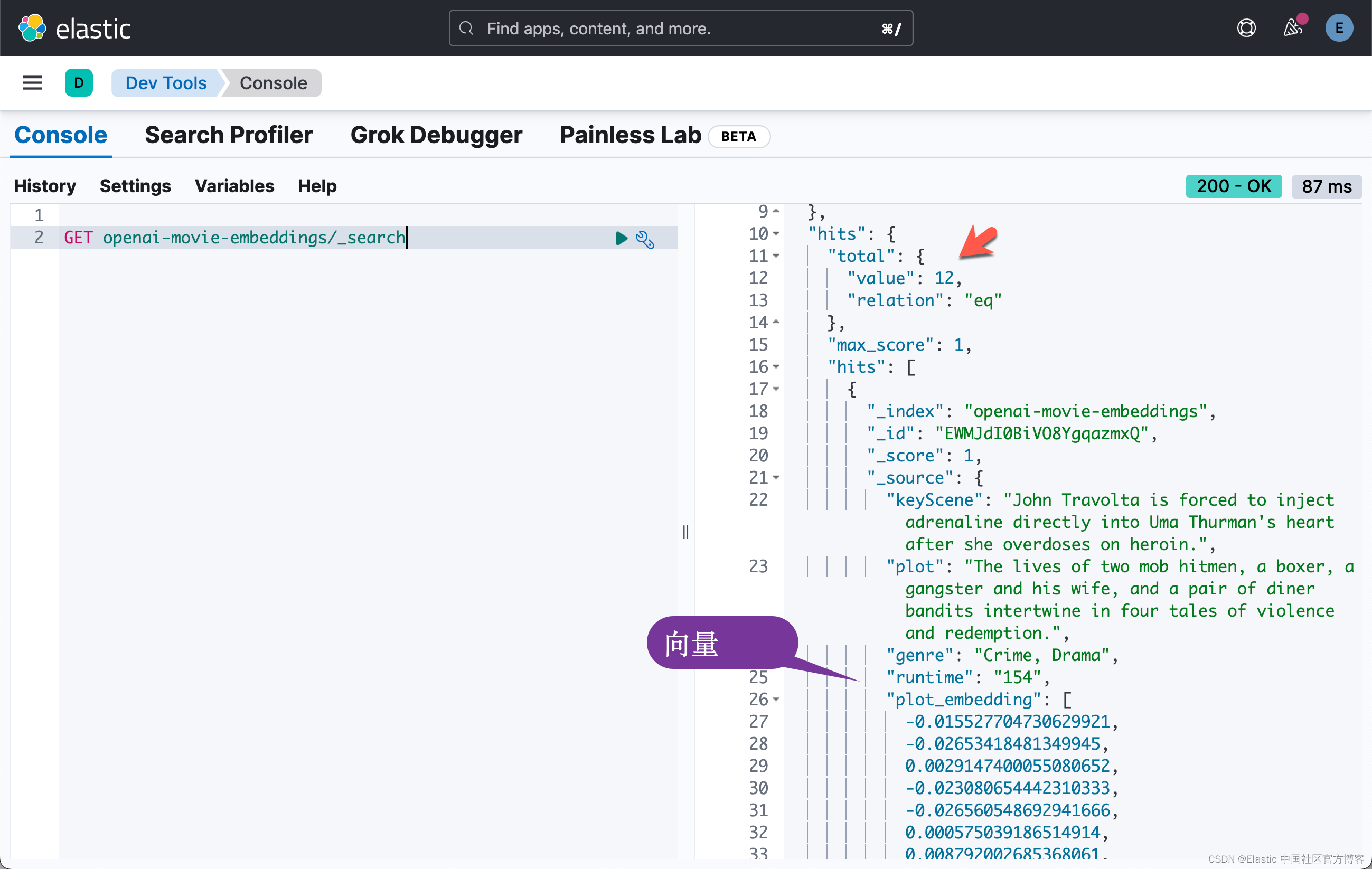
我们可以到 Kibana 中进行查看:
语义搜索
使用嵌入丰富数据集后,你可以使用语义搜索来查询数据。 将 query_vector_builder 传递给 k 最近邻 (kNN) 向量搜索 API,并提供查询文本和用于创建嵌入的模型。
response = client.search(index='openai-movie-embeddings', size=3,knn={"field": "plot_embedding","query_vector_builder": {"text_embedding": {"model_id": "my_openai_embedding_model","model_text": "Fighting movie"}},"k": 10,"num_candidates": 100}
)for hit in response['hits']['hits']:doc_id = hit['_id']score = hit['_score']title = hit['_source']['title']plot = hit['_source']['plot']print(f"Score: {score}\nTitle: {title}\nPlot: {plot}\n")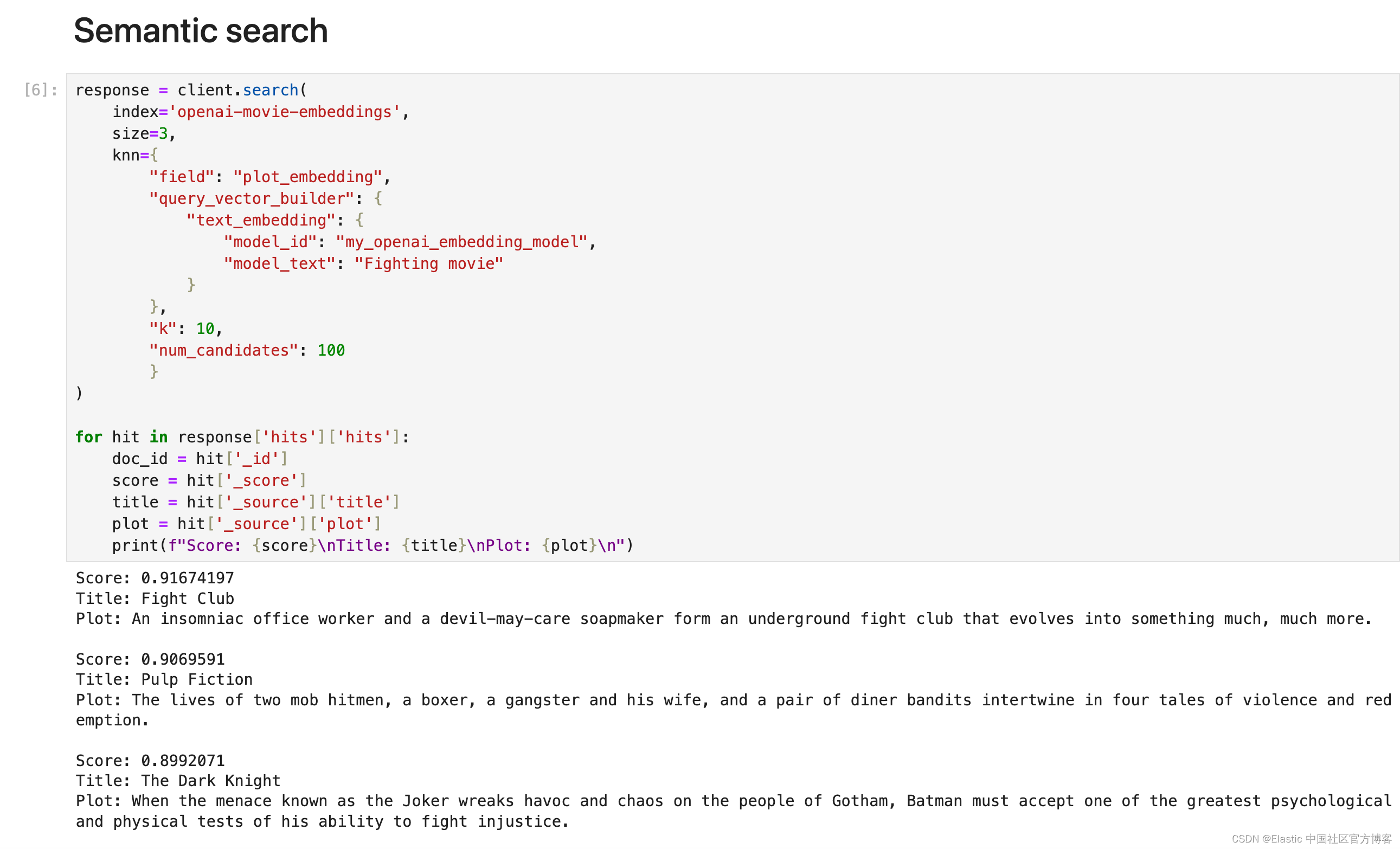
最终源码可以在地址下载:https://github.com/liu-xiao-guo/semantic_search_es/blob/main/semantic_search_using_the_inference_API.ipynb
这篇关于Elasticsearch:使用 Inference API 进行语义搜索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






