本文主要是介绍Python||五城P.M.2.5数据分析与可视化_使用华夫图分析各个城市的情况(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
五城P.M.2.5数据分析与可视化——北京市、上海市、广州市、沈阳市、成都市,使用华夫图分析各个城市的情况
1.北京市的空气质量
2.广州市的空气质量
【上海市和成都市空气质量情况详见下期】
五城P.M.2.5数据分析与可视化——北京市、上海市、广州市、沈阳市、成都市,使用华夫图分析各个城市的情况
1.北京市的空气质量
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pywaffle import Waffle
#读入文件
bj = pd.read_csv('./Beijing.csv')
fig = plt.figure(dpi=100,figsize=(5,5))def good(pm):#优degree = []for i in pm:if 0 < i <= 35:degree.append(i)return degree
def moderate(pm):#良degree = []for i in pm:if 35 < i <= 75:degree.append(i)return degree
def lightlyP(pm):#轻度污染degree = []for i in pm:if 75 < i <= 115:degree.append(i)return degree
def moderatelyP(pm):#中度污染degree = []for i in pm:if 115 < i <= 150:degree.append(i)return degree
def heavilyP(pm):#重度污染degree = []for i in pm:if 150 < i <= 250:degree.append(i)return degree
def severelyP(pm):#严重污染degree = []for i in pm:if 250 < i:degree.append(i)return degree
def PM(bj,str3):bj_dist_pm = bj.loc[:, [str3]]bj_dist1_pm = bj_dist_pm.dropna(axis=0, subset=[str3])bj_dist1_pm = np.array(bj_dist1_pm[str3])bj_good_count = len(good(bj_dist1_pm))bj_moderate_count = len(moderate(bj_dist1_pm))bj_lightlyP_count = len(lightlyP(bj_dist1_pm))bj_moderatelyP_count = len(moderatelyP(bj_dist1_pm))bj_heavilyP_count = len(heavilyP(bj_dist1_pm))bj_severelyP_count = len(severelyP(bj_dist1_pm))a = {'优':bj_good_count,'良':bj_moderate_count,'轻度污染':bj_lightlyP_count,'中度污染':bj_moderatelyP_count,'重度污染':bj_heavilyP_count,'严重污染':bj_severelyP_count}pm = pd.DataFrame(pd.Series(a),columns=['daysum'])pm = pm.reset_index().rename(columns={'index':'level'})return pm
#北京
#PM_Dongsi列
bj_ds = PM(bj,'PM_Dongsi')
PMday_Dongsi = np.array(bj_ds['daysum'])
#PM_Dongsihuan列
bj_dsh = PM(bj,'PM_Dongsihuan')
PMday_Dongsihuan = np.array(bj_dsh['daysum'])
#PM_Nongzhanguan列
bj_nzg = PM(bj,'PM_Nongzhanguan')
PMday_Nongzhanguan = np.array(bj_nzg['daysum'])
bj_pm_daysum = (PMday_Dongsi+PMday_Dongsihuan+PMday_Nongzhanguan)/3
sum = 0
for i in bj_pm_daysum:sum += i
bj_pm_daysum1 = np.array(bj_pm_daysum)data = {'优':int((bj_pm_daysum[0]/sum)*100), '良':int((bj_pm_daysum[1]/sum)*100), '轻度污染': int(bj_pm_daysum[2]/sum*100),'中度污染':int((bj_pm_daysum[3]/sum)*100),'重度污染':int((bj_pm_daysum[4]/sum)*100),'严重污染':int((bj_pm_daysum[5]/sum)*100)}
total = np.sum(list(data.values()))
plt.figure(FigureClass=Waffle,rows = 5, # 列数自动调整values = data,# 设置titletitle = {'label': "北京市污染情况",'loc': 'center','fontdict':{'fontsize': 13,}},labels = ['{} {:.1f}%'.format(k, (v/total*100)) for k, v in data.items()],# 设置标签图例的样式legend = {'loc': 'lower left','bbox_to_anchor': (0, -0.4),'ncol': len(data),'framealpha': 0,'fontsize': 6},dpi=120
)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.show()

北京市总体空气质量差,有约16%的轻度污染,约12%的重度污染和6%的严重污染,中度污染的比例也相对较大,占比约9%。
2.广州市的空气质量
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pywaffle import Waffle
import math
#读入文件
gz = pd.read_csv('./Guangzhou.csv')
fig = plt.figure(dpi=100,figsize=(5,5))def good(pm):#优degree = []for i in pm:if 0 < i <= 35:degree.append(i)return degree
def moderate(pm):#良degree = []for i in pm:if 35 < i <= 75:degree.append(i)return degree
def lightlyP(pm):#轻度污染degree = []for i in pm:if 75 < i <= 115:degree.append(i)return degree
def moderatelyP(pm):#中度污染degree = []for i in pm:if 115 < i <= 150:degree.append(i)return degree
def heavilyP(pm):#重度污染degree = []for i in pm:if 150 < i <= 250:degree.append(i)return degree
def severelyP(pm):#严重污染degree = []for i in pm:if 250 < i:degree.append(i)return degreedef PM(gz,str3):gz_dist_pm = gz.loc[:, [str3]]gz_dist1_pm = gz_dist_pm.dropna(axis=0, subset=[str3])gz_dist1_pm = np.array(gz_dist1_pm[str3])gz_good_count = len(good(gz_dist1_pm))gz_moderate_count = len(moderate(gz_dist1_pm))gz_lightlyP_count = len(lightlyP(gz_dist1_pm))gz_moderatelyP_count = len(moderatelyP(gz_dist1_pm))gz_heavilyP_count = len(heavilyP(gz_dist1_pm))gz_severelyP_count = len(severelyP(gz_dist1_pm))a = {'优':gz_good_count,'良':gz_moderate_count,'轻度污染':gz_lightlyP_count,'中度污染':gz_moderatelyP_count,'重度污染':gz_heavilyP_count,'严重污染':gz_severelyP_count}pm = pd.DataFrame(pd.Series(a),columns=['daysum'])pm = pm.reset_index().rename(columns={'index':'level'})return pm
#广州
#PM_City Station列
gz_cs = PM(gz,'PM_City Station')
PMday_CityStation = np.array(gz_cs['daysum'])
#PM_5th Middle School列
gz_ms = PM(gz,'PM_5th Middle School')
PMday_5thMiddleSchool = np.array(gz_ms['daysum'])
gz_pm_daysum = (PMday_CityStation+PMday_5thMiddleSchool)/2
sum = 0
for i in gz_pm_daysum:sum += i
gz_pm_daysum1 = np.array(gz_pm_daysum)data = {'优':int((gz_pm_daysum[0]/sum)*100), '良':int((gz_pm_daysum[1]/sum)*100), '轻度污染': int(gz_pm_daysum[2]/sum*100),'中度污染':int((gz_pm_daysum[3]/sum)*100),'重度污染':int((gz_pm_daysum[4]/sum)*100),'严重污染':int((gz_pm_daysum[5]/sum)*100)}
total = np.sum(list(data.values()))
plt.figure(FigureClass=Waffle,rows = 5, # 列数自动调整values = data,# 设置titletitle = {'label': "广州市污染情况",'loc': 'center','fontdict':{'fontsize': 13,}},labels = ['{} {:.1f}%'.format(k, (v/total*100)) for k, v in data.items()],# 设置标签图例的样式legend = {'loc': 'lower left','bbox_to_anchor': (0, -0.4),'ncol': len(data),'framealpha': 0,'fontsize': 6},dpi=120
)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.show()
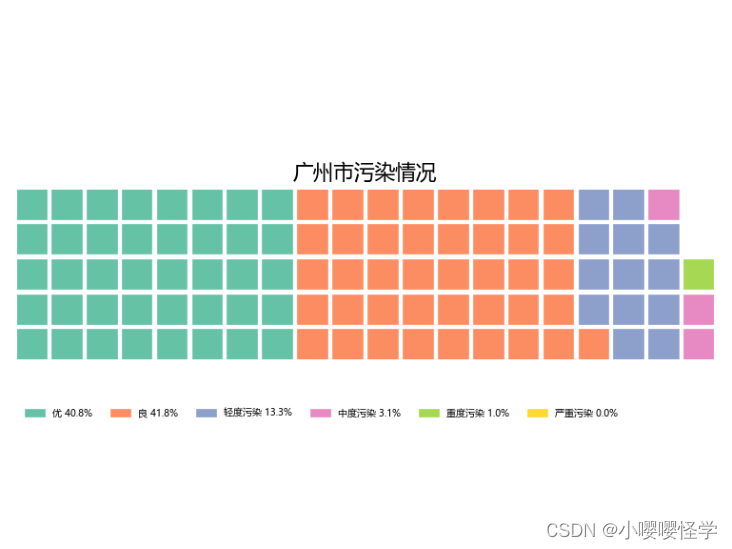 广州市总体空气质量优秀,优和良的空气质量占比超过80%,严重污染的天气情况少之甚少,污染天气——轻度污染、中度污染、重度污染和严重污染占比总和不超过20%。
广州市总体空气质量优秀,优和良的空气质量占比超过80%,严重污染的天气情况少之甚少,污染天气——轻度污染、中度污染、重度污染和严重污染占比总和不超过20%。
【上海市和成都市空气质量情况详见下期】
这篇关于Python||五城P.M.2.5数据分析与可视化_使用华夫图分析各个城市的情况(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





