本文主要是介绍[Python] scikit-learn中数据集模块介绍和使用案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
sklearn.datasets模块介绍
在scikit-learn中,可以使用sklearn.datasets模块中的函数来构建数据集。这个模块提供了用于加载和生成数据集的函数。
API Reference — scikit-learn 1.4.0 documentation

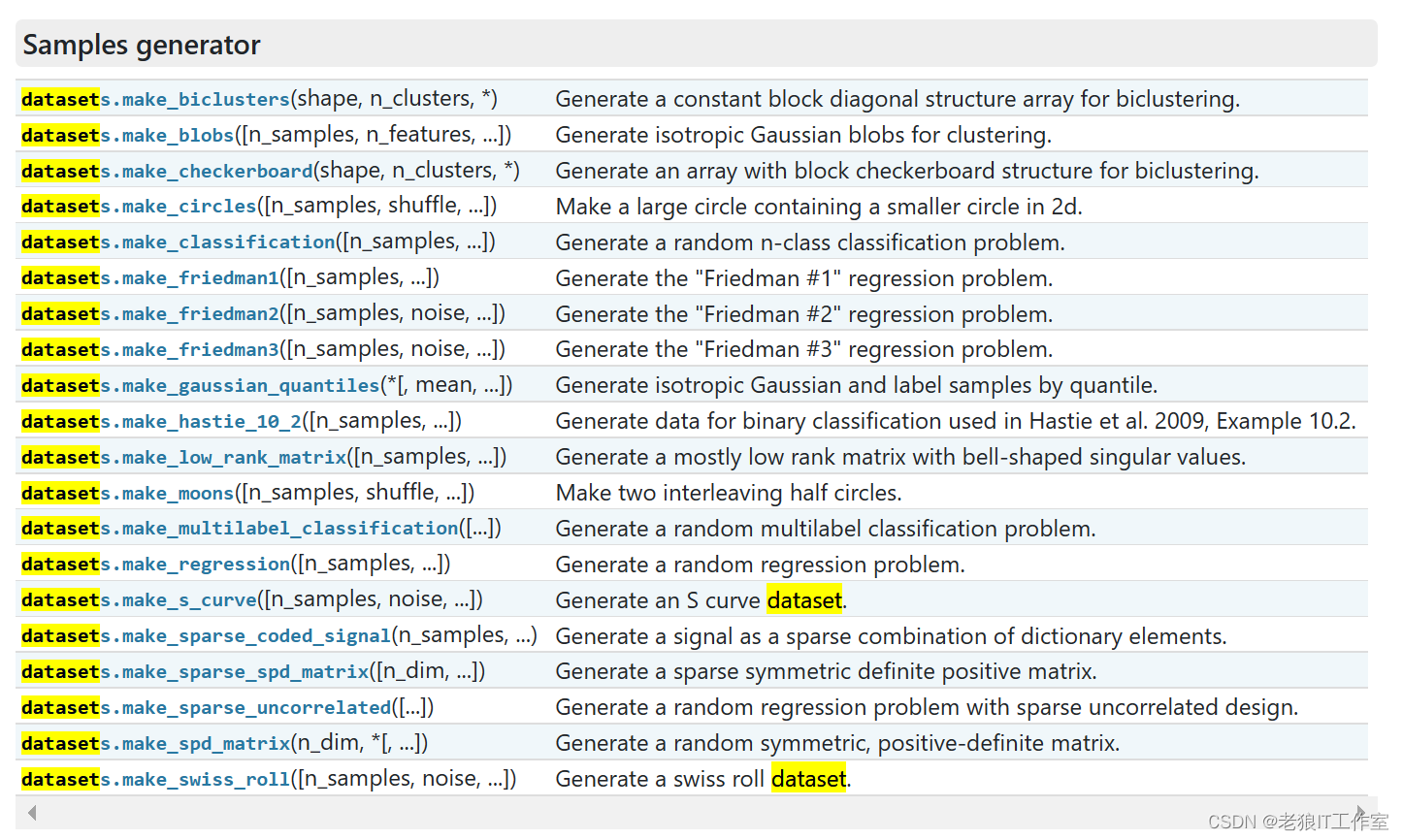
以下是一些常用的sklearn.datasets模块中的函数
load_iris()
sklearn.datasets.load_iris — scikit-learn 1.4.0 documentation
加载鸢尾花数据集,返回一个Bunch对象,包含特征数据和标签。
from sklearn import datasetsiris = datasets.load_iris()
X = iris.data # 特征数据
y = iris.target # 标签load_digits()
sklearn.datasets.load_digits — scikit-learn 1.4.0 documentation
加载手写数字数据集,返回一个Bunch对象,包含特征数据和标签。
from sklearn import datasetsdigits = datasets.load_digits()
X = digits.data # 特征数据
y = digits.target # 标签make_regression()
sklearn.datasets.make_regression — scikit-learn 1.4.0 documentation


生成一个回归问题的合成数据集,可以指定样本数、特征数、噪声等参数。
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=5, n_features=2, noise=1, random_state=42)
X
y
make_classification()
sklearn.datasets.make_classification — scikit-learn 1.4.0 documentation


生成一个分类问题的合成数据集,可以指定样本数、特征数、类别数、噪声等参数。
from sklearn.datasets import make_classification
X, y = make_classification(random_state=42)
print(X.shape)
print(y.shape)
print(list(X[:5]))
print(list(y[:5]))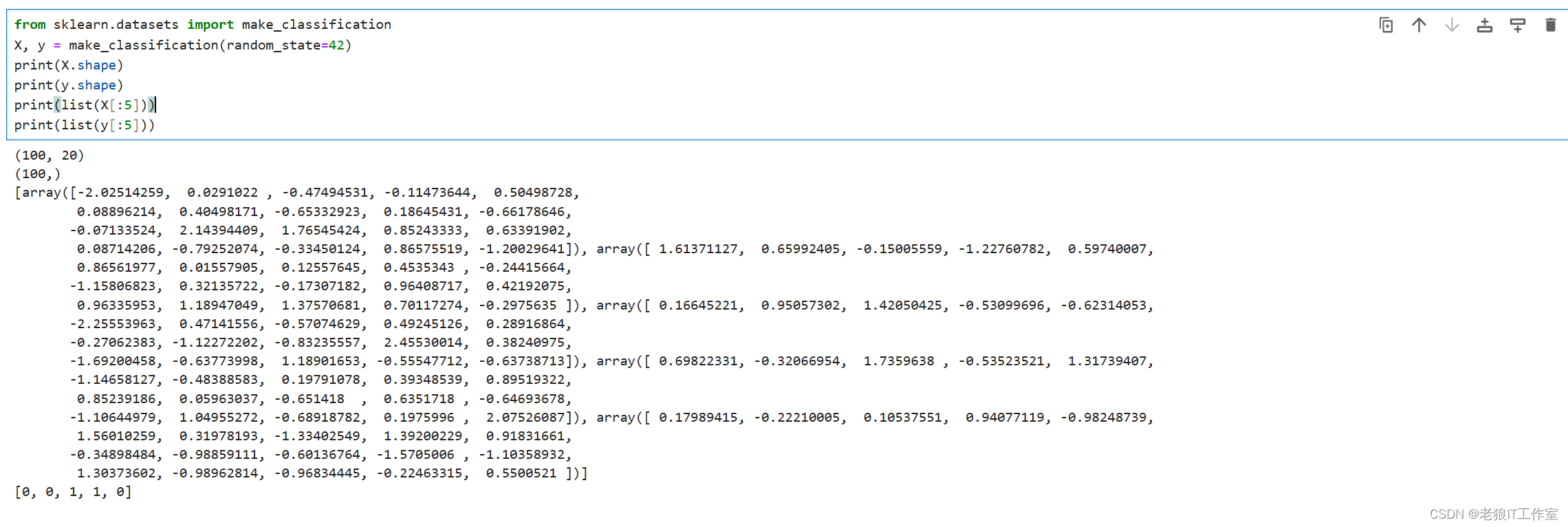
make_blobs()
sklearn.datasets.make_blobs — scikit-learn 1.4.0 documentation

可以用于生成一个多类别的合成数据集。它主要用于聚类算法的演示和测试。
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=10, centers=3, n_features=2,random_state=0)
print(X.shape)
y
X, y = make_blobs(n_samples=[3, 3, 4], centers=None, n_features=2,random_state=0)
print(X.shape)
y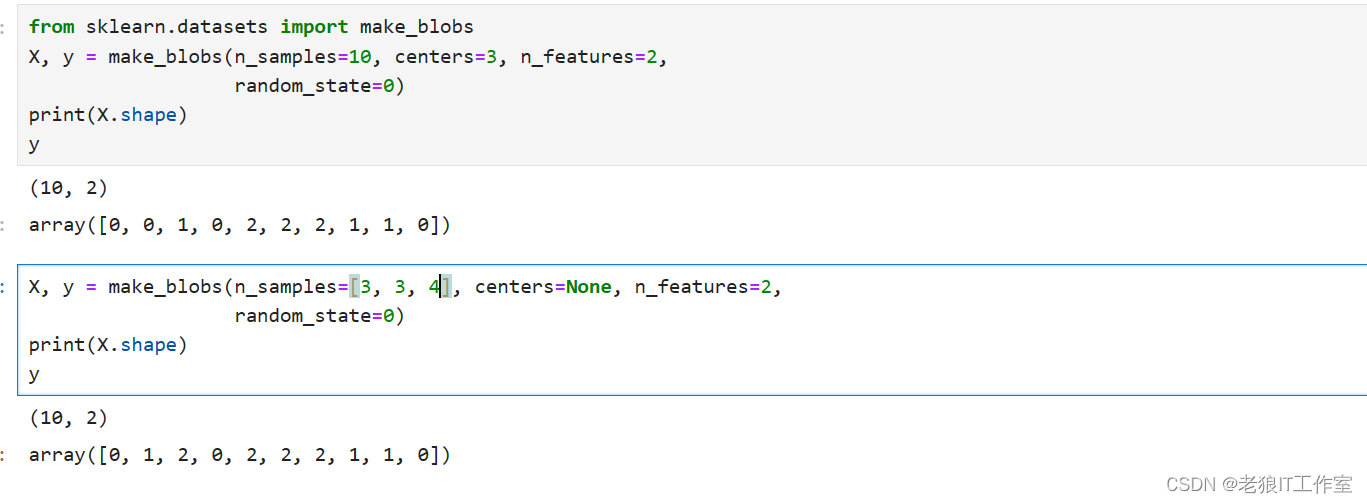
小结
这些函数都会返回一个包含特征数据和标签的Bunch对象,你可以通过访问Bunch对象的属性来获取特征数据和标签。
另外,sklearn.datasets模块还提供了其他一些函数,可以加载和生成其他类型的数据集,例如回归数据集、聚类数据集等。
这篇关于[Python] scikit-learn中数据集模块介绍和使用案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



