本文主要是介绍K8s 集群可观测性-数据分流最佳实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
在微服务架构下,一个 k8s 集群中经常会部署多套业务,同时也意味着不同团队、不同角色、不同的业务会在同一集群中,需要将不同业务的数据在不同的空间进行管理和查看。
在传统的主机环境下,这个是可以通过不同的主机部署 DataKit 时配置不同的工作空间 token 轻松实现,但是在 k8s 环境下使用 DaemonSet 方式部署,同一个 DaemonSet 无法灵活的进行多套 DataKit 配置,且在配置变更时需要重启 DataKit,当 DataKit 达到一定规模影响非常大。
因此,观测云提供的 DataWay Sinker 功能,便成为了以上问题的最佳解决方案。
方案介绍
方案流程
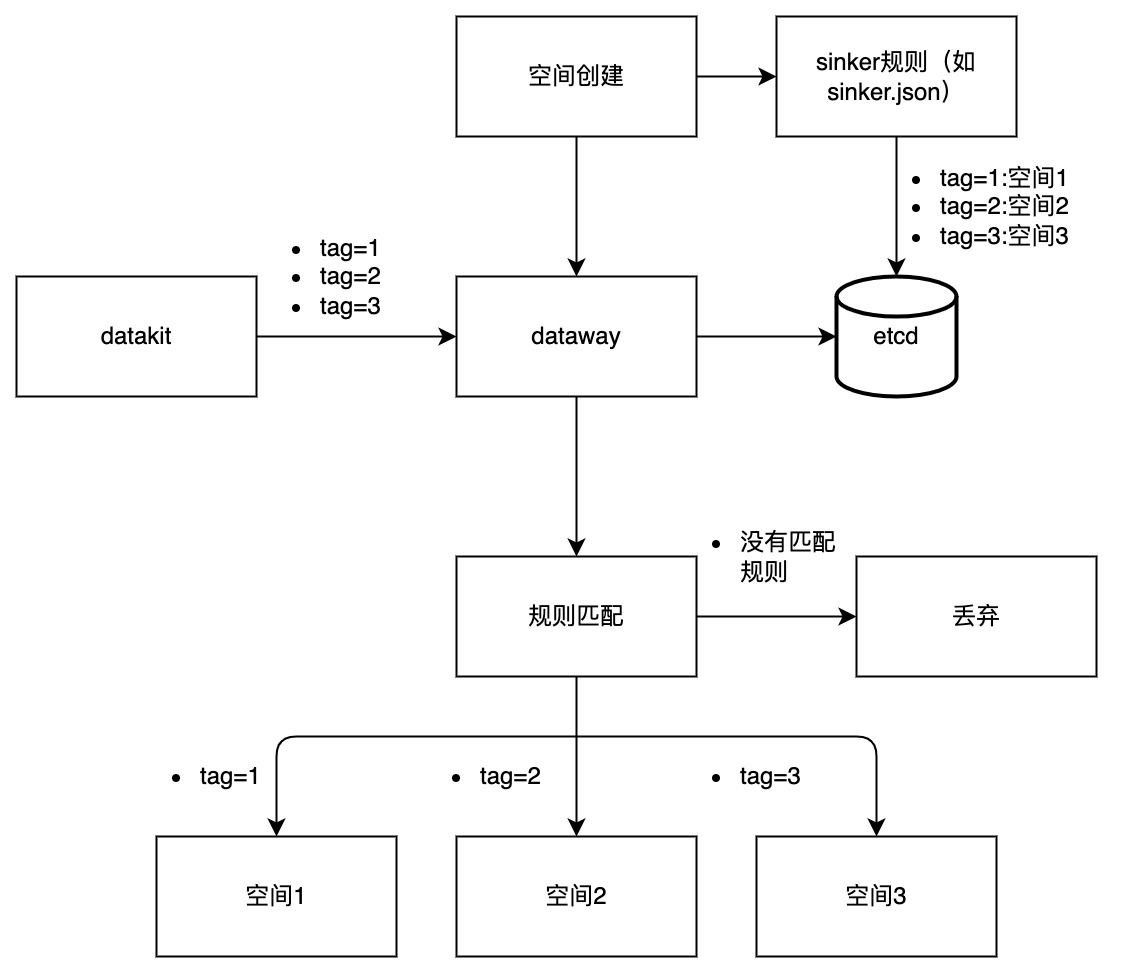
通过上图不难看出,该方案最重要的部分在于进行数据 TAG(标签)管理。数据分流是否达到预期、是否准确、是否实用都取决于 TAG 标签的合理使用以及规划管理。而 TAG 的管理和使用恰好是观测云平台的核心能力之一。
关于如何 TAG 的更多介绍,可以参考《TAG 在观测云中的最佳实践》,在此不再赘述。
除此以外,还支持以下属性进行分流:
- 观测云内置自定义 key,例如:category 针对所有常规数据分类,其取值为对应数据分类的「名称」列(如时序是 metric,对象为 object 等)
- 对象 label 属性以及 k8s 集群的自带属性,例如:
namespace,container_name等
方案实践
下面将从实际案例出发,演示如何通过 DataWay Sinker 功能实现数据的分流以及管理。
在本文中,将按照常用的业务属性 namespace 将数据划分到不同的工作空间。
前提条件,集群中已经部署了观测云 DataKit 采集器。
实践背景
在测试集群中,存在多个 namespace,如下图:

并且使用观测云 DataKit 进行 k8s 集群指标监控,但是所有的监控指标都在一个工作空间 OBS 中,如下图:
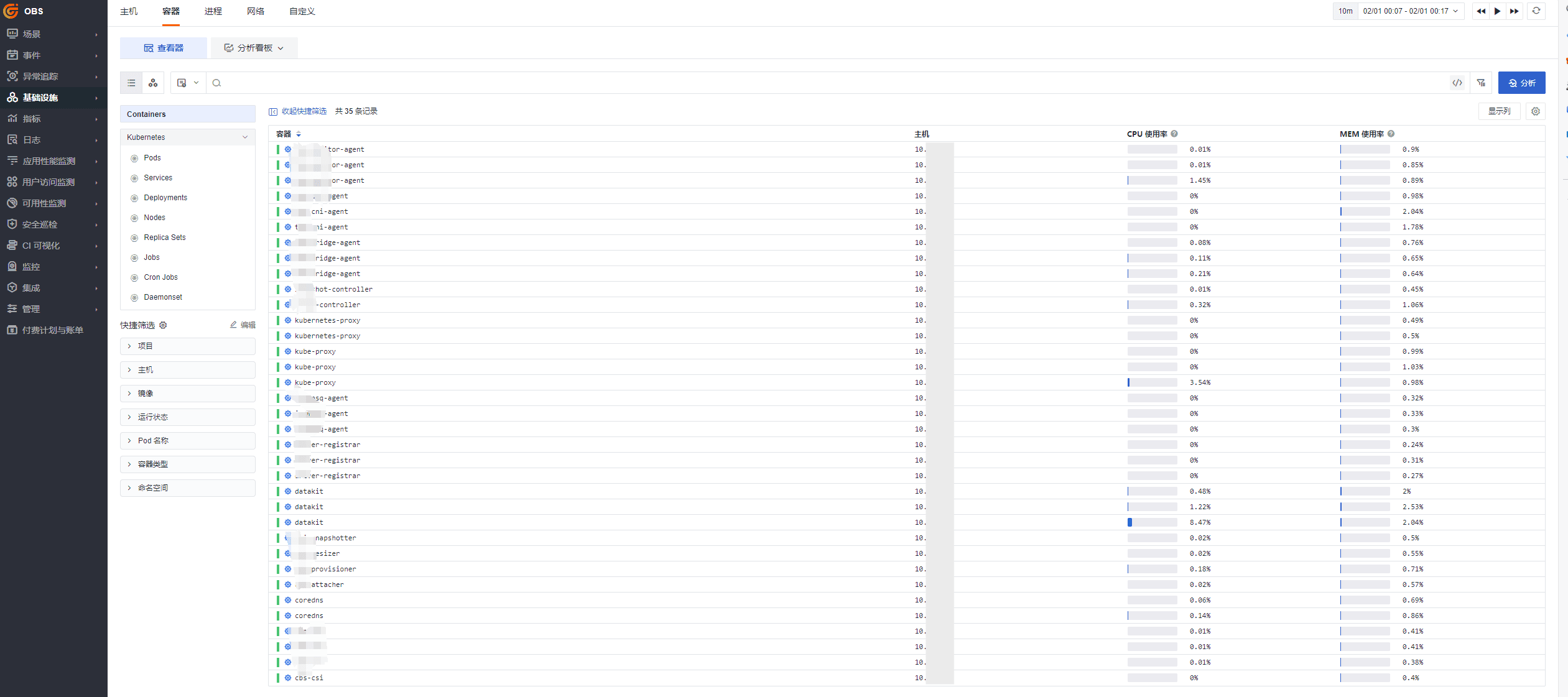
希望达到效果:根据不同的 namespace 将监控数据分流至不同的工作空间,如 namespace=datakit 的所有数据分流至观测云 datakit 工作空间。
步骤一:安装 Dataway
对于 SaaS 用户而言,可以在自己本地(k8s Cluster)部署一个 Dataway,专用于分流,然后再将数据转发给 Openway。
1)参考 Dataway 安装文档,安装 dataway ;
2)修改 dataway.yaml ,添加如下 Sinker 相关配置环境变量;
- name: DW_SECRET_TOKEN # 当开启数据分流功能时,用于与DataKit进行链接,注意tkn_后面需添加32位字符串value: "tkn_yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy"
- name: DW_CASCADED # 当开启数据分流功能时,SaaS用户使用级联方式链接value: "on"
- name: DW_SINKER_FILE_PATH # 挂载的sinker.json文件地址value: "/usr/local/cloudcare/dataflux/dataway/sinker.json"
- name: DW_REMOTE_HOST # 配置级联地址value: "https://openway.guance.com"
这里使用的是文件的方式配置分流规则,同时支持 etcd 进行配置,具体配置可以参考 Dataway 配置 。
3)部署 dataway。
步骤二:编辑分流规则
创建文件 sinker.json ,填写如下内容,并将文件挂载至 dataway 容器中。
{"strict":true,"rules": [{"rules": ["{ namespace = 'utils'}" # 匹配规则],# 对应工作空间的openway地址及token"url": "https://openway.guance.com?token=tkn_cb1a9a53fcb04436a4adab6435327fca" },{"rules": ["{ namespace = 'datakit' }"],"url": "https://openway.guance.com?token=tkn_c6e8ae1bbfa2489aba843cc56baf3c66"},{"rules": ["{ namespace != 'datakit',namespace!='utils' }"],"url": "https://openway.guance.com?token=tkn_1618f90ef13b482d9f682f30f7118d2f"}]
}
步骤三:修改 DataKit 配置
1)修改 DataKit 分流环境变量配置;
- name: ENV_DATAWAY # 步骤一中Dataway地址和SECRET_TOKENvalue: http://10.16.253.114:9528?token=tkn_yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy- name: ENV_SINKER_GLOBAL_CUSTOMER_KEYS # 指定分流的keyvalue: namespace- name: ENV_DATAWAY_ENABLE_SINKER # 开启分流value: "true"
2)重新部署 DataKit 。
最终效果
- datakit 工作空间中只有 namespace 为 datakit 的数据
- utils 工作空间中只有 namespace 为 utils 的数据
- OBS 工作空间中没有 utils 和 datakit 数据

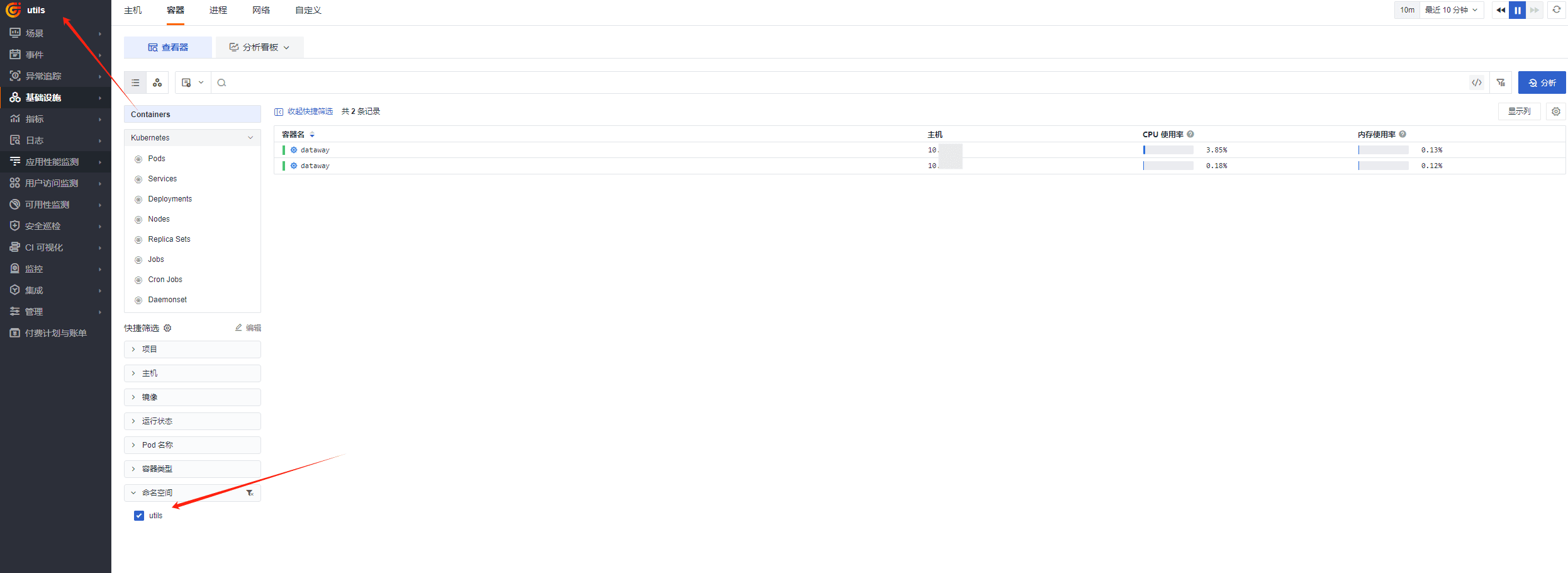
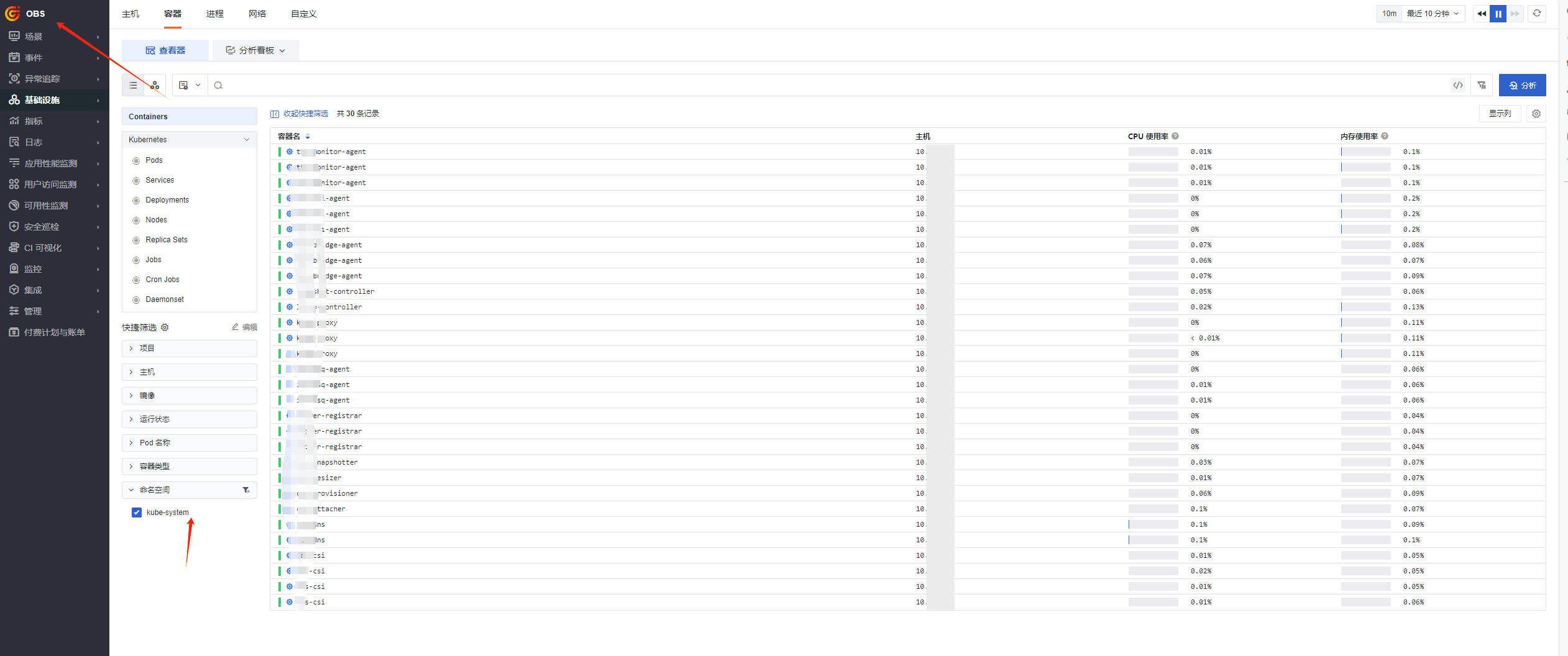
至此,分流成功。
总结
除以上的例子外,也可以利用 Datakit 内置的自定义 Key,它们一般不会出现在采集的数据中,但 Datakit 可以以这些 Key 来对数据进行分组。如果在这些 Key 的维度有分流的需求,可以将它们添加到「全局自定义 Key」列表中(这些 Key 默认都不配置)。我们可以使用内置一些自定义 Key 来实现数据分流。具体分流规则可以参考内置自定义 key 分流 。
这篇关于K8s 集群可观测性-数据分流最佳实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






