本文主要是介绍Tensorflow实现人马图片的分类器 [使用ImageDataGenerator 无需人为标注数据],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验环境: goolge colab (改为本地使用也非常的简单,只需将测试部分稍作修改即可)
初始环境:
tmp文件下为空
content文件下只有sample_data文件

步骤
(1):下载人马数据集的训练集压缩包和验证集压缩包,放在
/tmp/horse-or-human.zip
/tmp/validation-horse-or-human.zip
!wget --no-check-certificate \https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip \-O /tmp/horse-or-human.zip
!wget --no-check-certificate \https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip \-O /tmp/validation-horse-or-human.zip

(2)解压压缩包
训练数据放在/tmp/horse-or-human
验证数据放在/tmp/validation-horse-or-human
import os
import zipfilelocal_zip = '/tmp/horse-or-human.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/horse-or-human')
local_zip = '/tmp/validation-horse-or-human.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/validation-horse-or-human')
zip_ref.close()
(3) 定义训练数据和验证数据中人马图片的路径
# Directory with our training horse pictures
train_horse_dir = os.path.join('/tmp/horse-or-human/horses')# Directory with our training human pictures
train_human_dir = os.path.join('/tmp/horse-or-human/humans')# Directory with our training horse pictures
validation_horse_dir = os.path.join('/tmp/validation-horse-or-human/horses')# Directory with our training human pictures
validation_human_dir = os.path.join('/tmp/validation-horse-or-human/humans')
(4)输出各种路径中的前10个文件名
train_horse_names = os.listdir(train_horse_dir)
print(train_horse_names[:10])train_human_names = os.listdir(train_human_dir)
print(train_human_names[:10])validation_horse_hames = os.listdir(validation_horse_dir)
print(validation_horse_hames[:10])validation_human_names = os.listdir(validation_human_dir)
print(validation_human_names[:10])

(5)输出各个路径下图片的数目。训练数据一共1027张图片,验证数据一共256张图片。
print('total training horse images:', len(os.listdir(train_horse_dir)))
print('total training human images:', len(os.listdir(train_human_dir)))
print('total validation horse images:', len(os.listdir(validation_horse_dir)))
print('total validation human images:', len(os.listdir(validation_human_dir)))

(6)显示出8张马和人的图片
%matplotlib inlineimport matplotlib.pyplot as plt
import matplotlib.image as mpimg# Parameters for our graph; we'll output images in a 4x4 configuration
nrows = 4
ncols = 4# Index for iterating over images
pic_index = 0# Set up matplotlib fig, and size it to fit 4x4 pics
fig = plt.gcf()
fig.set_size_inches(ncols * 4, nrows * 4)pic_index += 8
next_horse_pix = [os.path.join(train_horse_dir, fname) for fname in train_horse_names[pic_index-8:pic_index]]
next_human_pix = [os.path.join(train_human_dir, fname) for fname in train_human_names[pic_index-8:pic_index]]for i, img_path in enumerate(next_horse_pix+next_human_pix):# Set up subplot; subplot indices start at 1sp = plt.subplot(nrows, ncols, i + 1)sp.axis('Off') # Don't show axes (or gridlines)img = mpimg.imread(img_path)plt.imshow(img)plt.show()

(7)定义网络模型,我们使用5个卷积层+平铺层+全连接层+输出层
其中,我们设置输入的格式为input_shape=(300,300,3),即输入是大小为300x300的彩色图片
import tensorflow as tfmodel = tf.keras.models.Sequential([# Note the input shape is the desired size of the image 300x300 with 3 bytes color# This is the first convolutiontf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(300, 300, 3)),tf.keras.layers.MaxPooling2D(2, 2),# The second convolutiontf.keras.layers.Conv2D(32, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),# The third convolutiontf.keras.layers.Conv2D(64, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),# The fourth convolutiontf.keras.layers.Conv2D(64, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),# The fifth convolutiontf.keras.layers.Conv2D(64, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),# Flatten the results to feed into a DNNtf.keras.layers.Flatten(),# 512 neuron hidden layertf.keras.layers.Dense(512, activation='relu'),# Only 1 output neuron. It will contain a value from 0-1 where 0 for 1 class ('horses') and 1 for the other ('humans')tf.keras.layers.Dense(1, activation='sigmoid')
])
(8)输出网络结构的摘要信息
model.summary()

(9)设置网络的编译环境,损失函数,优化器,计算指标。。。
from tensorflow.keras.optimizers import RMSpropmodel.compile(loss='binary_crossentropy',optimizer=RMSprop(lr=0.001),metrics=['acc'])
(10)预处理数据集
注意:
1:第一个目录参数值为训练集或验证集的根目录,其中包括不同类型数据的子目录
2:batch_size设置的值要记住,后面会用到
from tensorflow.keras.preprocessing.image import ImageDataGenerator# 将图片像素值归一化,[0,255]->[0,1]
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)# 训练集生成器
train_generator = train_datagen.flow_from_directory('/tmp/horse-or-human/', #训练数据的根目录,其中包括两个子目录,因为人和马都是训练数据target_size=(300, 300), # 调整图片的大小为300x300batch_size=128,#训练更新时,每一批次的图片数目为128# 因为只有两类,所以我们使用0,1标签标记数据。生成去会将每一个子目录下的图片标记为同一种标签,第一个子目录下标记为0,第二个标记为1class_mode='binary')#验证集生成器,同理
# Flow training images in batches of 128 using train_datagen generator
validation_generator = validation_datagen.flow_from_directory('/tmp/validation-horse-or-human/', # This is the source directory for training imagestarget_size=(300, 300), # All images will be resized to 150x150batch_size=32,# Since we use binary_crossentropy loss, we need binary labelsclass_mode='binary')

(11)训练模型
不在使用model.fit() 而是使用 model.fit_generator()
history = model.fit_generator(train_generator,#训练集生成器steps_per_epoch=8, #训练集每次完全迭代需要多少批次 1027/128=8epochs=15, #迭代次数verbose=1, #每次迭代后都进行验证validation_data = validation_generator,#验证集生成器validation_steps=8 #验证集每次完全迭代需要多少批次 256/32=8
)

(12)测试
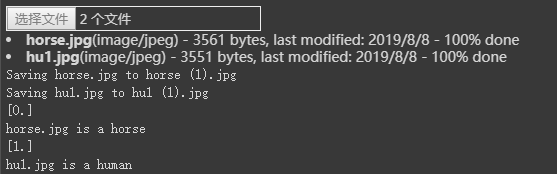
上传一些图片到 /content目录下,进行测试,每次可以处理10张图片
import numpy as np
from google.colab import files
from keras.preprocessing import imageuploaded = files.upload()for fn in uploaded.keys():# predicting imagespath = '/content/' + fnimg = image.load_img(path, target_size=(300, 300))x = image.img_to_array(img)x = np.expand_dims(x, axis=0)images = np.vstack([x])classes = model.predict(images, batch_size=10)print(classes[0])if classes[0]>0.5:print(fn + " is a human")else:print(fn + " is a horse")

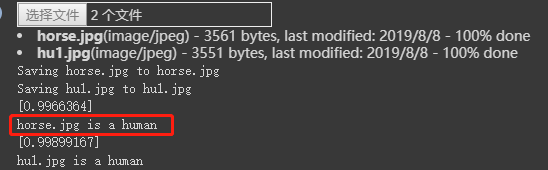
可以看到,模型 错误 的将马的图片分为了人
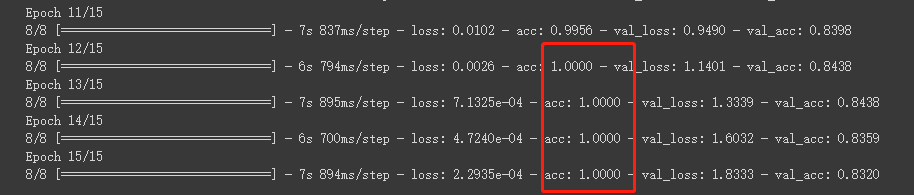
我们再看看之前的训练信息可知,模型在后几轮的训练准确率都是100%,模型很可能陷入了‘过拟合’的状态
(13)优化
我们可以使用 callbacks机制,使得当训练准确率大于 99.9%时停止训练
我们只需在 训练模型 步骤之前,定义和实例化 callbacks对象,并在fit_generator()中加入callbacks参数
class myCallback(tf.keras.callbacks.Callback):def on_epoch_end(self, epoch, logs={}):if(logs.get('acc')>0.999):print("\nReached 99.9% accuracy so cancelling training!")self.model.stop_training = Truecallbacks = myCallback()history = model.fit_generator(train_generator,steps_per_epoch=8, epochs=15,verbose=1,validation_data = validation_generator,validation_steps=8,callbacks=[callbacks]
)
再次训练
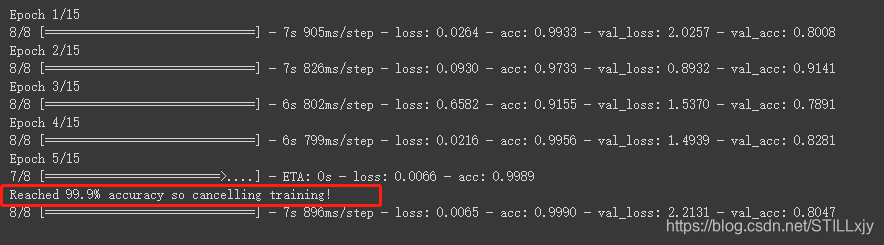
测试:这次就全分类正确了
这篇关于Tensorflow实现人马图片的分类器 [使用ImageDataGenerator 无需人为标注数据]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



