本文主要是介绍商汤科技2020数据分析师0820笔试题目整理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2019年8月19日
问答题1:缺失值数据预处理有哪些方法?https://juejin.im/post/5b5c4e6c6fb9a04f90791e0c
处理缺失值的方法如下:删除记录,数据填补和不处理。主要以数据填补为主。
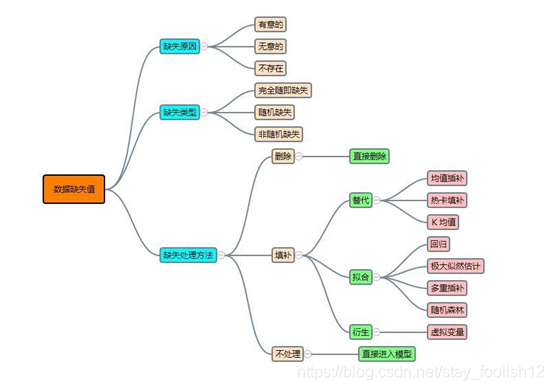
1 删除记录:该种方法在样本数据量十分大且确实值不多的情况下非常有效。
2 数据填补:插补大体有替换缺失值,拟合缺失值,虚拟变量等操作。替换是通过数据中非缺失数据的相似性来填补,其中的核心思想是发现相同群体的共同特征,拟合是通过其他特征建模来填补,虚拟变量是衍生的新变量代替缺失值。
替换缺失值:
1 定类数据:众数填补
2定量(定比)数据: 平均数或中位数填补
3 热卡填补: 热卡填充法是在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。
4 k最近距离邻法(k-means cluster)
通过无监督机器学习的k均值聚类的方法将所有样本进行聚类划分,然后在通过划分的种类的均值对各自类中的缺失值进行填补。本质是通过找相似来填补缺失值。
拟合缺失值
如果缺失的变量跟其他特征变量相关,则通过建模预测的缺失值就有意义,反之则不用
回归预测:
基于完整的数据集,建立回归方程。对于有缺失值的特征值,将已知的特征值代入模型来估计未知特征值,一次估计值来进行填充。(该方法适合缺失值是连续的,即定量的类型,才可以使用回归来预测。)
极大似然估计:
在随机类型为随机缺失的条件下,假设模型对于完整的样本是正确的,那么通过观测数据的边际分布可以对未知参数进行极大似然估计。(该方法适合大样本)
多重插补:
多重插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的额噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
根据数据缺失机制、模式以及变量类型,可分别采用回归、预测均数匹配( predictive mean matching, PMM )、趋势得分( propensity score, PS )、Logistic回归、判别分析以及马尔可夫链蒙特卡罗( Markov Chain Monte Carlo, MCMC) 等不同的方法进行填补。
注:使用多重插补要求数据缺失值为随机性缺失,一般重复次数20-50次精准度很高,但是计算也很复杂,需要大量计算。
随机森林:
虚拟变量
虚拟变量其实就是缺失值的一种衍生变量,。具体做法是通过判断特征值是否有缺失值来定义一个新的二分类变量。
不处理
在希望保持原始信息不发生变化的前提下对信息系统进行处理
问答题2中心极限定理是什么?他的应用方向是:
中心极限定理就是研究随机变量和的极限分布在什么条件下为正态分布的问题。
(1)独立同分布的中心极限定理[林德伯格-列维(Lindburg-Levy)定理]
应用一:求随机变量之和Sn落在某区间的概率。
应用二:已知随机变量之和Sn取值的概率,求随机变量的个数n。
(2)棣莫佛-拉普拉斯(de Movire - Laplace)定理
应用一:近似计算服从二项分布的随机变量在某范围内取值的概率
应用二:已知服从二项分布的随机变量在某范围内取值的概率,估计该范围(或该范围的最大值)。
应用三:与用频率估计概率有关的二项分布的近似计算
(3)李雅普诺夫定理
问答题3:
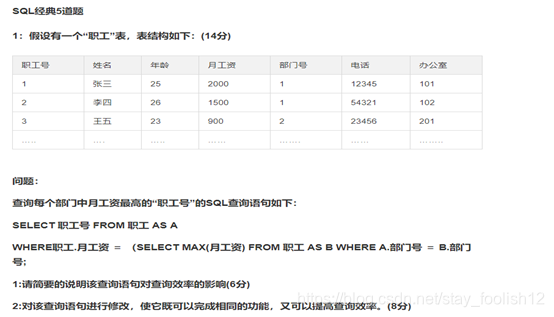
1 对于外层职工关系 A 中的每一个记录,都要对内层职工关系B进行检索,所有效率不高
2.(1)使用临时表
SELECT MAX(月工资) as 最高工资,部门号 INTO temp FROM 职工
GROUP BY 部门号;
SELECT 职工号 FROM 职工,temp WHERE 月工资=最高工资
AND 职工.部门号 = temp.部门号;
(2) SELECT 职工号 FROM 职工,(SELECT MAX(月工资) as 最高工资,部门号 FROM 职工 GROUP BY 部门号) as DEPMAX
WHERE 月工资=最高工资 AND 职工.部门号 = DEPMAX. 部门号;
SQL经典5道
https://cloud.tencent.com/developer/article/1062773
 v
v


这篇关于商汤科技2020数据分析师0820笔试题目整理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





